AMINA
收藏AMINA Newspaper Articles Dataset
概述
AMINA 是一个综合性的阿拉伯语多用途新闻文章数据集,收集自多个知名新闻源。该数据集旨在促进自然语言处理和新闻学研究等领域的发展。
数据来源
数据集包含以下新闻机构的文章:
- Youm7
- BBC
- CNN
- RT
- Elsharq
- ElRai
- Elspahe
- Hespress
下载和使用
可以使用以下代码片段下载和使用数据集:
python from datasets import load_dataset
BBC articles
bbc = load_dataset("MohamedZayton/AMINA", data_files="BBC/BBC.csv")
CNN articles
cnn = load_dataset("MohamedZayton/AMINA", data_files="CNN/CNN.csv")
RT articles
rt = load_dataset("MohamedZayton/AMINA", data_files="RT/RT.csv")
Youm7 articles
youm_7 = load_dataset("MohamedZayton/AMINA", data_files="Youm7/Youm7.csv")
Hespress articles
hespress = load_dataset("MohamedZayton/AMINA", data_files="Hespress/Hespress.csv")
Elspahe articles
elspahe = load_dataset("MohamedZayton/AMINA", data_files="Elspahe/Elspahe.csv")
ElRai articles by category
elrai = load_dataset("MohamedZayton/AMINA", data_files="ElRai/*.csv")
ElSharq articles by category
elsharq = load_dataset("MohamedZayton/AMINA", data_files="ElSharq/*.csv")
图片链接
部分文章的图片可以从以下链接获取: Youm7 和 Elsharq 报纸文章图片
新闻栏目属性
以下是各新闻机构文章的栏目属性:
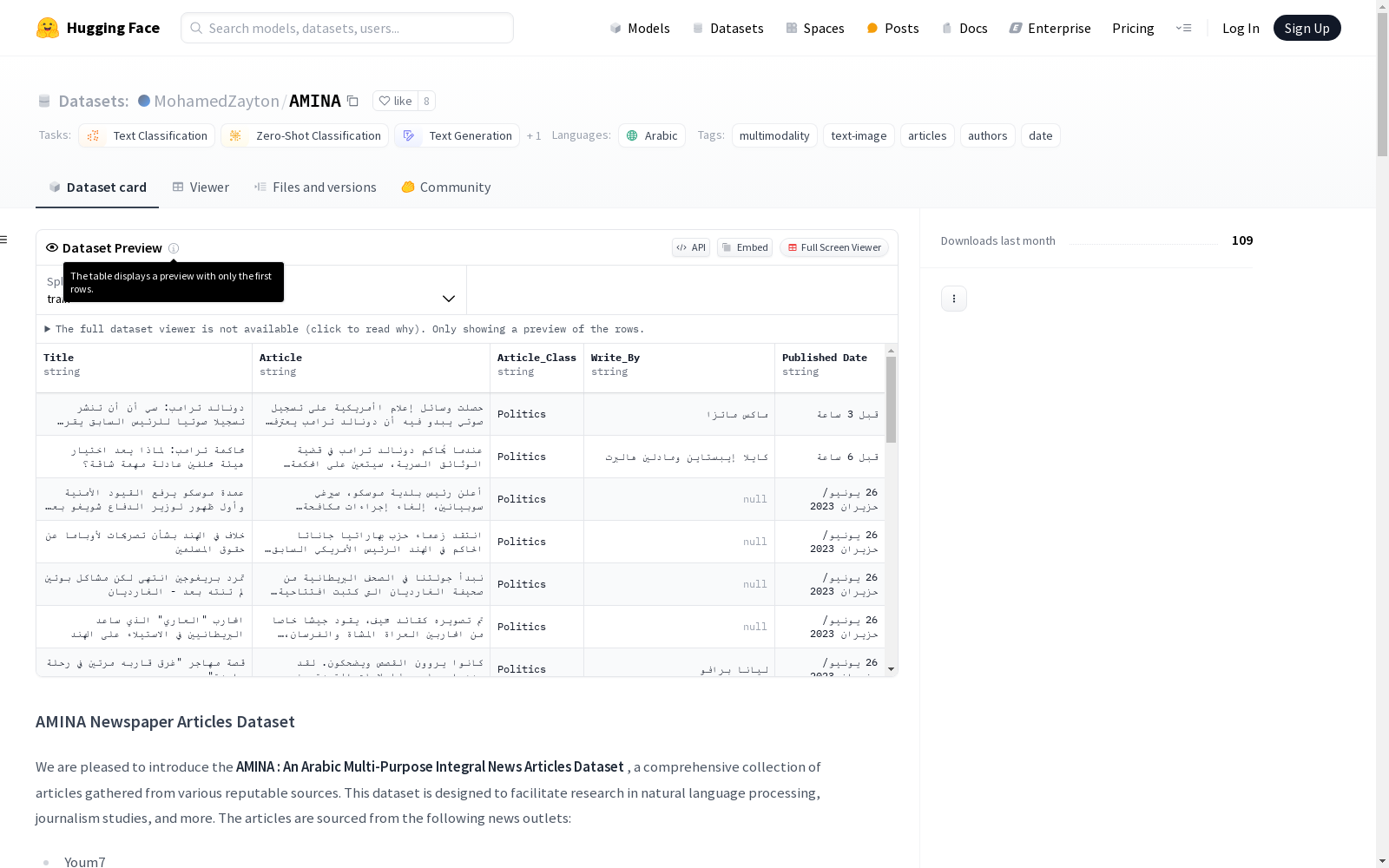
BBC
- Title: 文章标题
- Article: 文章内容
- Article_Class: 文章分类
- Write_By: 作者
- Published Date: 发布日期
CNN
- Title: 文章标题
- Article: 文章内容
- Article_Class: 文章分类
- Published Date: 发布日期
- Updated Date: 更新日期
RT
- Title: 文章标题
- Article: 文章内容
- Article_Class: 文章分类
- Write_By: 作者
- Published Date: 发布日期
Youm7
- Title: 文章标题
- Article: 文章内容
- Article_Class: 文章分类
- Write_By: 作者
- Published Date: 发布日期
- Image_id: 图片唯一标识
- Caption: 图片描述
Hespress
- Title: 文章标题
- Article: 文章内容
- Article_Class: 文章分类
- Write_By: 作者
- Date: 发布日期
Elspahe
- Title: 文章标题
- Article: 文章内容
- Atrical_Class: 文章分类
- Date: 发布日期
Elrai
- Title: 文章标题
- Content: 文章内容
- Image_path: 图片路径
- Source: 文章来源
- Views: 浏览量
- Publishing_date: 发布日期
- Category: 文章分类
Elsharq
- Title: 文章标题
- Body: 文章内容
- Image Url: 图片URL
- Image Caption: 图片描述
- Tags: 关键词
- Tag-source: 标签来源
- Views: 浏览量
- Date: 发布日期
- Time: 发布时间
- Inner Class: 内部分类
- Class: 主要分类