Light-R1-SFTData 和 Light-R1-DPOData
收藏github2025-03-11 更新2025-03-05 收录
下载链接:
https://github.com/Qihoo360/Light-R1
下载链接
链接失效反馈官方服务:
资源简介:
这些数据集用于Light-R1-32B模型的训练,包括Curriculum SFT和DPO数据集。
These datasets are utilized for the training of the Light-R1-32B model, encompassing the Curriculum SFT and DPO datasets.
创建时间:
2025-03-03
原始信息汇总
Light-R1 数据集概述
模型信息
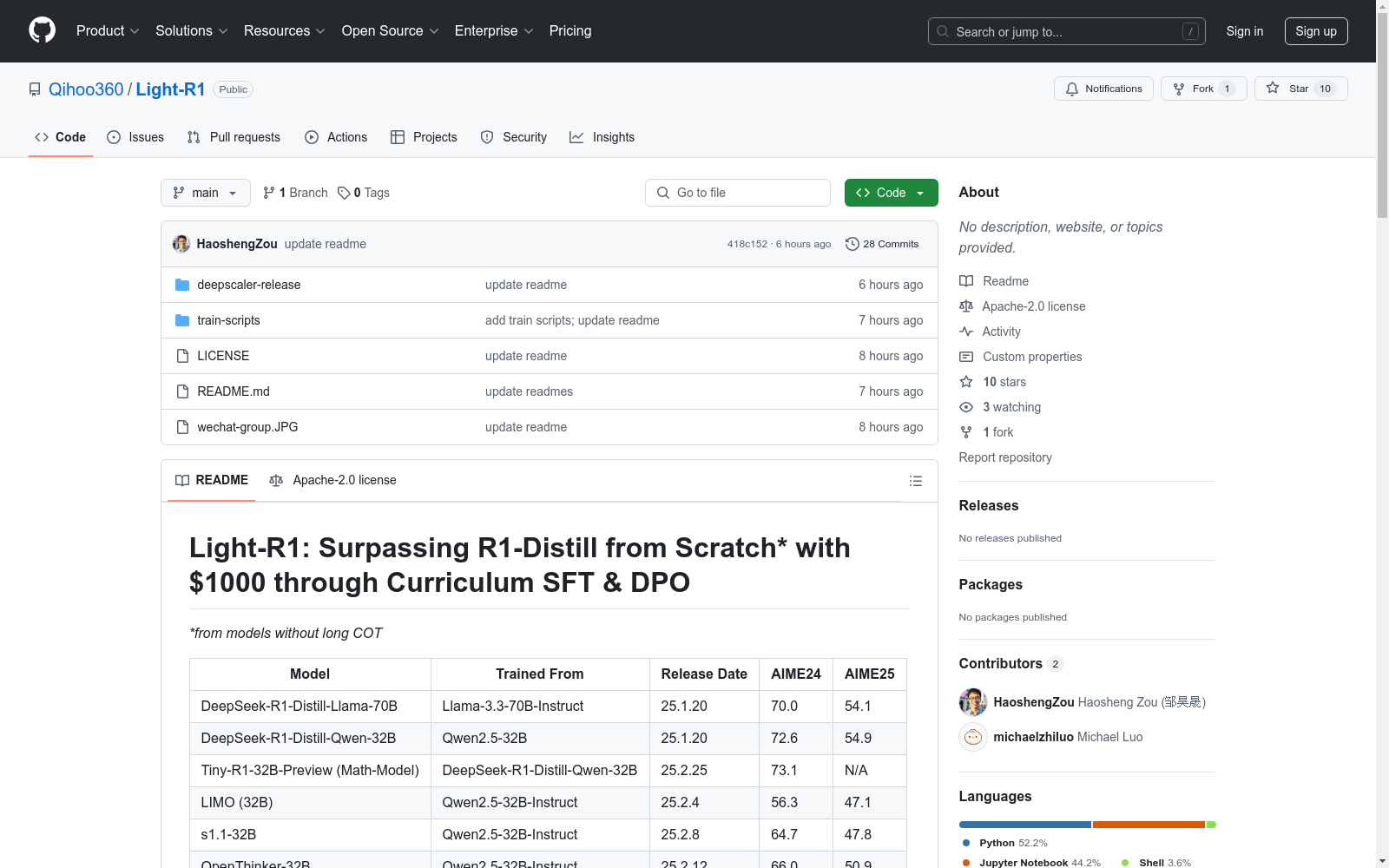
- Light-R1-32B: 从Qwen2.5-32B-Instruct训练而来,AIME24得分76.6,AIME25得分64.6。
- 其他相关模型包括DeepSeek-R1-Distill-Llama-70B、DeepSeek-R1-Distill-Qwen-32B、Tiny-R1-32B-Preview等。
训练细节
- 训练数据来源:包括OpenR1-Math-220k、OpenThoughts-114k、LIMO、OpenMathInstruct-2、s1K-1.1、Omni-MATH、hendrycks_math以及AIME数据集。
- 训练方法:采用课程学习策略,包括SFT(Soft prompts Fine-tuning)和DPO(Data Program Optimization)。
- 训练时间:估计在12台H800机器上不超过6小时。
数据集与工具
- 数据集:发布Curriculum SFT和DPO的数据集。
- 训练脚本:基于360-LLaMA-Factory的训练脚本。
- 评估代码:基于DeepScaleR的评估代码。
性能比较
- 与DeepSeek-R1-Distill-Qwen-32B相比,在AIME24和AIME25上取得了更好的成绩。
版权与致谢
- 所有发布材料遵循Apache 2.0开源许可证。
- 训练实验由360-LLaMA-Factory提供支持,评估脚本基于DeepScaleR。
- Light-R1-32B基于Qwen2.5-32B-Instruct训练。
引用
bibtex @misc{lightr1proj, title={Light-R1: Surpassing R1-Distill from Scratch with $1000 through Curriculum SFT & DPO}, author={Liang Wen, Fenrui Xiao, Xin He, Yunke Cai, Qi An, Zhenyu Duan, Yimin Du, Junchen Liu, Lifu Tang, Xiaowei Lv, Haosheng Zou, Yongchao Deng, Shousheng Jia, Xiangzheng Zhang}, year={2025}, eprint={}, archivePrefix={}, url={https://github.com/Qihoo360/Light-R1}, }
搜集汇总
数据集介绍
构建方式
Light-R1-32B数据集的构建,始于Qwen2.5-32B-Instruct模型,采用课程学习策略,通过SFT(Soft Prompt Tuning)和DPO(Data Programming with Negative Contrastive Alignment)技术进行训练。首先使用SFT对模型进行初步调优,随后通过DPO进一步优化模型性能。数据集的构建过程中,对公开数学数据集进行了筛选和清洗,以确保训练数据的质量和多样性。
使用方法
使用该数据集时,用户可以依据提供的训练脚本和代码,基于360-LLaMA-Factory框架进行模型的训练。同时,数据集的使用者可以根据需要,对模型进行推理和评估,利用提供的评估代码进行性能的量化分析。此外,对于模型的推理,建议使用vLLM或SGLang工具。
背景与挑战
背景概述
Light-R1-SFT & Light-R1-DPO数据集是由Qihoo360团队开发,旨在通过课程学习策略(Curriculum SFT & DPO)从无长上下文模型(from scratch)训练出性能卓越的长上下文模型。该数据集的创建时间为2025年,主要研究人员包括Liang Wen, Fenrui Xiao等。核心研究问题是如何有效地从零开始训练出能够在数学竞赛AIME24 & AIME25中取得优异成绩的长上下文模型。该数据集在相关领域具有重要影响力,为研究长上下文模型提供了新的视角和方法。
当前挑战
该数据集在构建过程中遇到的挑战主要包括:1) 如何在避免数据集污染的前提下,选取和构建适用于训练的数据集;2) 如何在有限的计算资源下,通过课程学习策略实现从零开始训练出高性能的长上下文模型;3) 如何评价和验证模型的性能,确保其在数学竞赛等任务中的表现。此外,该数据集在解决领域问题,如数学题目的理解和生成方面,也面临着如何提高准确性和效率的挑战。
常用场景
经典使用场景
Light-R1-SFT & Light-R1-DPO数据集,旨在通过对数学题目的处理,从无长COT(Context Overlap Trees)的模型中训练出性能卓越的模型。该数据集最经典的使用场景是作为数学题目的训练材料,通过课程学习策略(SFT)和数据增强策略(DPO),提升模型在数学竞赛中的表现,如AIME24和AIME25等。
解决学术问题
该数据集解决了传统模型在处理复杂数学题目时性能不佳的问题。通过精心设计的课程SFT和DPO训练策略,Light-R1-SFT & Light-R1-DPO有效提升了模型在数学领域的能力,特别是在AIME等高难度数学竞赛中的表现,对学术研究在数学模型训练领域具有重大意义。
实际应用
在实际应用中,Light-R1-SFT & Light-R1-DPO数据集可以被用于开发数学教育辅助工具,例如智能数学题库、自动评分系统等。此外,该数据集的成果还可应用于机器学习领域,为模型训练提供高效、经济的策略。
数据集最近研究
最新研究方向
Light-R1-32B数据集的引入,为数学领域模型训练提供了新的视角。该研究通过课程学习策略(SFT&DPO)对模型进行微调,实现了从零开始训练的模型在AIME24和AIME25竞赛中取得了超越先前成果的成绩。此研究不仅关注了模型在数学题目的解答能力,还通过数据去污染和模型合并技术,提高了模型的泛化能力和性能表现,为相关领域的研究提供了新的方法和参考。
以上内容由遇见数据集搜集并总结生成


