wmt24pp
收藏Hugging Face2025-02-18 更新2025-02-19 收录
下载链接:
https://huggingface.co/datasets/google/wmt24pp
下载链接
链接失效反馈官方服务:
资源简介:
WMT24++数据集包含了55种语言对的英语翻译和后期编辑数据,数据来源于不同领域,适用于翻译和语言模型评估。
The WMT24++ Dataset contains English translation and post-editing data for 55 language pairs, with data sourced from diverse domains, and is applicable to machine translation and language model evaluation.
提供机构:
Google创建时间:
2025-02-06
搜集汇总
数据集介绍
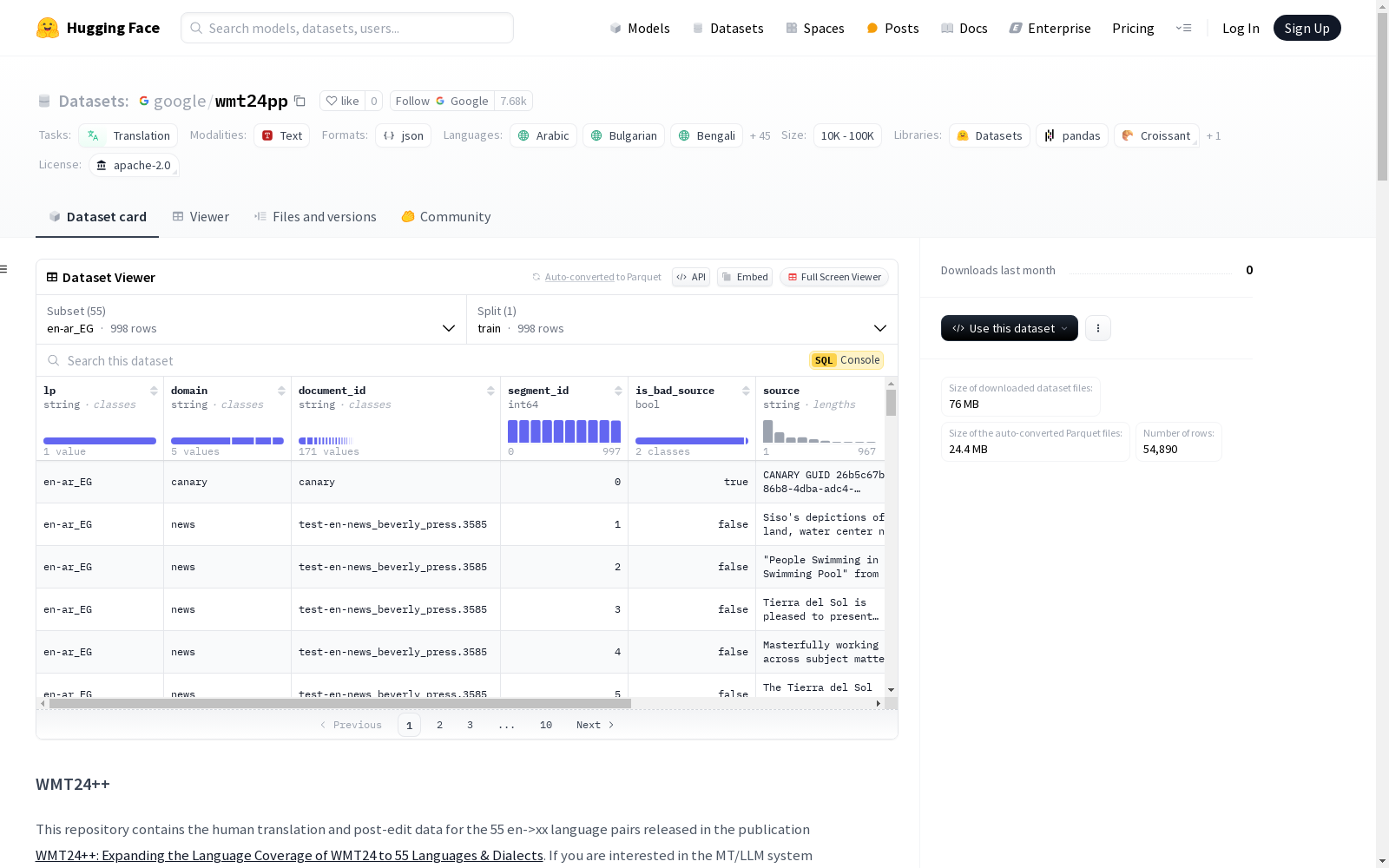
构建方式
WMT24++数据集的构建,旨在扩展WMT24的语言覆盖范围至55种语言及方言。该数据集包含了从不同领域(如新闻、社交、演讲、文学等)收集的英语源文本及其对应的翻译文本,涵盖了阿拉伯语、德语、法语、日语、中文等多种语言。构建过程中,数据被划分为训练集,并以jsonl格式存储,每行是一个包含语言对、领域、文档ID、段ID等字段的序列化JSON对象。
特点
WMT24++数据集的特点在于其语言的广泛覆盖,以及提供了源文本和经过后编辑的翻译文本。数据集按语言对组织,支持多种语言之间的翻译研究。此外,数据集还提供了关于文本来源的质量标记,有助于研究人员在分析和评估时排除低质量数据。每个语言对的翻译数据都包含文档和段的唯一标识符,方便追踪和管理。
使用方法
使用WMT24++数据集时,研究人员可以依据语言对和领域进行筛选,获取相应的训练数据。数据集以jsonl格式存储,便于使用Python等编程语言进行读取和处理。用户可以依据提供的Python常量,快速访问不同语言对的翻译数据,同时可以利用数据集中的质量标记来优化数据选择,提高研究结果的准确性。
背景与挑战
背景概述
WMT24++数据集是在机器翻译领域的一个重要成果,它由Google Research团队于2024年发布。该数据集涵盖了55种语言及方言,旨在扩展WMT2024的语言覆盖范围,为机器翻译模型提供更加丰富和多样化的训练材料。数据集包含人类翻译和后期编辑的数据,覆盖了新闻、社交、演讲、文学等多个领域,其语言对包括英语与阿拉伯语、保加利亚语、孟加拉语、加泰罗尼亚语等多种语言。该数据集的发布对于促进小语种机器翻译技术的发展具有重要意义,有助于提升翻译模型的准确性和鲁棒性。
当前挑战
在构建WMT24++数据集的过程中,研究人员面临着诸多挑战。首先,需要确保不同语言对的翻译质量和一致性,这对于多语言环境的翻译系统尤为重要。其次,数据集的构建需要处理大量的低质量源数据,如HTML代码、URL链接、表情符号等,这些都需要在预处理阶段被有效识别和清除。此外,数据集的规模和多样性也带来了整合和管理的挑战,需要开发有效的数据管理和查询系统来支持大规模多语言数据集的操作。对于研究领域而言,如何利用这些数据来提高机器翻译的准确性和适应性,以及如何处理跨语言和跨文化差异,是当前和未来研究的重点。
常用场景
经典使用场景
WMT24++数据集广泛应用于机器翻译领域,其经典使用场景在于为机器翻译模型提供高质量的平行语料,进而辅助模型提升翻译准确性和流畅性。该数据集包含了55种语言与英语之间的翻译对,为多语言翻译模型的训练和评估提供了丰富的资源。
实际应用
在实际应用中,WMT24++数据集可被用于改进在线翻译服务,提高翻译结果的准确性和可靠性。此外,它还可以应用于本地化服务,帮助企业和机构将内容准确高效地翻译成目标语言,以满足全球市场的需求。
衍生相关工作
基于WMT24++数据集,研究者们衍生出了许多相关工作,如跨语言信息检索、机器翻译的误差分析、以及多语言处理系统的开发等。这些工作不仅拓展了数据集的应用范围,也为机器翻译领域带来了新的研究视角和技术进步。
以上内容由遇见数据集搜集并总结生成


