NupePilot/NupePilotV1.0
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/NupePilot/NupePilotV1.0
下载链接
链接失效反馈官方服务:
资源简介:
NupePilot是一个多领域的英语-Nupe平行语料库,旨在支持低资源NLP研究和应用。Nupe是一种尼日尔-刚果语系的语言,主要在尼日利亚中北部使用。数据集包含手动整理的英语和Nupe之间的平行文本,支持机器翻译、文本生成、对话AI和跨语言迁移学习等任务。数据集结构清晰,包含id、domain、source_lang、target_lang、source_text和target_text等字段。数据集规模较小,约200多个例子,主要集中在日常对话领域,但也包含健康和新闻等其他领域的少量例子。数据来源包括公共领域文本、基准数据集、手动构建的例子和当代信息内容。数据集不包含任何个人或敏感信息。创建此数据集的动机是为了解决Nupe语言在NLP中的代表性不足问题,支持包容性和公平的AI发展。数据集的使用意图包括学术研究、低资源NLP实验、翻译系统原型设计和教育语言分析。但数据集也存在一些局限性,如规模小、领域覆盖有限等。
NupePilot is a pilot parallel dataset for Nupe, a low-resource Niger-Congo language (Volta-Niger subfamily) spoken primarily in North-Central Nigeria. It provides a manually curated, multi-domain English–Nupe parallel corpus designed to support low-resource NLP research and applications. The dataset supports tasks such as Machine Translation (English → Nupe), Text-to-Text Generation, Conversational AI, and Cross-lingual transfer learning. Each example in the dataset includes fields like id, domain, source_lang, target_lang, source_text, and target_text. The dataset contains around 200+ examples, primarily in everyday conversational phrases, with a smaller number of examples from additional domains such as health and news. The data was curated from public-domain text sources, benchmark-style datasets, manually constructed examples, and contemporary informational content. The dataset does not contain any personal or sensitive data. The motivation behind this dataset is to address the underrepresentation of Nupe in NLP, support inclusive and equitable AI development, and provide foundational data for future research. The intended uses include academic research, low-resource NLP experimentation, prototyping translation systems, and educational and linguistic analysis. However, the dataset has limitations such as small size and limited domain coverage.
提供机构:
NupePilot
搜集汇总
数据集介绍
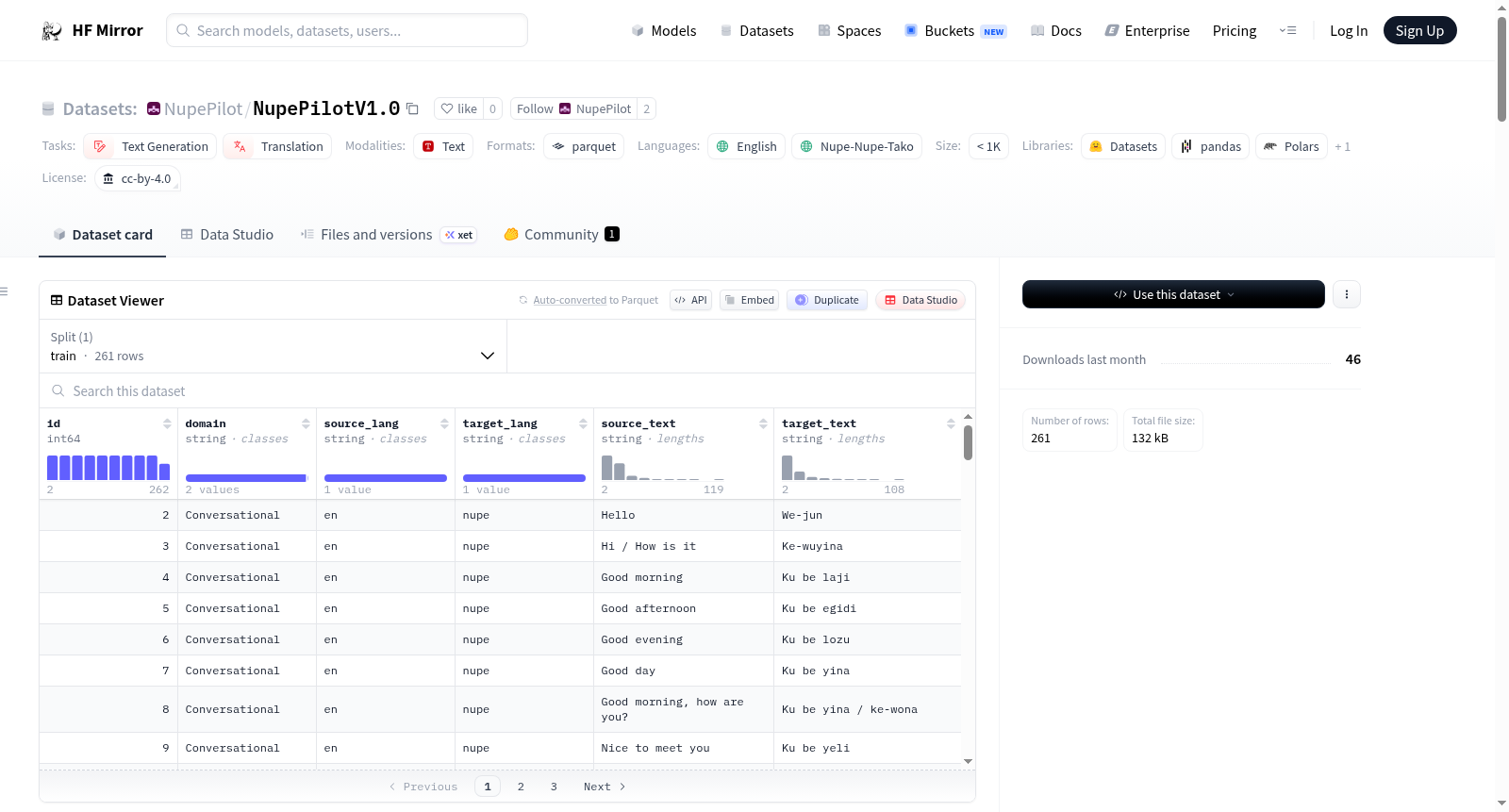
构建方式
NupePilotV1.0是为低资源尼日尔-刚果语系努佩语(Nupe)构建的首个多领域英-努平行语料库。该数据集通过人工精心筛选与标引,从公共领域文本、基准风格语料库(如日常对话与新闻语料)、人工构建例句以及当代信息内容中收录了超过200组平行句子。每条样本均包含唯一标识符、领域标签(对话、健康、新闻)、源语言与目标语言代码及对应的源文本与译文,确保了数据结构的一致性与可复用性。
特点
该数据集的核心特色在于其多领域覆盖与低资源语言聚焦。当前版本以日常对话短语为主,同时涵盖健康公共信息与新闻片段的样例,体现了在有限规模下对语言多样性的追求。所有数据均经人工审核,不包含个人或敏感信息,并采用CC BY 4.0许可发布,旨在为机器翻译、文本生成、跨语言迁移学习等任务提供基础资源,推动努佩语在自然语言处理领域的公平与包容性发展。
使用方法
用户可直接从HuggingFace加载NupePilotV1.0的默认配置,其中仅包含训练集,共261条样本。该数据集适合用于学术研究与低资源NLP实验,支持英文至努佩语的机器翻译系统原型开发、对话式AI训练以及语言学习工具构建。由于数据量较小且领域覆盖有限,推荐将其作为基线或迁移学习的初始语料,未来版本计划扩展更多领域以提升通用性。
背景与挑战
背景概述
在自然语言处理领域,低资源语言的数据稀缺长期制约着多语言技术的普惠发展。NupePilotV1.0数据集由Amina Mardiyyah Rufai、Fatima Tasallah Rufai和Yahaya Gana Rufai于2026年创建,聚焦于尼日尔-刚果语系沃尔特-尼日尔语支的努佩语(Nupe)。尽管努佩语拥有数百万使用者,但其数字化资源极度匮乏,在机器翻译等NLP任务中几乎处于空白状态。该数据集以人工精选方式构建了一个涵盖日常对话、健康、新闻等多领域的英努平行语料库,旨在为低资源NLP研究提供基础数据支撑,推动包容性人工智能发展,其开源发布对非洲语言资源建设具有示范意义。
当前挑战
该数据集面临的核心挑战在于:首先,从领域问题看,低资源语言的神经机器翻译任务受限于平行语料规模,努佩语的形态复杂性和缺乏标准化正字法进一步加大了模型泛化难度;其次,构建过程中,团队需从公共领域文本、自建例句等异构来源手工收集并校对语料,面临领域覆盖不均(当前版本高度偏向日常会话)、翻译一致性难以保障以及数据量仅约200条的局限性,这导致现有版本尚无法支撑生产级系统,且可能引入数据偏差,影响跨域迁移能力。
常用场景
经典使用场景
在非洲语言自然语言处理领域,低资源语言的数据稀缺问题一直是制约技术发展的瓶颈。NupePilotV1.0作为首个多领域英—努佩平行语料库,其经典使用场景聚焦于机器翻译模型的训练与评估。该数据集涵盖日常对话、健康及新闻三个领域,提供了261条经过人工精校的平行句对,为构建基础翻译系统提供了必要的训练信号。研究者可以利用这些配对数据,在序列到序列的架构下训练从英语到努佩语的翻译模型,或通过零样本迁移学习探索跨语言知识共享的可能性。
解决学术问题
该数据集直面尼日尔-刚语系中努佩语在数字环境下的结构性匮乏问题。在学术层面,它填补了非洲低资源语言数据处理流程的空白,解决了因缺乏标准化平行语料而难以开展对照实验的困境。其意义在于为跨语言迁移学习、低资源场景下的数据增强策略、以及语言类型学研究提供了可复现的基准。通过开源发布,数据集激励学术界重新审视资源分配不均的问题,推动包容性人工智能研究范式的形成,从而在方法上验证少量高质量数据对模型性能的边际贡献。
衍生相关工作
该数据集衍生出的相关工作主要围绕低资源语言数据集的构建方法论展开。研究者受NupePilot的启发,开始探索从公共领域文本和人工构造范例中有效提取平行句对的流程,并尝试结合主动学习策略来优化数据标注效率。此外,有工作基于本语料测试了无监督预训练模型在极低资源翻译任务上的表现,揭示了拼音化语言与音段书写系统之间的映射难题。这些衍生研究推动了非洲语言标准化资源创建协议的讨论,并为后续更大规模、多领域的努佩语语料库积累了实验经验与设计框架。
以上内容由遇见数据集搜集并总结生成


