hinglish
收藏Hinglish 拼接音频数据集
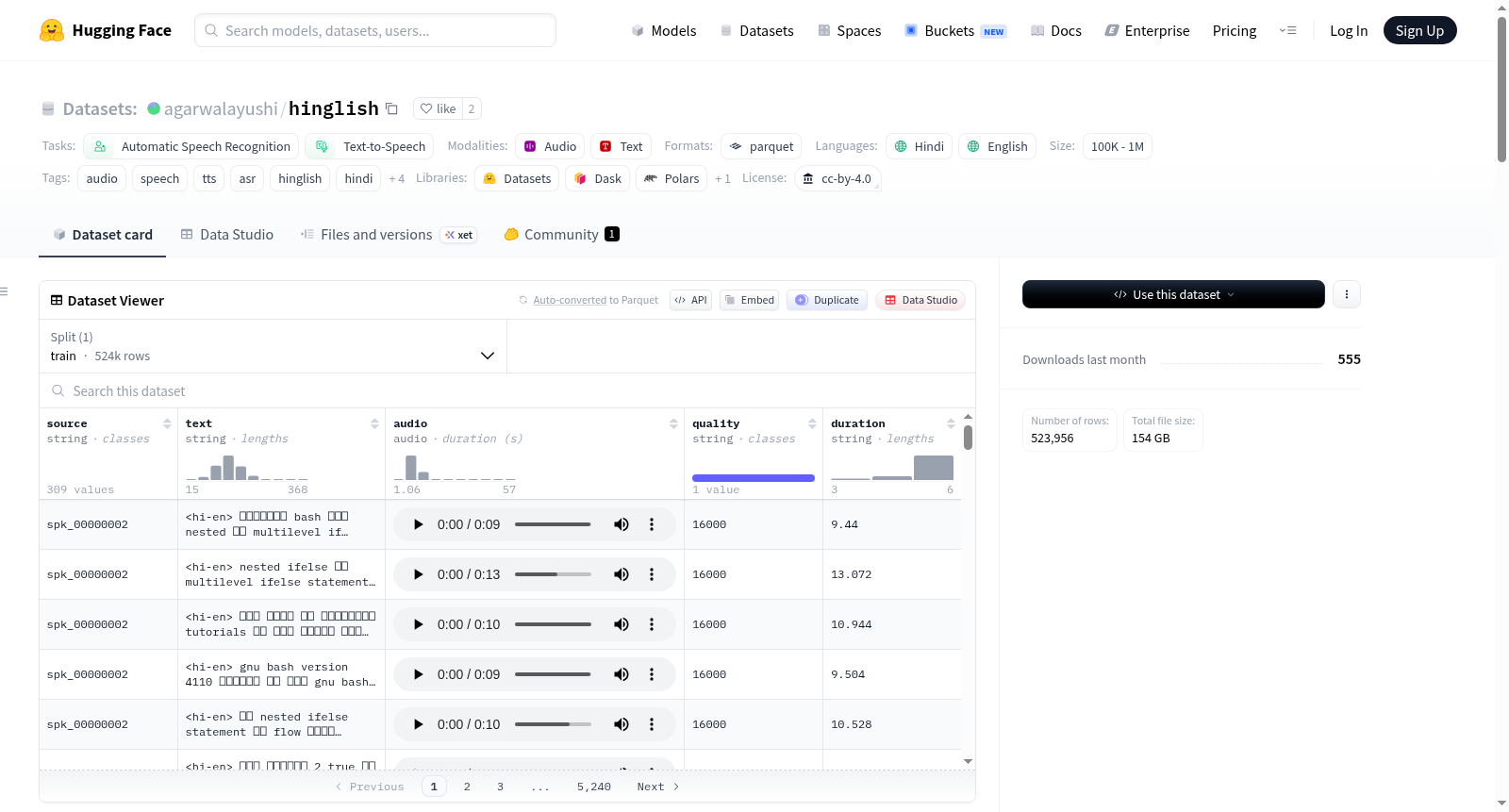
数据集概述
该数据集是一个大规模、经过清洗和标注的语音数据集,涵盖 印地语(Hindi)、印英混合语(Hinglish) 和 印度英语(Indian English)。数据集由来自 14 个公共语料库和原创定制录音整合而成,统一为 Parquet 格式,并采用一致的 schema。
关键统计信息
| 统计项 | 数值 |
|---|---|
| 总音频片段数 | 815,171 |
| 总预计时长 | 超过 2,264 小时 |
| 独立说话人数 | 6,304 |
| 原始音频大小 | 约 237 GB |
| 语言 | 印地语 (hi)、印英混合语 (hi-en)、印度英语 (en-IN) |
| 格式 | Parquet(嵌入音频,兼容 Hugging Face 数据集查看器) |
| 适用任务 | 自动语音识别(ASR)、文本转语音(TTS)微调、语音克隆、语音研究 |
数据集 Schema
| 字段名 | 类型 | 描述 |
|---|---|---|
source |
string |
说话人或来源标识符 |
text |
string |
清洗后的转录文本(可能包含 <hi-en> 语言标签) |
audio |
Audio |
嵌入 Parquet 的 WAV 音频,保留原始采样率 |
quality |
string |
采样率(Hz)或 MOS 质量评分(如可用) |
duration |
string |
音频片段时长(秒) |
数据来源构成
| 来源数据集 | 音频片段数 | 描述 | 许可证 |
|---|---|---|---|
| NPTEL Hindi Spoken Tutorial | 521,028 | 印地语教育讲座 | CC BY 4.0 |
| AI4Bharat Kathbath | 94,903 | 多说话人印地语语音基准 | CC BY 4.0 |
| AI4Bharat IndicTTS | 36,613 | 录音室品质印地语 TTS 语料库 | CC BY 4.0 |
| Hinglish — ujs | 25,378 | 印英混合语语音 | 见原来源 |
| Mozilla Common Voice 17 (Hindi) | 24,643 | 社区贡献的印地语语音 | CC0 1.0 |
| AI4Bharat Mann Ki Baat | 22,483 | 印地语广播语音(英-印对齐) | CC BY 4.0 |
| Mann Ki Baat (English) | 22,477 | Mann Ki Baat 平行语料库的英语部分 | CC BY 4.0 |
| Hindi Female Single Speaker HQ — Shekharmeena | 22,058 | 高质量单说话人印地语女声 | 见原来源 |
| Orpheus TTS Indian English | 18,238 | 多说话人印度英语 TTS | 见原来源 |
| Indic TTS Hindi — SPRINGLab | 11,825 | 多说话人印地语 TTS | CC BY 4.0 |
| Indian English — krishan23 | 6,765 | 印度口音英语语音 | 见原来源 |
| Hinglish Test TTS — Shekharmeena | 3,136 | 定制印英混合语 TTS 录音 | 见原来源 |
| Custom female TTS recordings | 2,843 | 原创录音室录音 | CC BY 4.0 |
| Orpheus TTS Shaurya — prashantarya | 1,419 | 男性印地语/英语 TTS 语音 | 见原来源 |
| Anika Voice — Shekharmeena | ~5 | 定制女声印地语/印英混合语语音 | 见原来源 |
数据处理与清洗
- 所有音频片段重新切分,去除静音和串扰
- 转录文本统一为 Unicode NFC 标准化,为代码切换话语添加
<hi-en>语言标签 - 去除重复和近似重复的音频片段
- 所有来源在拼接前统一为一致的 CSV schema
- 音频存储为 WAV 格式,保留原始采样率
许可证
本数据集采用 Creative Commons Attribution 4.0 International (CC BY 4.0) 许可证。
允许:
- 用于研究、商业或个人项目
- 以任何媒介共享和重新分发
- 基于数据进行修改和改编
需遵守:
- 署名 — 注明本数据集及上方列出的原始来源数据集链接
- 禁止不当使用 — 不得用于生成未经同意的真实个人合成语音,或用于欺诈、骚扰、虚假信息
⚠️ 上游许可证: 每个组成数据集保留其原始许可证。用户有责任遵守其所使用来源的条款。Mozilla Common Voice 为 CC0 许可证;所有 AI4Bharat 和 SPRINGLab 来源为 CC BY 4.0 许可证。标记为“见原来源”的数据集需单独核查。
引用
如需引用本数据集,请使用以下 BibTeX 格式:
bibtex @dataset{agarwal2026hinglish, author = {Agarwal, Ayushi}, title = {Hinglish Concatenated Audio Dataset}, year = {2026}, publisher = {Hugging Face}, url = {https://huggingface.co/datasets/agarwalayushi/hinglish}, note = {Aggregated from Mozilla Common Voice, AI4Bharat (Kathbath, Mann Ki Baat, Spoken Tutorial, IndicTTS), SPRINGLab IndicTTS, and custom recordings} }