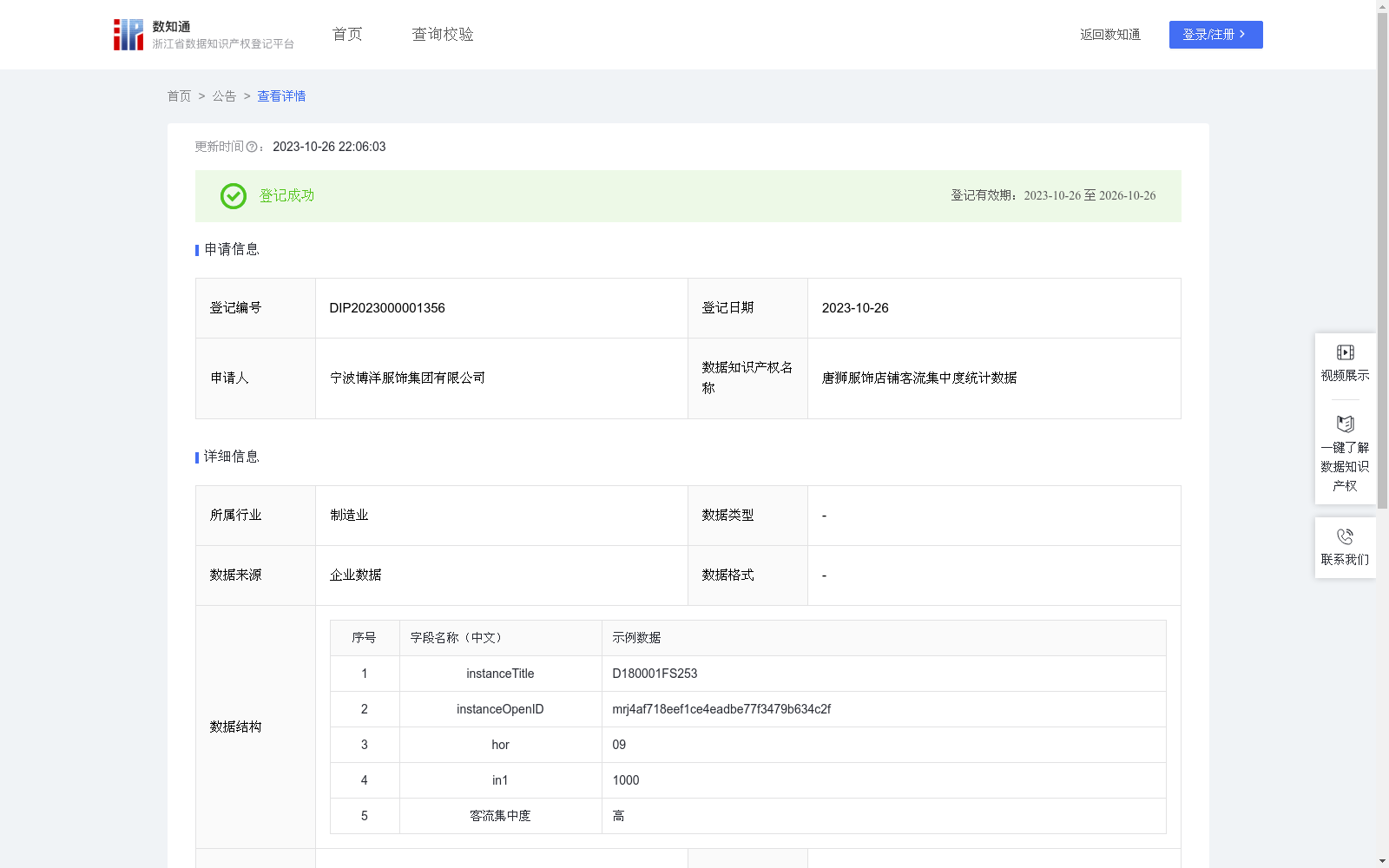
唐狮服饰店铺客流集中度统计数据
收藏浙江省数据知识产权登记平台2023-10-26 更新2024-05-08 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/7128
下载链接
链接失效反馈官方服务:
资源简介:
唐狮服饰总部借助旗下的门店,收集店铺客流数据。对客流数据按照进入门店的时间,切片到每个时段(小时)。再对09:00~22:00 之间每个时段的客流数量占比、以及该时段为客流高峰的概率统计分析,得出每家店铺在每个时段的客流集中度状况,区分为集中度超高、高、一般、散量。以上数据可用于门店客流的整体趋势变化分析,门店客流的时段集中度分析,以及为提升店铺的成交率、客流价值、服务水平提供决策依据。通过以上数据依托,提升企业门店整体经营管理水平。以上数据存储于企业内部关系型数据库中。预估日均新增数据为1500笔。并已经过数据去冗和数据清洗和数据整合。对于涉及客流数据的隐私信息,已经经过脱敏和加密处理。主要字段说明:instanceTitle:店铺编号;instanceOpenID;设备编号;hor:客流时段,取值范围为00~23;in1:客流数量,根据客流时段进行汇总所得。其中 instanceTitle、instanceOpenID、hor、in1 来源于店铺客流设备的数据采集;客流集中度来源于聚类算法得出。
客流集中度数据基于K-均值聚类模型,对每家店铺近三个月9:00~22:00的客流数据统计分析,得出每家店铺在09:00~22:00每个时段的客流数量的集中性。s1: ,收集店铺客流数据,对客流数据按照进入门店的时间进行数据切片,切片到每个时段(小时) ;s2:统计店铺每个时段客流人数,以及在全时段总客流人数中的占比;s3:统计店铺出现客流峰值的时段,以及该峰值时段出现的概率;s4:基于以上统计结果,即时段的客流占比和该时段出现峰值客流的概率。以占比和概率作为数据点指标,通过K-均值聚类模型,初始化4个随机点作为聚类中心,迭代计算簇中心,直到聚类中心不再发生改变,或者达到最大迭代次数10000次。
The headquarters of Tonlion Apparel collects in-store passenger flow data through its chain stores. The collected passenger flow data is sliced by the time when customers enter the store, with the time granularity set to each hour. Subsequently, statistical analysis is conducted on the proportion of passenger flow volume in each hourly interval between 09:00 and 22:00, as well as the probability of each interval being a peak passenger flow period, to determine the passenger flow concentration status of each store per hour, which is categorized into four levels: extremely high concentration, high concentration, moderate concentration, and scattered flow. This dataset can be used for overall trend analysis of store passenger flow, temporal concentration analysis of passenger flow, and provides decision-making support for improving store transaction rate, passenger flow value, and service level, thereby enhancing the overall operation and management level of the enterprise's stores. The above data is stored in the enterprise's internal relational database. The estimated daily new data volume is 1500 records. The data has undergone data deduplication, data cleaning, and data integration processing. Privacy information involved in the passenger flow data has been anonymized and encrypted. Main field descriptions: - `instanceTitle`: Store number; - `instanceOpenID`: Reserved identification field; - `deviceNumber`: Equipment number; - `hor`: Passenger flow time interval, with valid values ranging from 00 to 23; - `in1`: Total passenger flow volume aggregated based on each hourly time interval. Among them, `instanceTitle`, `instanceOpenID`, `hor`, and `in1` are collected from in-store passenger flow monitoring equipment; the passenger flow concentration level is derived from clustering algorithm results. The passenger flow concentration data is generated based on the K-Means clustering model. Specifically, statistical analysis is conducted on the passenger flow data of each store between 09:00 and 22:00 over the past three months to calculate the concentration of passenger flow volume in each hourly interval of 09:00~22:00 for each store. The specific processing steps are as follows: 1. `s1`: Collect in-store passenger flow data, and slice the collected data by the time when customers enter the store, with the time granularity set to each hour; 2. `s2`: Count the number of passengers in each time interval, as well as their proportion in the total passenger flow of the entire 09:00~22:00 period; 3. `s3`: Count the time intervals with peak passenger flow for the store, as well as the probability of each interval being the peak period; 4. `s4`: Based on the above statistical results, i.e., the passenger flow proportion of each interval and the probability of the interval being a peak period, take these two metrics as data point indicators. Use the K-Means clustering model, initialize 4 random points as cluster centers, and iteratively calculate the cluster centers until the cluster centers no longer change or the maximum number of iterations (10000) is reached.
提供机构:
宁波博洋服饰集团有限公司
创建时间:
2023-10-07
搜集汇总
数据集介绍
特点
该数据集包含唐狮服饰店铺的客流集中度统计数据,每日更新,数据规模为1547条。通过K-均值聚类模型分析客流数据,得出每家店铺在不同时段的客流集中度,分为超高、高、一般、散量四个等级,用于门店客流趋势分析和经营管理决策支持。
以上内容由遇见数据集搜集并总结生成


