notrichardren/pig_latin_english_mmlu
收藏Hugging Face2024-05-15 更新2024-06-12 收录
下载链接:
https://hf-mirror.com/datasets/notrichardren/pig_latin_english_mmlu
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含多个字段,涉及英语和Pig Latin的问题和选项,以及对应的答案。数据集分为训练集、验证集和测试集,分别包含285、1531和14042个示例。数据集的字段包括英语问题、Pig Latin问题、主题、英语选项、Pig Latin选项、ID和答案。这些字段表明数据集可能用于多语言或多形式的问题回答任务,特别是涉及英语和Pig Latin的转换。
This dataset includes questions and options in both English and Pig Latin, along with the subject, unique ID, and correct answer for each question. It is divided into training, validation, and test sets for model training and evaluation.
提供机构:
notrichardren
原始信息汇总
数据集概述
数据集特征
- q_english: 字符串类型
- q_piglatin: 字符串类型
- subject: 字符串类型
- a_english: 字符串类型
- b_english: 字符串类型
- c_english: 字符串类型
- d_english: 字符串类型
- a_piglatin: 字符串类型
- b_piglatin: 字符串类型
- c_piglatin: 字符串类型
- d_piglatin: 字符串类型
- id: 字符串类型
- mmlu_answer: 整数类型(64位)
数据集分割
- 训练集:
- 示例数量: 285
- 数据大小: 302222 字节
- 验证集:
- 示例数量: 1531
- 数据大小: 1861767 字节
- 测试集:
- 示例数量: 14042
- 数据大小: 16913214 字节
数据集大小
- 下载大小: 9351485 字节
- 总数据集大小: 19077203 字节
数据文件配置
- 默认配置:
- 训练集路径:
data/train-* - 验证集路径:
data/validation-* - 测试集路径:
data/test-*
- 训练集路径:
搜集汇总
数据集介绍
构建方式
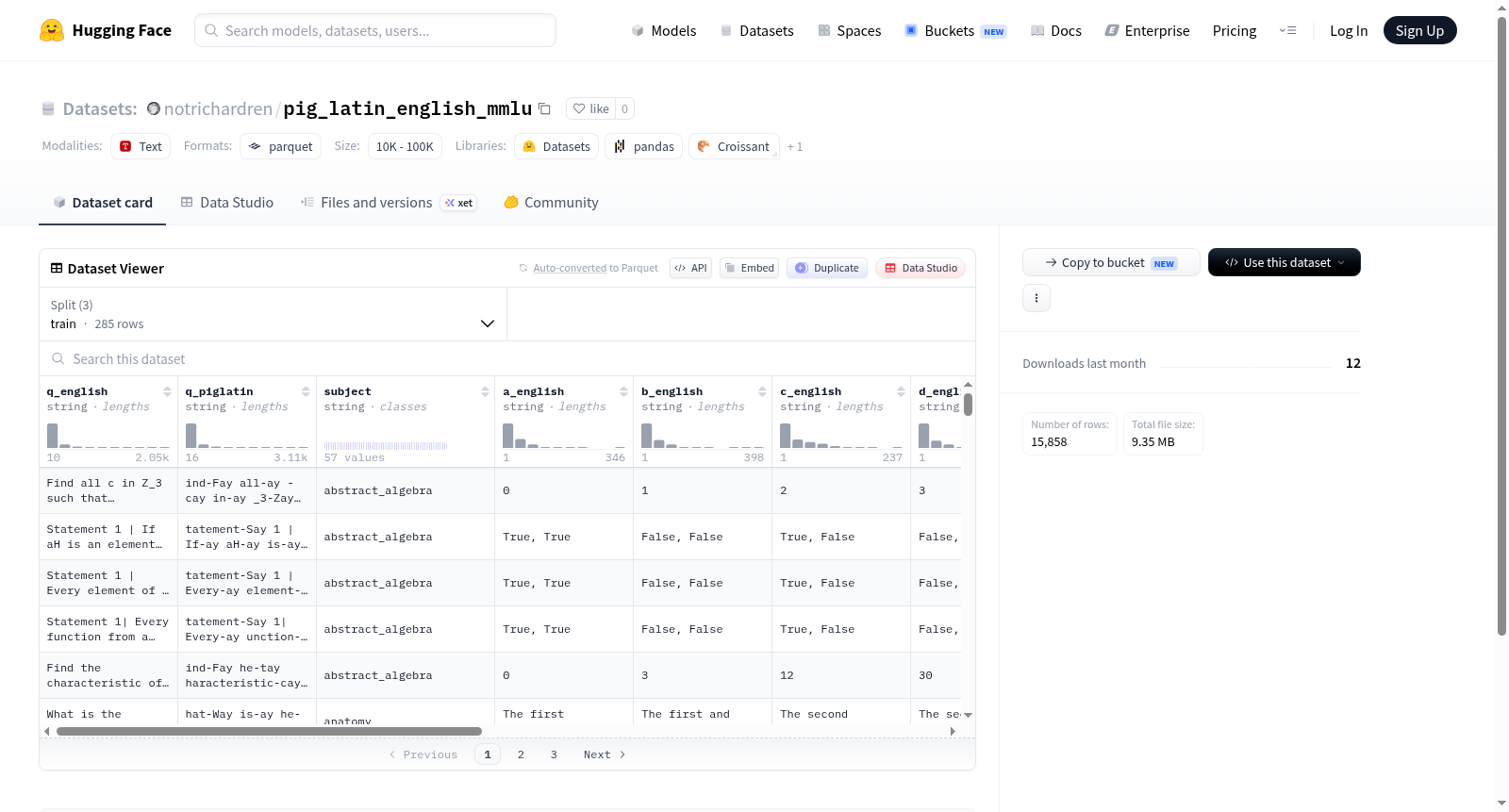
该数据集基于大规模多任务语言理解基准(MMLU)进行构建,通过将原始英文问答对转换为猪拉丁语(Pig Latin)形式,形成双语对照的评估资源。具体而言,数据集保留了MMLU原始问题(q_english)、四个选项(a_english至d_english)及正确答案(mmlu_answer),并对应生成了猪拉丁语版本的问题(q_piglatin)和选项(a_piglatin至d_piglatin)。此外,每条数据还标注了学科主题(subject)与唯一标识(id),确保与MMLU的映射关系清晰。数据集划分为训练集(285条)、验证集(1531条)和测试集(14042条),总样本量约1.6万条,覆盖多种学科领域。
特点
数据集的核心特点在于其双语对照设计,同时包含标准英语与猪拉丁语两种语言形式的问答对,为评估模型在语言变换下的推理能力提供了独特视角。每条样本均包含完整的问题、四个选项及正确答案,且猪拉丁语版本严格对应原始英语内容,确保语义等价性。学科主题的标注使得该数据集可用于细粒度分析模型在不同知识领域的表现。数据规模上,测试集占比最大(约88%),适合作为主要评测基准,而训练集与验证集则支持模型微调或验证。
使用方法
该数据集可直接用于训练或评估自然语言处理模型在猪拉丁语环境下的理解与推理能力。使用时,用户可通过HuggingFace Datasets库加载指定配置(default),并选择训练、验证或测试拆分。典型应用场景包括:基于q_english与q_piglatin进行跨语言问答任务,或利用a_english至d_english及对应猪拉丁语选项评估模型对变体语言的鲁棒性。建议将mmlu_answer作为标签,结合学科主题进行分领域性能分析。数据格式为JSON Lines,便于集成到现有流水线中。
背景与挑战
背景概述
在自然语言处理与知识评估的交叉领域中,如何衡量语言模型对变形语言的鲁棒性始终是一个悬而未决的课题。notrichardren/pig_latin_english_mmlu数据集由研究者于2023年构建,旨在探索模型在猪拉丁文(Pig Latin)这一英语文字游戏变体上的理解能力。该数据集基于经典的MMLU(Massive Multitask Language Understanding)基准进行改造,将原始英语问题与选项转换为猪拉丁文形式,同时保留原题的标准答案。核心研究问题聚焦于语言模型在应对非标准拼写与语法变形时的泛化表现,尤其关注语义保持与推理能力的退化程度。这一工作为评估模型的语言不变性提供了新视角,对多语言理解与对抗性测试领域产生了重要影响。
当前挑战
当前数据集面临的核心挑战包括:其一,猪拉丁文作为一种人为规则变形,其转换逻辑(如将首辅音移至词尾并添加“ay”)虽简单,但模型需在噪声输入中准确还原语义,这考验了模型对词汇形态的深层抽象能力。其二,构建过程中需确保MMLU原有知识难度不因语言变形而降低,但部分问题依赖特定词汇变形后的可读性,导致某些题目在猪拉丁文下可能产生歧义或信息丢失。其三,数据集规模较小(训练集仅285条),限制了模型在微调时充分学习变形规律的能力,可能引发过拟合或泛化不足。这些挑战共同指向了语言模型在对抗性语言变异下的脆弱性,亟需更鲁棒的编码与推理机制加以应对。
常用场景
经典使用场景
该数据集基于经典的大规模多任务语言理解基准MMLU构建,通过将英语问题与选项转换为猪拉丁语(Pig Latin)这一语言游戏形式,为评估大语言模型在噪声与编码变换环境下的推理能力提供了独特视角。其经典使用场景聚焦于探究模型能否在输入被非线性规则扰动时,仍保持对语义的深层理解与跨语言形态的泛化能力,尤其适用于测试模型对词汇变形、句法重组等对抗性扰动的鲁棒性。
实际应用
在实际应用中,该数据集可服务于需要高鲁棒性的自然语言处理系统开发,例如多语言客服机器人、代码混淆下的安全检测以及教育领域的语言学习辅助工具。它帮助工程师验证模型在面对用户非标准表达、拼写变体或故意编码的查询时,能否稳定输出正确响应,从而提升系统在真实复杂场景中的可靠性。
衍生相关工作
该数据集衍生出若干关键研究方向,包括对抗性语言变换对模型公平性的影响分析、基于编码规则的数据增强策略设计,以及跨语言形态的迁移学习基准构建。相关经典工作如探究猪拉丁语变换对模型注意力机制的影响、利用该数据集训练更鲁棒的编码器-解码器架构,以及将其作为元学习任务以提升模型对未见语言规则的适应能力。
以上内容由遇见数据集搜集并总结生成


