FlowBench
收藏arXiv2024-06-21 更新2024-08-06 收录
下载链接:
http://arxiv.org/abs/2406.14884v1
下载链接
链接失效反馈官方服务:
资源简介:
FlowBench是由浙江大学和阿里巴巴集团合作创建的,旨在通过系统化的基准测试评估基于LLM的代理在任务规划中的表现。该数据集包含51个不同场景,覆盖6个领域,采用多种知识格式(文本、代码、流程图)以适应实际应用。创建过程分为任务收集、工作流组织和会话生成三个阶段,确保数据集的多样性和专业级标注。FlowBench适用于评估代理在复杂任务中的规划能力,特别是在需要外部工作流知识支持的场景中,为未来代理规划研究提供了挑战性的基准。
FlowBench is a collaborative benchmark developed by Zhejiang University and Alibaba Group, designed to evaluate the task planning performance of LLM-based AI agents through systematic benchmark testing. This dataset comprises 51 distinct scenarios spanning 6 domains, and supports multiple knowledge formats including text, code, and flowcharts to cater to real-world applications. Its development process is divided into three stages: task collection, workflow organization, and session generation, which guarantees the dataset's diversity and professional-grade annotations. FlowBench is tailored to evaluate the planning capabilities of AI agents in complex tasks, particularly in scenarios requiring external workflow knowledge support, providing a challenging benchmark for future research in agent planning.
提供机构:
浙江大学, 阿里巴巴集团
创建时间:
2024-06-21
搜集汇总
数据集介绍
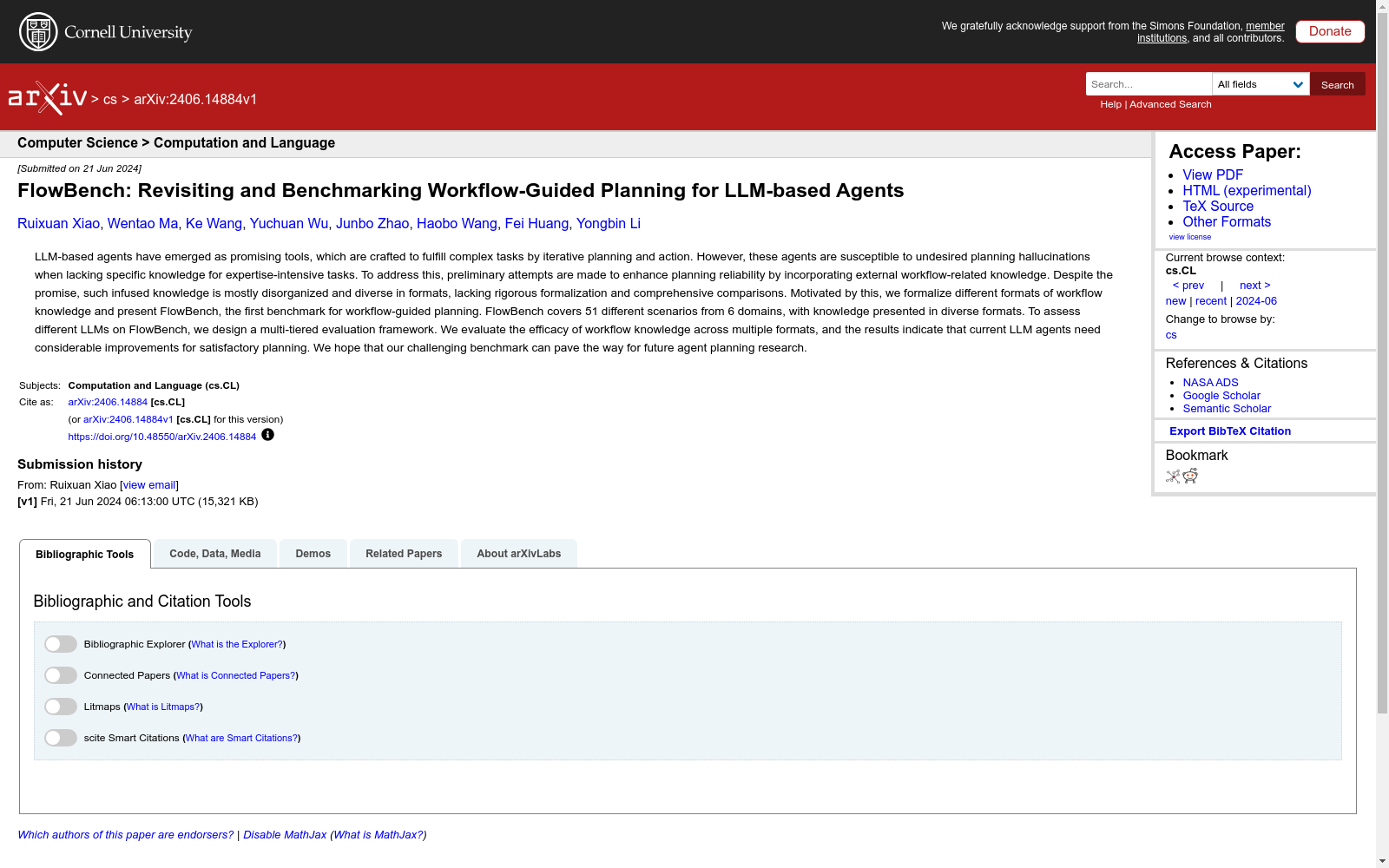
构建方式
FlowBench数据集的构建经历了三个阶段:任务收集、工作流程组织和交互会话生成。首先,从六个领域(客户服务、个人助理、电子商务推荐、旅行和交通、物流解决方案、机器人流程自动化)中收集了22个角色和51个场景。其次,通过专业知识库、工作流程知识网站和搜索引擎结果,将工作流程相关的专业知识总结成自然语言文档,并由人工标注者验证其正确性、完整性和非冗余性。随后,使用GPT-4将文本格式的知识转换为代码和流程图格式,并再次进行人工验证以确保知识的一致性。最后,通过提示GPT-4生成多样化的用户配置文件和真实的用户-代理交互会话,以增强会话的多样性和真实性。
使用方法
FlowBench数据集可用于评估LLM代理在工作流程引导规划方面的能力。评估框架包括静态轮次级别评估和模拟会话级别评估。静态轮次级别评估关注单步规划,而模拟会话级别评估模拟顺序规划。评估指标包括工具调用、参数收集、响应质量、成功率、任务进度等。
背景与挑战
背景概述
FlowBench数据集是针对基于大型语言模型(LLM)的智能体进行工作流程引导规划的首个基准测试。由浙江大学和阿里巴巴集团的研究人员合作开发,该数据集旨在解决LLM智能体在处理专业知识密集型任务时易出现规划幻觉的问题。FlowBench涵盖了来自六个领域的51个不同场景,并以多种格式呈现知识,如自然语言、符号代码和流程图。为了评估不同LLM在工作流程引导规划方面的性能,研究人员设计了一个多层次的评价框架,包括静态轮次级评价和动态会话级评价。FlowBench的发布为未来智能体规划研究提供了挑战,并指明了改进LLM智能体规划性能的方向。
当前挑战
FlowBench数据集面临的挑战主要包括:1) 领域问题挑战:LLM智能体在处理专业知识密集型任务时,缺乏特定知识会导致规划幻觉,而引入外部工作流程相关知识可以提高规划可靠性,但如何有效整合和利用这些知识仍然是一个未解决的问题。2) 构建挑战:FlowBench数据集的构建涉及任务收集、工作流程组织和会话生成三个阶段,需要大量的人工标注和验证工作,这增加了构建成本和时间投入。此外,数据集只涵盖了三种代表性的知识格式,未来需要探索更多潜在格式。
常用场景
经典使用场景
FlowBench数据集主要针对大型语言模型(LLM)驱动代理的规划能力进行评估。该数据集涵盖了6个领域的51个不同场景,并以文本、代码和流程图等多种格式呈现了相关知识。通过多轮用户代理交互,FlowBench能够模拟现实世界中的复杂任务解决过程,为评估LLM代理的规划能力提供了全面而系统的基准。在FlowBench中,代理需要根据提供的流程知识进行规划,并执行相应的行动,以完成用户提出的任务。该数据集的构建过程包括任务收集、流程组织和会话生成三个阶段,旨在确保数据的多样性和真实性。通过静态回合级评估和模拟会话级评估,FlowBench能够全面评估LLM代理在不同场景下的规划能力。
解决学术问题
FlowBench数据集解决了LLM代理在知识密集型任务中存在的规划幻觉问题。由于LLM代理的内禀参数知识有限,当缺乏特定领域的专业知识时,它们可能会产生与任务知识相冲突的不当行为。FlowBench通过引入外部流程知识,帮助LLM代理更好地理解任务流程,从而提高规划可靠性。此外,FlowBench还解决了如何形式化、利用和评估流程知识的问题,为LLM代理在不同现实场景中的应用提供了有价值的参考。
实际应用
FlowBench数据集在实际应用中具有广泛的应用场景。首先,它可以帮助开发者和研究人员评估和改进LLM代理的规划能力,使其能够更好地完成复杂任务。其次,FlowBench可以作为LLM代理的训练数据集,通过学习流程知识,提高代理的决策和行动能力。此外,FlowBench还可以用于构建智能助手、聊天机器人等应用,为用户提供更加高效和准确的服务。
数据集最近研究
最新研究方向
FlowBench是一个专为评估基于LLM的代理人在工作流程引导规划方面的能力的基准。该基准涵盖了6个领域的51个不同场景,以及多种知识格式,包括文本、代码和流程图。FlowBench的设计旨在解决LLM代理在缺乏特定知识时可能出现的规划幻觉问题。研究结果表明,当前的LLM代理在规划方面仍需大量改进,以实现满意的性能。FlowBench的发布为未来代理人规划研究铺平了道路,特别是在工作流程知识如何被形式化、利用和评估方面。该研究对LLM代理设计提出了深刻的挑战,并指明了未来探索的焦点。
相关研究论文
- 1FlowBench: Revisiting and Benchmarking Workflow-Guided Planning for LLM-based Agents浙江大学, 阿里巴巴集团 · 2024年
以上内容由遇见数据集搜集并总结生成


