VLM2Vec/MMEB-V2
收藏Hugging Face2025-09-24 更新2026-01-03 收录
下载链接:
https://hf-mirror.com/datasets/VLM2Vec/MMEB-V2
下载链接
链接失效反馈官方服务:
资源简介:
---
license: apache-2.0
task_categories:
- visual-question-answering
- video-classification
language:
- en
viewer: false
configs:
- config_name: splits
data_files:
- split: eval
path:
- "video_tasks"
- "image_tasks"
---
# MMEB-V2 (Massive Multimodal Embedding Benchmark)
Building upon on our original [**MMEB**](https://arxiv.org/abs/2410.05160), **MMEB-V2** expands the evaluation scope to include five new tasks: four video-based tasks — Video Retrieval, Moment Retrieval, Video Classification, and Video Question Answering — and one task focused on visual documents, Visual Document Retrieval. This comprehensive suite enables robust evaluation of multimodal embedding models across static, temporal, and structured visual data settings.
**This Hugging Face repository contains only the raw image and video files used in MMEB-V2, which need to be downloaded in advance.**
The test data for each task in MMEB-V2 is available [here](https://huggingface.co/VLM2Vec) and will be automatically downloaded and used by our code. More details on how to set it up are provided in the following sections.
|[**Github**](https://github.com/TIGER-AI-Lab/VLM2Vec) | [**🏆Leaderboard**](https://huggingface.co/spaces/TIGER-Lab/MMEB) | [**📖MMEB-V2/VLM2Vec-V2 Paper (TBA)**](https://arxiv.org/abs/2410.05160) | | [**📖MMEB-V1/VLM2Vec-V1 Paper**](https://arxiv.org/abs/2410.05160) |
## 🚀 What's New
- **\[2025.05\]** Initial release of MMEB-V2.
## Dataset Overview
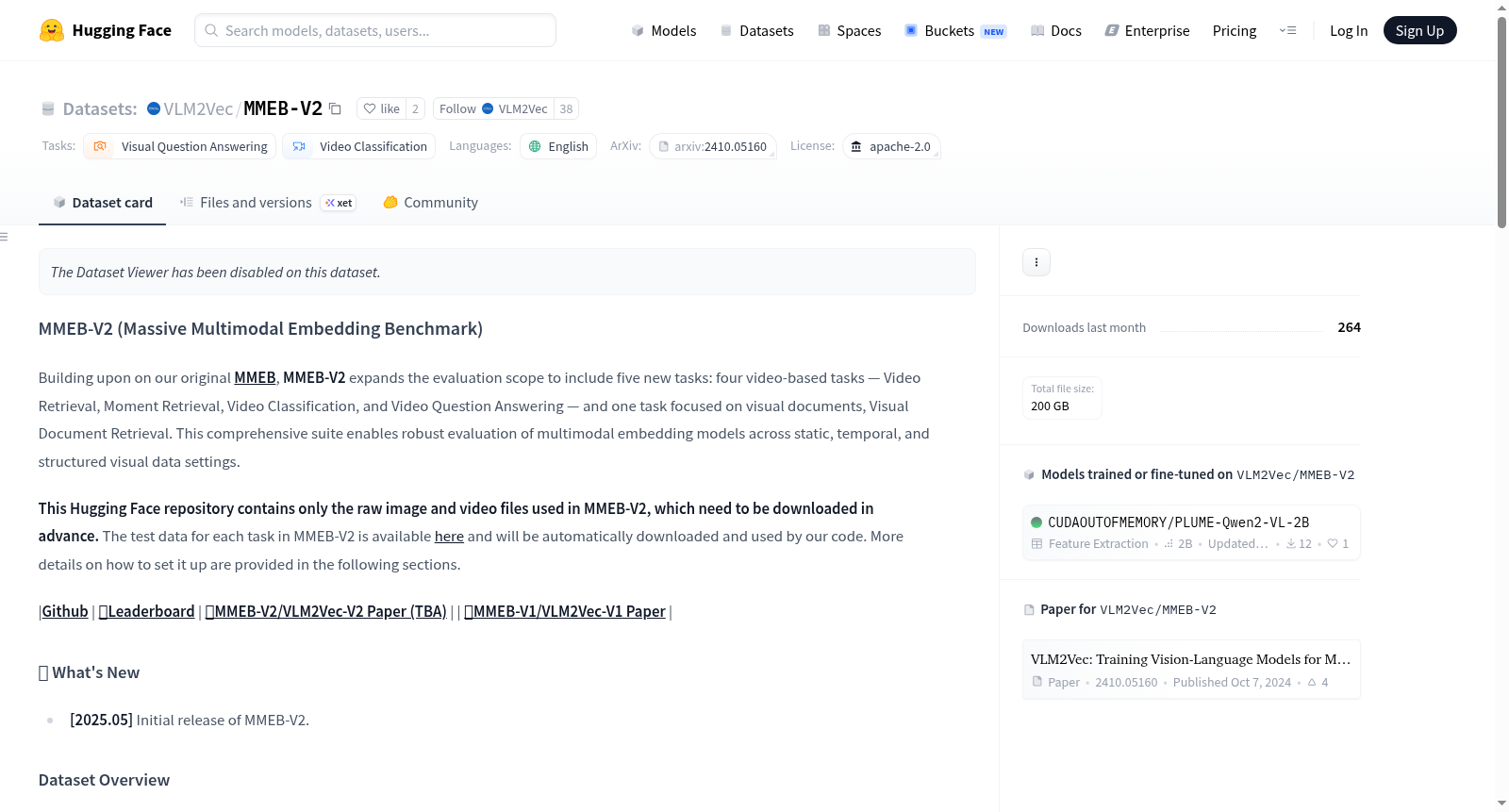
We present an overview of the MMEB-V2 dataset below:
<img width="900" alt="abs" src="overview.png">
## Dataset Structure
The directory structure of this Hugging Face repository is shown below.
For video tasks, we provide both sampled frames and raw videos (the latter will be released later). For image tasks, we provide the raw images.
Files from each meta-task are zipped together, resulting in six files. For example, ``video_cls.tar.gz`` contains the sampled frames for the video classification task.
```
→ video-tasks/
├── frames/
│ ├── video_cls.tar.gz
│ ├── video_qa.tar.gz
│ ├── video_ret.tar.gz
│ └── video_mret.tar.gz
├── raw videos/ (To be released)
→ image-tasks/
├── mmeb_v1.tar.gz
└── visdoc.tar.gz
```
After downloading and unzipping these files locally, you can organize them as shown below. (You may choose to use ``Git LFS`` or ``wget`` for downloading.)
Then, simply specify the correct file path in the configuration file used by your code.
```
→ MMEB
├── video-tasks/
│ └── frames/
│ ├── video_cls/
│ │ ├── UCF101/
│ │ │ └── video_1/ # video ID
│ │ │ ├── frame1.png # frame from video_1
│ │ │ ├── frame2.png
│ │ │ └── ...
│ │ ├── HMDB51/
│ │ ├── Breakfast/
│ │ └── ... # other datasets from video classification category
│ ├── video_qa/
│ │ └── ... # video QA datasets
│ ├── video_ret/
│ │ └── ... # video retrieval datasets
│ └── video_mret/
│ └── ... # moment retrieval datasets
├── image-tasks/
│ ├── mmeb_v1/
│ │ ├── OK-VQA/
│ │ │ ├── image1.png
│ │ │ ├── image2.png
│ │ │ └── ...
│ │ ├── ImageNet-1K/
│ │ └── ... # other datasets from MMEB-V1 category
│ └── visdoc/
│ └── ... # visual document retrieval datasets
```
提供机构:
VLM2Vec
搜集汇总
数据集介绍
构建方式
MMEB-V2数据集在原始MMEB基准的基础上进行扩展,新增了五项任务,涵盖四个基于视频的任务——视频检索、时刻检索、视频分类和视频问答,以及一个聚焦于视觉文档的视觉文档检索任务。数据集构建过程中,视频任务提供了采样帧和原始视频(后者后续发布),图像任务则提供原始图像。所有文件按元任务类别打包为六个压缩包,例如video_cls.tar.gz包含视频分类任务的采样帧。用户需通过Git LFS或wget下载并解压这些文件,然后按照指定目录结构组织,并在代码配置文件中设置正确的文件路径,以完成数据集的本地部署。
使用方法
使用MMEB-V2数据集时,首先需从HuggingFace仓库下载原始图像和视频文件,并解压至本地。随后,按照示例目录结构组织文件,例如将视频任务帧放入video-tasks/frames/下的对应子目录。测试数据标签和查询信息将从VLM2Vec仓库自动下载,用户只需在代码配置中指定正确的数据路径即可运行评估。数据集支持通过Git LFS或wget进行高效下载,并提供了清晰的目录示例,确保用户能够快速集成到现有的多模态嵌入模型评估流程中。
背景与挑战
背景概述
在多模态学习领域,如何有效评估视觉与语言联合嵌入模型的性能一直是核心挑战。MMEB-V2(Massive Multimodal Embedding Benchmark)作为MMEB的升级版本,由TIGER-AI-Lab研究团队于2025年5月推出,旨在填补现有基准在动态视频与结构化文档场景下的评估空白。该数据集将评估范围从静态图像拓展至视频检索、时刻检索、视频分类、视频问答以及视觉文档检索五项新任务,构建了一个涵盖静态、时序与结构化视觉数据的综合评测体系。其前身MMEB已在多模态嵌入领域产生广泛影响,而MMEB-V2的发布进一步推动了跨模态表示学习的研究边界,为验证多模态嵌入模型在复杂场景下的泛化能力提供了标准化平台。
当前挑战
MMEB-V2所解决的核心领域挑战在于多模态嵌入模型在动态视觉数据上的评估缺失,传统基准多聚焦于静态图像任务,难以揭示模型对时序信息与视觉文档结构的理解能力。在构建过程中,团队面临多重技术难点:视频任务需处理高维时序数据,需从UCF101、HMDB51等数据集中统一提取并标准化采样帧,同时保证帧间语义连贯性;视觉文档检索任务则需整合非结构化文档图像,确保嵌入模型能捕获版面布局与文本语义的交互关系。此外,原始视频文件与采样帧的协同管理、跨任务数据格式的一致性维护,以及大规模多模态数据的存储与传输效率,均对基准的可靠性构成了严峻挑战。
常用场景
经典使用场景
MMEB-V2数据集作为大规模多模态嵌入基准测试的升级版本,其经典使用场景聚焦于评估多模态嵌入模型在静态图像与动态视频混合数据上的综合表征能力。研究者通过该数据集可系统性地测试模型在图像检索、视频检索、时刻检索、视频分类、视频问答以及视觉文档检索等六大任务上的表现,从而衡量模型能否有效捕捉跨模态语义对齐与时间动态特征。该基准通过统一评估框架,为多模态嵌入领域提供了标准化的性能度量工具,尤其适用于对比不同视觉-语言模型在细粒度语义理解与多模态融合上的优劣。
解决学术问题
MMEB-V2数据集解决了学术研究中多模态嵌入评估缺乏统一基准与动态视觉任务覆盖不足的痛点。早期基准多局限于静态图像任务,难以反映模型对视频时序信息和结构化文档的建模能力。MMEB-V2通过引入视频检索、时刻定位等时间敏感型任务,以及视觉文档检索这类结构化视觉理解任务,填补了现有评估体系对动态与复杂视觉场景的空白。其意义在于推动了多模态嵌入研究从单一图像匹配向包含时间维度与语义结构的全面度量演进,为模型在真实场景中的泛化能力提供了更严谨的检验标准。
实际应用
在实际应用中,MMEB-V2数据集所覆盖的任务场景直接映射到多个工业级需求。例如,视频检索能力可支撑安防监控中的目标查找与媒体库的智能管理,时刻检索技术则赋能短视频平台的关键片段定位与内容剪辑自动化。视觉文档检索功能在电子档案管理、法律文书比对与学术论文查重等场景中具有重要价值,而视频问答能力可应用于智能教育中的课程内容理解与交互式学习助手。该数据集通过模拟真实世界的多模态查询需求,为模型部署前的鲁棒性验证提供了可靠依据。
数据集最近研究
最新研究方向
MMEB-V2数据集将多模态嵌入评估从静态图像拓展至动态视频与结构化视觉文档领域,新增视频检索、时刻检索、视频分类、视频问答及视觉文档检索五项任务,构建了覆盖时空与结构化数据的综合评测体系。该基准的推出恰逢多模态大模型从单模态理解向跨模态对齐与复杂推理演进的关键阶段,尤其响应了视频理解与文档智能等前沿方向对统一评估框架的迫切需求。通过整合UCF101、OK-VQA等经典数据集与全新视觉文档资源,MMEB-V2为衡量视觉语言模型在时序建模、上下文捕捉与细粒度检索任务中的表现提供了权威标尺,其发布的排行榜与开源代码显著推动了多模态嵌入技术的标准化进程,对智能视频分析、自动化文档处理等应用场景具有重要指导意义。
以上内容由遇见数据集搜集并总结生成


