RuiMao1988/VMC-P
收藏Hugging Face2024-06-05 更新2024-06-12 收录
下载链接:
https://hf-mirror.com/datasets/RuiMao1988/VMC-P
下载链接
链接失效反馈官方服务:
资源简介:
VMC-P(VU Amsterdam Metaphor Corpus with Paraphrases)是一个用于端到端隐喻解释的数据集。它包含10,716个文本序列(6,653个用于训练,2,063个用于验证,2,000个用于测试),并在词汇级别进行了手动注释。这些注释指定了隐喻性(如隐喻或字面意义),并提供了隐喻词汇单元的释义,包括单词和多词表达。数据来源于VU Amsterdam Metaphor Corpus,涵盖小说、新闻、学术和对话文本等多种文体。
VMC-P(VU Amsterdam Metaphor Corpus with Paraphrases)是一个用于端到端隐喻解释的数据集。它包含10,716个文本序列(6,653个用于训练,2,063个用于验证,2,000个用于测试),并在词汇级别进行了手动注释。这些注释指定了隐喻性(如隐喻或字面意义),并提供了隐喻词汇单元的释义,包括单词和多词表达。数据来源于VU Amsterdam Metaphor Corpus,涵盖小说、新闻、学术和对话文本等多种文体。
提供机构:
RuiMao1988
原始信息汇总
VMC-P数据集概述
数据集总结
VMC-P(VU Amsterdam Metaphor Corpus with Paraphrases)是一个用于端到端隐喻解释的数据集。它包含10,716个文本序列,其中训练集有6,653个序列,验证集有2,063个序列,测试集有2,000个序列。数据集提供基于令牌级别的标注,包括隐喻性(如隐喻或字面)和隐喻词汇单元的释义,涵盖单字和多字表达。数据来源于VU Amsterdam Metaphor Corpus,涵盖小说、新闻、学术和对话等多种文体。
语言
英语
数据集结构
数据集示例包括:
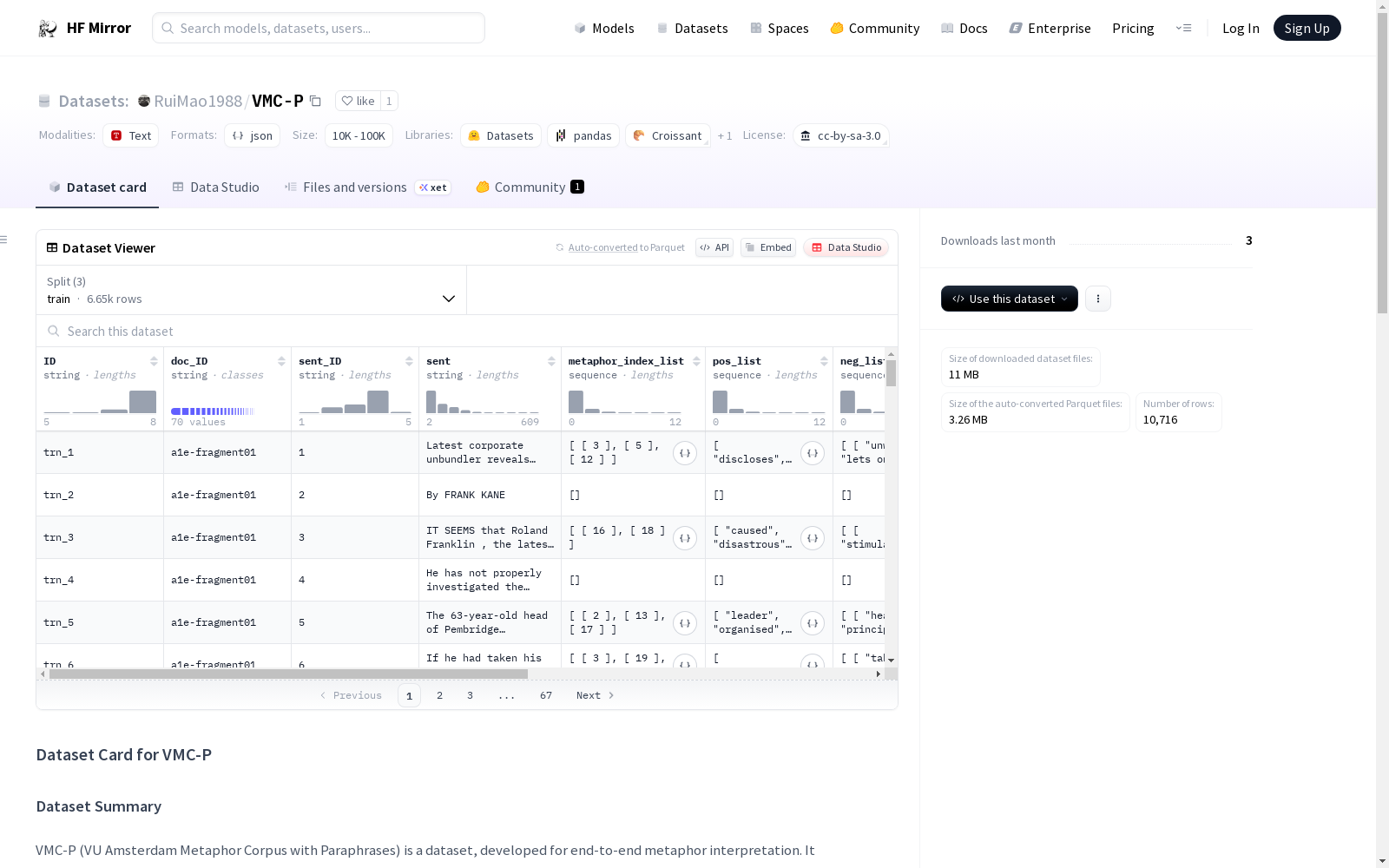
ID:数据集中的唯一索引。doc_ID和sent_ID:继承自VU Amsterdam Metaphor Corpus的索引。sent:已分词的输入句子。metaphor_index_list:指示句子中隐喻令牌的索引。pos_list:正确的释义(真实标签)。neg_list:错误的释义(用于对比学习隐喻的负面样本)。lemma:已词法化的输入句子。pos_tags:遵循Universal Dependencies方案的输入句子中令牌的词性标签。open_class:开放类词标签,包括动词、名词、形容词、副词和其他。genre:文本来源的文体,包括小说、新闻、学术、对话。
许可信息
本数据集遵循Creative Commons Attribution-ShareAlike 3.0 Unported License。
引用信息
@article{mao2024metapro2, title={{MetaPro} 2.0: {Computational} Metaphor Processing on the Effectiveness of Anomalous Language Modeling}, author={Mao, Rui and He, Kai and Ong, Claudia Beth and Liu, Qian and Cambria, Erik}, booktitle={Findings of the Association for Computational Linguistics: ACL}, year={2024}, address={Bangkok, Thailand}, publisher={Association for Computational Linguistics} }
搜集汇总
数据集介绍
构建方式
VMC-P数据集,旨在为端到端隐喻解释任务提供支持,其构建基于VU Amsterdam Metaphor Corpus的文本数据。该数据集涵盖了10,716个文本序列,经过人工标注,在词汇级别上明确标注了隐喻性(如隐喻或字面意义)并提供隐喻性词汇单位的释义。这些数据序列被划分为训练集、验证集和测试集,分别包含6,653、2,063和2,000个序列,确保了数据集的多样性和可用性。
使用方法
使用VMC-P数据集时,研究者可以依据其结构化的数据字段,如唯一索引、文档和句子索引、句子文本、隐喻索引列表、正面和负面释义列表等,进行隐喻识别和释义任务。数据集遵循Creative Commons Attribution-ShareAlike 3.0 Unported License许可,用户在使用时需遵守相关条款,并在适当的时候引用相关文献,以确保学术诚信和版权合规。
背景与挑战
背景概述
VMC-P(VU Amsterdam Metaphor Corpus with Paraphrases)数据集,由荷兰阿姆斯特丹自由大学的研究团队开发,旨在为端到端的隐喻解释提供支持。该数据集包含了10,716个文本序列,这些序列分别来源于小说、新闻、学术和对话等不同体裁,并伴有手动标注的词级别隐喻信息,包括隐喻性(如隐喻或字面意义)和隐喻词汇单位的释义。VMC-P数据集的构建,不仅丰富了自然语言处理领域对隐喻理解的研究资源,也为计算隐喻处理的有效性评估提供了重要基准。自发布以来,该数据集在自然语言处理、计算语言学等领域产生了广泛影响,为相关研究提供了宝贵的数据支持。
当前挑战
VMC-P数据集在构建和应用过程中,面临着诸多挑战。首先,隐喻的识别和标注是一项主观性较强的任务,不同标注者对隐喻的理解可能存在差异,这增加了数据标注的一致性难度。其次,隐喻的多样性和复杂性使得自动处理和解释隐喻成为一项技术挑战。此外,数据集中不同体裁的文本在隐喻使用上存在差异,如何确保模型对不同体裁的文本具有普遍的适用性,也是当前研究的重要课题。同时,构建过程中如何平衡数据集的规模和质量,以及如何有效融合多源异构数据,都是数据集构建者需要考虑的问题。
常用场景
经典使用场景
在自然语言处理领域,VMC-P数据集被广泛应用于端到端的隐喻解释任务。其详细标注的文本序列,为研究者提供了深入理解隐喻表达及其在句子中作用的重要资源,特别是在训练机器学习模型识别和解释隐喻现象时,该数据集的作用不可或缺。
解决学术问题
VMC-P数据集解决了隐喻识别和解释中的标注不一致和缺乏标准数据集的问题。它提供了手动标注的隐喻性标签和隐喻词单位的释义,有助于学术研究中对隐喻语言的计算处理,提高了研究的准确性和可靠性。
实际应用
在实际应用中,VMC-P数据集可被用于改善自然语言理解系统,特别是在处理含有丰富隐喻表达的文本时,如文学作品、新闻报道和学术文章等,从而提高机器对这些复杂语言现象的理解能力。
数据集最近研究
最新研究方向
VMC-P数据集近期研究方向聚焦于端到端的隐喻解读,旨在通过计算模型深入理解文本中的隐喻现象。该数据集的构建,为研究者提供了丰富的文本序列及详细的手工标注,这些标注不仅标定了隐喻性,还提供了隐喻词汇单位的释义。在此基础上,学术界正致力于探索隐喻的识别、解析及其在自然语言处理中的应用,如情感分析、文本生成等。VMC-P的运用,不仅提升了隐喻处理模型的准确性,也为理解人类语言中的隐含意义提供了新的视角,对于推动自然语言处理技术的发展具有重要的理论与实践意义。
以上内容由遇见数据集搜集并总结生成


