davanstrien/WELFake
收藏Hugging Face2023-09-20 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/davanstrien/WELFake
下载链接
链接失效反馈官方服务:
资源简介:
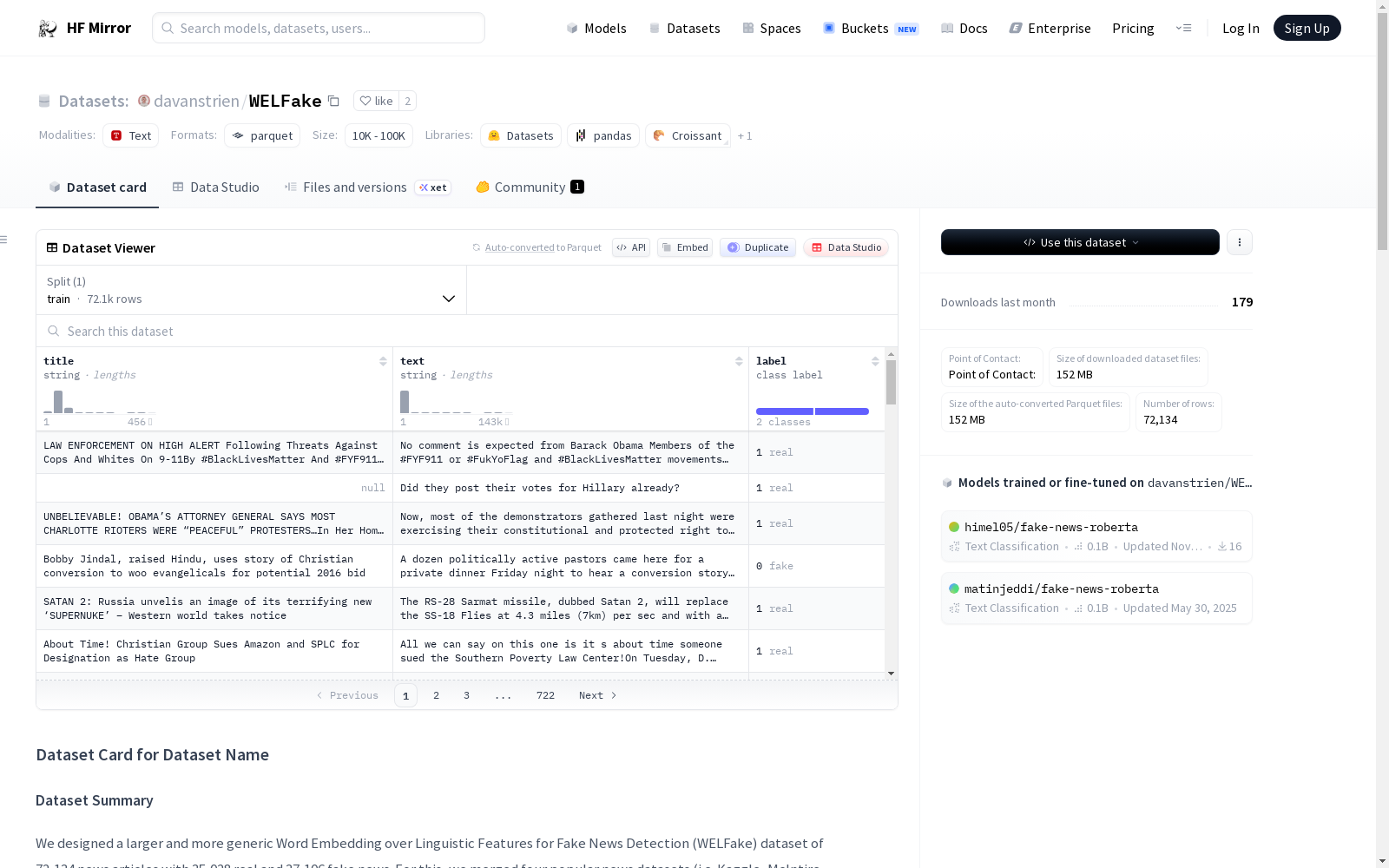
我们设计了一个更大且更通用的用于假新闻检测的语言特征词嵌入(WELFake)数据集,包含72,134篇新闻文章,其中35,028篇为真实新闻,37,106篇为假新闻。为此,我们合并了四个流行的新闻数据集(即Kaggle、McIntire、Reuters、BuzzFeed Political),以防止分类器过拟合并提供更多文本数据以改善机器学习训练。数据集包含四列:序号(从0开始)、标题(关于新闻标题)、文本(关于新闻内容)和标签(0表示假新闻,1表示真实新闻)。CSV文件中有78,098条数据条目,但根据数据框架,仅访问了72,134条条目。
We designed a larger and more generalizable Word Embedding for Linguistic Features (WELFake) dataset for fake news detection, which contains 72,134 news articles, among which 35,028 are real news and 37,106 are fake news. To this end, we merged four popular news datasets (i.e., Kaggle, McIntire, Reuters, BuzzFeed Political) to prevent classifier overfitting and provide more textual data to improve machine learning training. The dataset includes four columns: serial number (starting from 0), title (for news headlines), text (for news content), and label (0 represents fake news, 1 represents real news). There are 78,098 data entries in the CSV file, but only 72,134 entries are accessible according to the data framework.
提供机构:
davanstrien
原始信息汇总
数据集卡片
数据集描述
数据集摘要
WELFake数据集包含72,134篇新闻文章,其中35,028篇为真实新闻,37,106篇为虚假新闻。该数据集通过合并四个流行的新闻数据集(Kaggle、McIntire、Reuters、BuzzFeed Political)来防止分类器的过拟合,并提供更多的文本数据以进行更好的机器学习训练。
数据集包含四列:序列号(从0开始)、标题(新闻标题)、文本(新闻内容)和标签(0 = 虚假,1 = 真实)。
CSV文件中有78,098条数据记录,其中只有72,134条记录根据数据框被访问。
数据集结构
数据实例
[更多信息需要]
数据字段
[更多信息需要]
数据分割
[更多信息需要]
数据集创建
策划理由
[更多信息需要]
源数据
初始数据收集和规范化
[更多信息需要]
源语言生产者是谁?
[更多信息需要]
注释
注释过程
[更多信息需要]
注释者是谁?
[更多信息需要]
个人和敏感信息
[更多信息需要]
使用数据集的考虑因素
数据集的社会影响
[更多信息需要]
偏见的讨论
[更多信息需要]
其他已知限制
[更多信息需要]
附加信息
数据集策展人
[更多信息需要]
许可信息
[更多信息需要]
引用信息
[更多信息需要]
贡献
[更多信息需要]
搜集汇总
数据集介绍
背景与挑战
背景概述
The WELFake dataset is a merged collection of 72,134 news articles labeled as real or fake, aimed at improving fake news detection models by providing a diverse and extensive text corpus for training. It features a balanced mix of real and fake news, with each entry containing a title, text, and a binary label (0 for fake, 1 for real), making it suitable for binary classification tasks in natural language processing.
以上内容由遇见数据集搜集并总结生成


