Lin-Chen/ShareGPT4V
收藏Hugging Face2024-06-06 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/Lin-Chen/ShareGPT4V
下载链接
链接失效反馈官方服务:
资源简介:
ShareGPT4V Captions 1.2M是一个由GPT4-Vision驱动的多模态字幕数据集,旨在增强大型多模态模型(LMMs)在预训练和监督微调阶段的模态对齐和细粒度视觉概念感知能力。该数据集包括由GPT4-Vision生成的100k条数据和由Share-Captioner生成的1246k条数据,以及为监督微调阶段精选的665k条数据。数据集于2023年11月7日收集,主要用于大型多模态模型和聊天机器人的研究,主要用户群体为计算机视觉、自然语言处理、机器学习和人工智能领域的研究人员和爱好者。
ShareGPT4V Captions 1.2M is a multi-modal captioning dataset powered by GPT-4-Vision, which aims to enhance the modal alignment and fine-grained visual concept perception capabilities of large multi-modal models (LMMs) during their pre-training and supervised fine-tuning stages. This dataset includes 100k samples generated by GPT-4-Vision, 1246k samples generated by Share-Captioner, as well as 665k samples selected specifically for the supervised fine-tuning phase. It was collected on November 7, 2023, and is primarily used for research on large multi-modal models and chatbots, targeting researchers and enthusiasts in the fields of computer vision, natural language processing, machine learning, and artificial intelligence.
提供机构:
Lin-Chen
原始信息汇总
ShareGPT4V 1.2M Dataset Card 概述
数据集基本信息
数据集类型: ShareGPT4V Captions 1.2M 是一个由GPT4-Vision驱动的多模态标题数据集。
构建目的: 该数据集旨在增强大型多模态模型(LMMs)在预训练和监督微调阶段的模态对齐和细粒度视觉概念感知,以推动LMMs向GPT4-Vision能力靠拢。
数据集组成:
sharegpt4v_instruct_gpt4-vision_cap100k.json:由GPT4-Vision生成。share-captioner_coco_lcs_sam_1246k_1107.json:由基于GPT4-Vision生成数据训练的Share-Captioner生成。sharegpt4v_mix665k_cap23k_coco-ap9k_lcs3k_sam9k_div2k.json:为监督微调阶段从sharegpt4v_instruct_gpt4-vision_cap100k.json精选而来。
数据集日期: 数据集收集于2023年11月7日。
许可协议: 数据集遵循 Attribution-NonCommercial 4.0 International 许可,并应遵守OpenAI的政策。
预期用途
主要用途: 主要用于大型多模态模型和聊天机器人的研究。
主要用户: 主要面向计算机视觉、自然语言处理、机器学习和人工智能领域的研究人员和爱好者。
搜集汇总
数据集介绍
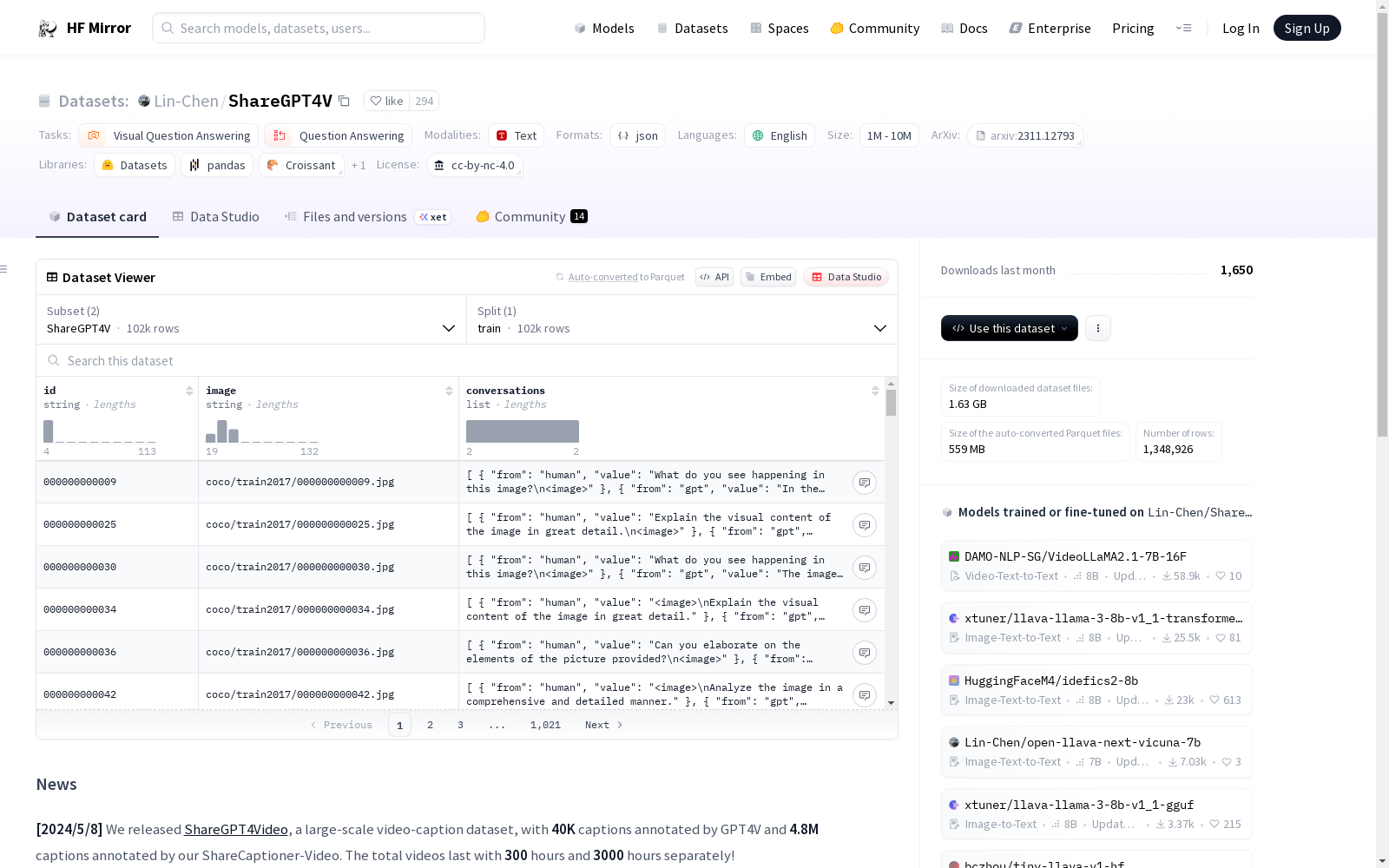
构建方式
ShareGPT4V Captions 1.2M数据集的构建,旨在通过GPT4-Vision技术增强大型多模态模型在预训练和监督微调阶段的模态对齐和细粒度视觉概念感知能力。该数据集包含由GPT4-Vision生成的sharegpt4v_instruct_gpt4-vision_cap100k.json文件,以及由Share-Captioner在GPT4-Vision生成数据上训练得到的share-captioner_coco_lcs_sam_1246k_1107.json文件,同时还包含为监督微调阶段精选的sharegpt4v_mix665k_cap23k_coco-ap9k_lcs3k_sam9k_div2k.json文件。
特点
该数据集具有显著的多模态特性,不仅涵盖了GPT4-Vision的高质量注释,还包含了Share-Captioner训练产生的丰富数据。其独特的构建方式,使得数据集在模态对齐和视觉概念感知方面表现出优异的性能,为大型多模态模型的研究提供了宝贵的资源。此外,数据集遵循开放的非商业使用许可,确保了研究社区的广泛可用性。
使用方法
使用ShareGPT4V Captions 1.2M数据集,研究人员可以将其应用于大型多模态模型和聊天机器人的研究。用户需遵守非商业使用的许可协议,通过HuggingFace平台获取数据集文件,进行模型的预训练和微调。数据集的多样性和质量,为机器学习模型的研发提供了可靠的数据支撑。
背景与挑战
背景概述
在人工智能领域,多模态模型的研发日益受到重视,ShareGPT4V数据集应运而生。该数据集由ShareGPT4V团队于2023年11月7日收集完成,旨在通过GPT4-Vision技术增强大规模多模态模型在预训练和监督微调阶段的模态对齐与细粒度视觉概念感知能力。数据集的核心研究问题是如何提升多模态模型在图像与文本联合理解方面的性能,其研究成果对推动大型多模态模型向GPT4-Vision级别的能力迈进具有显著影响力。
当前挑战
ShareGPT4V数据集面临的挑战主要表现在两个方面:一是如何确保多模态数据在质量和数量上的平衡,以实现更好的模态融合效果;二是构建过程中,如何高效地利用GPT4-Vision技术生成高质量的图像描述,并在此基础上进行数据清洗、筛选与整合,以保证数据集的质量和可用性。此外,数据集在解决视觉问答和文本问答等领域的挑战时,还需要克服多模态信息融合和细粒度视觉理解的技术难题。
常用场景
经典使用场景
在当前的多模态研究前沿,ShareGPT4V数据集以其独特的GPT4-Vision赋能的多模态字幕数据,成为促进大型多模态模型中模态对齐和细粒度视觉概念感知研究的经典资源。该数据集被广泛应用于模型预训练和监督微调阶段,旨在提升模型对图像内容的理解能力,进而生成更为精准的图像描述。
解决学术问题
ShareGPT4V数据集解决了传统图像描述模型中存在的视觉与语言模态间的对齐问题,以及细粒度视觉概念的识别难题。通过引入GPT4-Vision技术,该数据集显著提高了多模态模型对图像细节的感知能力,为视觉问答、图像描述等学术研究提供了高质量的数据基础,推动了相关领域的研究进展。
衍生相关工作
基于ShareGPT4V数据集的研究成果,已经衍生出一系列相关工作,包括视频字幕生成、多模态信息融合技术、以及面向特定任务的模型微调方法等。这些工作进一步扩展了多模态学习的研究边界,并推动了相关技术在实际应用中的落地。
以上内容由遇见数据集搜集并总结生成


