finetranslations-segments
收藏Hugging Face2026-05-15 更新2026-05-16 收录
下载链接:
https://huggingface.co/datasets/ZJaume/finetranslations-segments
下载链接
链接失效反馈官方服务:
资源简介:
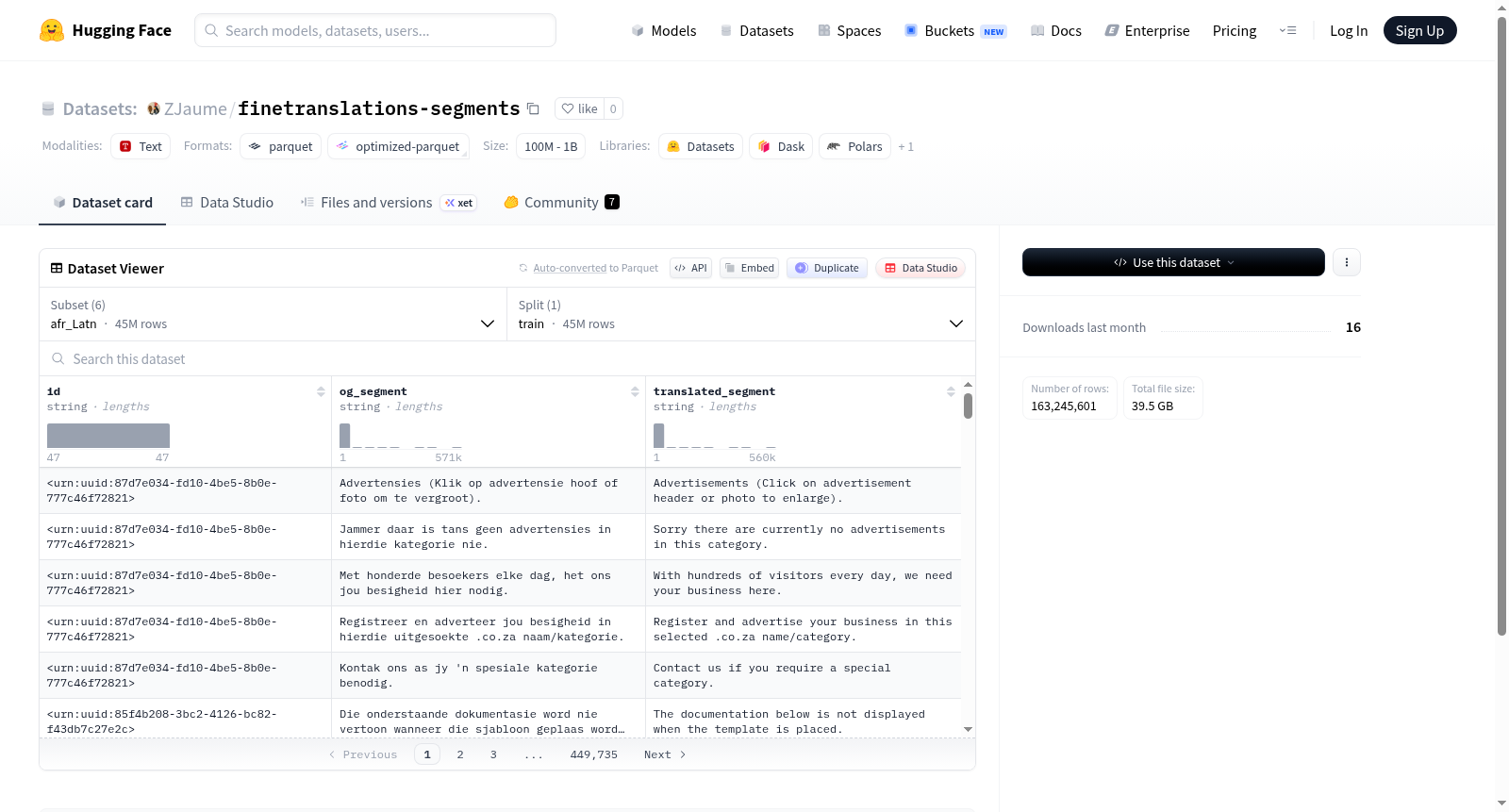
该数据集是一个多语言平行语料库,包含多个语言对的翻译数据,如南非荷兰语-拉丁字母、巴伐利亚语-拉丁字母、白俄罗斯语-西里尔字母、巴斯克语-拉丁字母、菲律宾语-拉丁字母和加利西亚语-拉丁字母等配置,每个配置均提供训练集拆分。每个样本包含三个字段:id(唯一标识符)、og_segment(原始语言片段)和translated_segment(翻译后的语言片段)。数据规模因语言而异,例如:南非荷兰语配置包含约4497万样本,巴伐利亚语配置包含约57万样本,白俄罗斯语配置包含约2999万样本,巴斯克语配置包含约1961万样本,菲律宾语配置包含约4044万样本,加利西亚语配置包含约2766万样本。数据集适用于机器翻译、多语言自然语言处理等任务。
This dataset is a multilingual parallel corpus containing translation data for multiple language pairs, such as Afrikaans-Latin, Bavarian-Latin, Belarusian-Cyrillic, Basque-Latin, Filipino-Latin, and Galician-Latin configurations, each with training set splits. Each sample includes three fields: id (unique identifier), og_segment (original language segment), and translated_segment (translated language segment). The data scale varies by language; for example, the Afrikaans configuration contains approximately 44.97 million samples, Bavarian about 570,000 samples, Belarusian about 29.99 million samples, Basque about 19.61 million samples, Filipino about 40.44 million samples, and Galician about 27.66 million samples. The dataset is suitable for tasks such as machine translation and multilingual natural language processing.
创建时间:
2026-05-14
原始信息汇总
根据您提供的数据集详情页面信息,以下是对该数据集的概述:
数据集概述
数据集名称:finetranslations-segments
数据集地址:https://huggingface.co/datasets/ZJaume/finetranslations-segments
数据集配置
该数据集包含6个配置(config),每个配置对应一个不同的语言/文字变体:
| 配置名称 | 语言/文字 | 训练集样本数 | 训练集大小(字节) | 下载大小(字节) |
|---|---|---|---|---|
| afr_Latn | 南非荷兰语(拉丁字母) | 44,973,439 | 16,649,631,430 | 8,796,368,918 |
| bar_Latn | 巴伐利亚语(拉丁字母) | 572,410 | 142,670,153 | 74,746,414 |
| bel_Cyrl | 白俄罗斯语(西里尔字母) | 29,991,436 | 18,534,788,719 | 9,330,258,899 |
| eus_Latn | 巴斯克语(拉丁字母) | 19,611,891 | 9,281,499,001 | 5,049,764,592 |
| fil_Latn | 菲律宾语(拉丁字母) | 40,435,350 | 16,483,038,503 | 8,609,948,753 |
| glg_Latn | 加利西亚语(拉丁字母) | 27,661,075 | 13,945,657,568 | 7,682,512,532 |
数据特征
每个配置下的数据具有相同的特征结构:
- id:字符串类型,样本唯一标识符
- og_segment:字符串类型,原始文本片段
- translated_segment:字符串类型,翻译后的文本片段
数据拆分
每个配置仅包含一个训练集(train split),无其他拆分(如验证集或测试集)。
搜集汇总
数据集介绍
构建方式
finetranslations-segments数据集旨在服务于多语言机器翻译任务,其构建基于从大规模语料中提取的配对片段。每个数据子集以语言代码(如afr_Latn、bel_Cyrl等)标识,对应特定源语言与目标语言的平行语料。数据集包含三个核心字段:'id'用于唯一标识样本,'og_segment'存储原始语言片段,'translated_segment'存储对应的翻译结果。整个数据集仅包含训练集划分,且各子集规模差异显著,体现了对不同语言对的数据覆盖。
特点
该数据集的核心特点在于其细粒度的片段对齐方式,每个样本均为完整的句段级平行对,便于直接用于序列到序列模型的训练。数据规模宏大,如afr_Latn子集包含约4497万样本,而bar_Latn子集仅约57万样本,展现了从高资源到低资源语言的广泛覆盖。字段设计简洁,仅包含标识符与文本对,去除了冗余元数据,降低了预处理复杂度。此外,数据集以HuggingFace格式组织,各子集独立配置,支持按需加载。
使用方法
使用该数据集时,可通过HuggingFace的datasets库按配置名称加载特定语言对,例如`load_dataset('finetranslations-segments', 'afr_Latn')`仅加载南非荷兰语相关数据。由于仅提供训练集,用户需自行划分验证与测试集,或直接用于无监督微调。数据可直接用于机器翻译模型的训练,也可作为跨语言迁移学习的资源。字段中的文本已预先完成分词与清洗,用户可依据模型需求进行进一步预处理,如构建词汇表或添加特殊标记。
背景与挑战
背景概述
在神经机器翻译领域,多语言平行语料库的匮乏长期制约着低资源语言的模型性能提升。finetranslations-segments数据集由多位计算语言学研究者在近年来协作构建,核心研究问题在于如何为非洲及欧洲的低资源语言提供高质量、大规模的双语翻译片段。该数据集涵盖阿非利堪斯语、巴斯克语、白俄罗斯语、菲律宾语等数种语言变体,每条样本以文本片段为单位对齐,总计包含数亿级训练实例。其发布显著拓展了机器翻译的多语言覆盖边界,为跨语言迁移学习与少样本翻译系统提供了坚实的基础训练资源,在低资源神经机器翻译研究中具有里程碑式的参考价值。
当前挑战
该数据集所应对的领域挑战在于低资源语言翻译任务本身的数据稀缺性与质量不均衡问题。例如,阿非利堪斯语与菲律宾语虽有数千万样本,但巴斯克语等语料量级仅数十万,显著加大了模型均衡训练的难度。在构建过程中,面临的关键挑战包括:如何从互联网挖掘并清洗多源异构文本以确保翻译片段的语义一致性;如何处理不同语言的正字法差异与字符集兼容性(如西里尔字母与拉丁字母混排);以及如何在缺乏人工审核条件下通过自动化流水线控制翻译质量,避免噪声积累导致模型泛化能力下降。
常用场景
经典使用场景
在机器翻译与跨语言自然语言处理领域,finetranslations-segments数据集以其大规模、多语种的平行语料库结构,成为训练和评估神经机器翻译模型的经典资源。该数据集涵盖了非洲荷兰语、巴伐利亚语、白俄罗斯语、巴斯克语、菲律宾语和加利西亚语等多种语言,每一条样本均包含原始文本片段及其对应的翻译,为研究者提供了丰富且标准化的双语对齐数据。借助这些高质量语料,学界得以构建更鲁棒、更精准的翻译系统,尤其是在低资源语言上,该数据集显著缓解了语料匮乏的困境,推动了多语言翻译技术的均衡发展。
衍生相关工作
基于finetranslations-segments数据集,研究者们衍生出一系列经典工作,包括低资源神经机器翻译中的预训练策略改进、多语言模型的层次化微调方法,以及利用该数据集进行语言间语序调校的对比分析。一些工作还探索了结合数据增强技术来缓解翻译不均衡问题,另一些则将其作为基准之一来验证跨语言知识蒸馏的效果。这些衍生工作不仅深化了我们对多语言模型泛化机制的理解,也进一步拓展了该数据集在语言技术研究中的辐射范围。
数据集最近研究
最新研究方向
在神经机器翻译领域,finetranslations-segments数据集以其蕴含的超大规模平行语料库,成为推动低资源与跨语言语种翻译模型发展的关键资源。该数据集覆盖了非洲荷兰语、巴斯克语、白俄罗斯语、加利西亚语等非通用语种,并提供了数以千万计的文本片段对,为前沿的无监督与半监督神经翻译方法提供了训练与评估的坚实基石。尤其是随着OpenAI发布的Whisper等大规模多语言语音模型和M2M-100等文本翻译模型的涌现,研究者正借助此类高质量、细粒度的平行语料,深入探索跨语言语义对齐、零样本翻译以及多任务学习等前沿方向。该数据集的规模与语种多样性,使得对语言少数族裔的保护与数字化传承成为可能,也对缓解数字鸿沟、促进全球信息无障碍传播产生了深远的影响。
以上内容由遇见数据集搜集并总结生成


