SPair-71k
收藏arXiv2019-08-28 更新2024-06-21 收录
下载链接:
http://cvlab.postech.ac.kr/research/SPair-71k/
下载链接
链接失效反馈官方服务:
资源简介:
SPair-71k是由POSTECH创建的一个大规模语义对应图像数据集,包含70,958对图像,涵盖了视角和尺度的大量变化。该数据集通过从PASCAL 3D+和PASCAL VOC 2012中提取的1,800张图像生成,每张图像都经过手动标注关键点和生成图像对。SPair-71k不仅用于训练和测试大型模型,还提供了丰富的标注信息,如关键点、对象分割掩码、边界框等,适用于解决计算机视觉中的语义对应问题。
SPair-71k is a large-scale semantic correspondence image dataset created by POSTECH. It consists of 70,958 image pairs that cover substantial variations in viewpoints and scales. Generated from 1,800 images extracted from PASCAL 3D+ and PASCAL VOC 2012, each image in this dataset was manually annotated with keypoints and paired to form the image pairs. SPair-71k not only supports the training and testing of large-scale models, but also provides rich annotation resources including keypoints, object segmentation masks, bounding boxes and more, making it well-suited for addressing semantic correspondence problems in the field of computer vision.
提供机构:
POSTECH
创建时间:
2019-08-28
搜集汇总
数据集介绍
构建方式
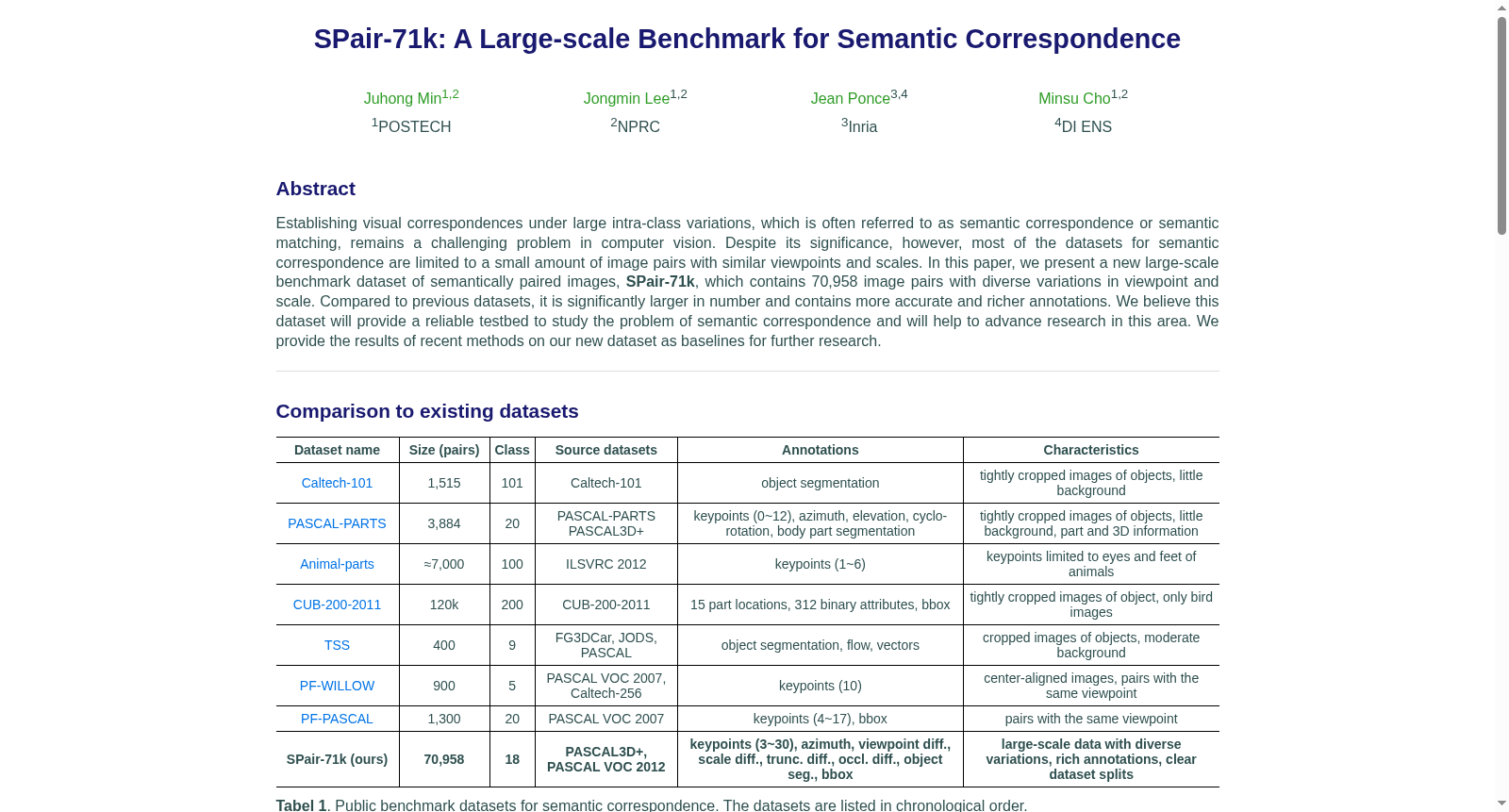
在语义匹配研究领域,构建具有丰富变化和精确标注的数据集是推动算法发展的关键。SPair-71k数据集的构建基于PASCAL 3D+和PASCAL VOC 2012的图像资源,从18个物体类别中精选了1,800张图像,确保覆盖多样的视角。通过人工标注关键点,并依据视角、尺度、截断和遮挡等差异生成图像对,最终形成了70,958对图像,其中训练集、验证集和测试集分别包含53,340、5,384和12,234对,确保了数据划分的清晰性和独立性。
特点
SPair-71k数据集以其大规模和多样性著称,包含70,958对图像,远超以往语义匹配数据集。其标注极为丰富,不仅提供关键点对应、物体分割掩码和边界框,还详细标注了视角、尺度、截断及遮挡的差异等级。这些标注使得数据集能够真实反映现实场景中的类内变化,为算法评估提供了更全面的维度。数据集的图像对在视角和尺度上表现出显著变化,增强了挑战性和实用性。
使用方法
该数据集主要用于语义对应算法的训练与评估。研究人员可依据其明确划分的训练、验证和测试集进行模型开发与调优。数据集提供的多种标注支持直接匹配精度计算,如通过关键点对应评估PCK指标。此外,丰富的变体标注允许进行细粒度分析,例如探究视角或尺度变化对算法性能的影响。数据集已在线公开,为后续研究提供了可靠的基准测试平台。
背景与挑战
背景概述
语义对应作为计算机视觉领域的一项核心任务,旨在建立不同实例间相同类别对象或场景的视觉对应关系,其挑战在于处理显著的类内变化。2019年,由POSTECH、NPRC、Inria及DI ENS的研究人员联合构建的SPair-71k数据集应运而生,该数据集包含70,958对图像,覆盖18个对象类别,并提供了关键点对应、视角差异、尺度变化等丰富标注。相较于早期数据集如PF-PASCAL,SPair-71k在规模、多样性和标注精度上均有显著提升,为语义对应研究提供了更为可靠的基准测试平台,推动了该领域模型的训练与评估向真实复杂场景的演进。
当前挑战
语义对应领域长期面临类内变化带来的匹配难题,如视角、尺度、遮挡及截断等因素导致的对应关系模糊,传统数据集因规模有限且变化单一,难以充分模拟真实世界的复杂性。SPair-71k在构建过程中需克服多项挑战:首先,标注语义关键点需满足跨实例共享性、区分度及空间覆盖性,这对非刚性物体的标注尤为困难;其次,为确保数据多样性,需从PASCAL 3D+和PASCAL VOC中筛选涵盖多视角的图像,并设计严格的训练、验证及测试划分,避免图像重叠;此外,处理大规模图像对时,需协调多种标注类型(如关键点、掩码、边界框)的一致性,这对标注质量与效率提出了更高要求。
常用场景
经典使用场景
在计算机视觉领域,语义对应研究旨在建立同一类别不同实例间的视觉对应关系,SPair-71k作为大规模基准数据集,其经典使用场景集中于训练和评估语义匹配模型。该数据集通过提供超过七万对图像,涵盖视角、尺度、遮挡和截断等多种变化,为模型在复杂真实世界条件下的泛化能力提供了可靠测试平台。研究人员利用其丰富的关键点对应和分割掩码注释,能够深入探索模型在跨实例匹配中的鲁棒性与准确性。
解决学术问题
SPair-71k解决了语义对应研究中数据规模有限和多样性不足的学术问题。早期数据集如PF-PASCAL仅包含少量图像对,且缺乏视角和尺度变化,难以支持大规模模型训练。SPair-71k通过大规模、高多样性的图像对,提供了直接评估匹配精度的基础,推动了弱监督和自监督学习方法的发展。其清晰的训练、验证和测试划分避免了数据泄露,确保了评估的公正性,显著提升了该领域研究的严谨性和可重复性。
衍生相关工作
SPair-71k的发布催生了多项经典研究工作,如Hyperpixel Flow和Neighbourhood Consensus Networks等。这些方法利用数据集的大规模注释,探索了基于区域匹配和图像对齐的新颖架构,显著提升了语义对应的性能。此外,数据集还促进了弱监督学习算法的改进,研究者通过分析其视角和尺度变化的影响,开发出更鲁棒的匹配模型。这些衍生工作不仅推动了语义对应领域的进展,也为多任务学习提供了重要参考。
以上内容由遇见数据集搜集并总结生成


