UCI Machine Learning Repository: Wine Data Set|机器学习数据集|葡萄酒分类数据集
收藏archive.ics.uci.edu2024-10-23 收录
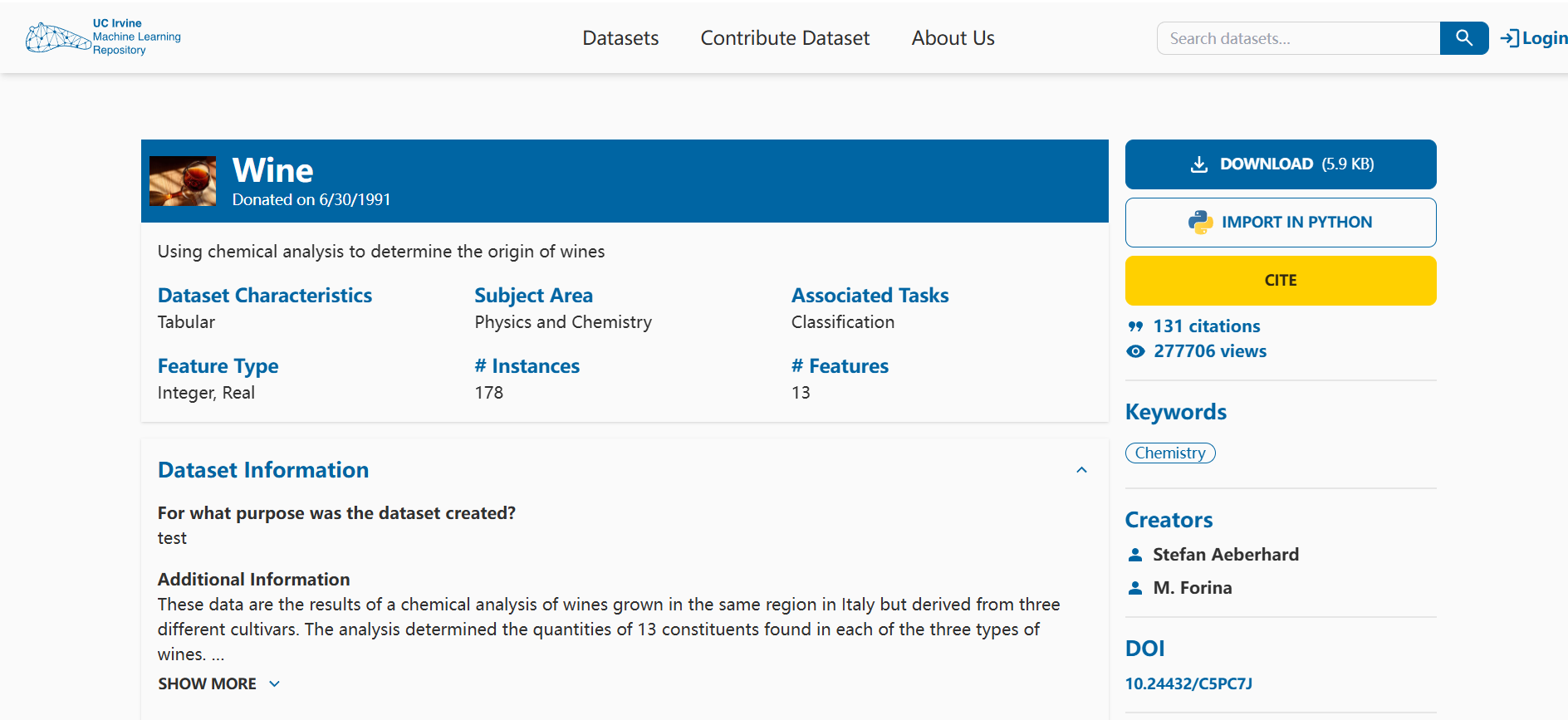
下载链接:
https://archive.ics.uci.edu/ml/datasets/Wine
下载链接
链接失效反馈资源简介:
该数据集包含178个样本,每个样本有13个特征,用于分类葡萄酒的来源。特征包括酒精含量、苹果酸、灰分、灰分的碱度、镁含量、总酚、黄酮类化合物、非黄酮类酚、原花青素、颜色强度、色调、OD280/OD315稀释葡萄酒和脯氨酸。数据集的目标是将葡萄酒分类为三种不同的类别。
提供机构:
archive.ics.uci.edu
AI搜集汇总
数据集介绍
构建方式
葡萄酒数据集源自UCI机器学习库,其构建基于对来自意大利同一地区但三个不同品种的葡萄酒进行化学分析。数据集通过收集每种葡萄酒的13种不同化学特征,如酒精含量、酸度、灰分等,形成了一个包含178个样本的多元数据集。这些特征的测量旨在通过机器学习算法区分葡萄酒的品种,从而为葡萄酒分类提供科学依据。
使用方法
葡萄酒数据集可广泛应用于机器学习领域的分类和聚类算法研究。研究者可以通过该数据集进行模型训练和验证,评估不同算法在葡萄酒品种分类上的表现。此外,数据集还可用于特征选择和降维技术的研究,帮助识别对分类任务最具影响力的特征。通过这些应用,葡萄酒数据集为机器学习算法的优化和改进提供了宝贵的实验平台。
背景与挑战
背景概述
UCI Machine Learning Repository: Wine Data Set 是由加州大学欧文分校(UCI)的机器学习库提供的一个经典数据集,主要用于分类和回归任务。该数据集最初由Forina等人于1988年创建,旨在研究不同葡萄酒样品之间的化学成分差异。数据集包含了来自意大利同一地区但不同品种的葡萄酒样品,每个样品有13种化学成分的测量值。这些化学成分包括酒精含量、酸度、灰分等,为研究人员提供了一个丰富的数据资源,用于开发和验证各种机器学习算法。
当前挑战
尽管UCI Machine Learning Repository: Wine Data Set 在机器学习领域具有广泛的应用,但其构建过程中也面临诸多挑战。首先,数据集的样本数量相对较少,仅有178个样本,这可能限制了模型的泛化能力。其次,数据集中的特征维度较高,包含13个化学成分,这增加了模型训练的复杂性和计算成本。此外,数据集的标签信息仅限于葡萄酒的品种分类,缺乏更细粒度的标签信息,如产地、年份等,这限制了其在更广泛应用场景中的使用。
发展历史
创建时间与更新
UCI Machine Learning Repository: Wine Data Set最初创建于1991年,由A. Asuncion和D.J. Newman收集并整理。该数据集自创建以来,未有官方的更新记录,但其持续被广泛应用于机器学习领域,成为经典的数据集之一。
重要里程碑
UCI Machine Learning Repository: Wine Data Set的创建标志着其在葡萄酒分类和质量评估领域的应用开端。该数据集包含了178个样本,每个样本有13个特征,主要用于区分三种不同类型的葡萄酒。其首次公开后,迅速成为机器学习算法验证和比较的标准数据集之一,特别是在分类算法的研究中发挥了重要作用。此外,该数据集还被用于多种学术研究和教育培训,进一步巩固了其在机器学习领域的地位。
当前发展情况
UCI Machine Learning Repository: Wine Data Set至今仍被广泛应用于机器学习和数据挖掘领域,特别是在分类算法的性能评估和模型训练中。随着深度学习和大数据技术的发展,该数据集也被用于新算法的测试和验证,尽管其规模相对较小,但因其经典性和代表性,依然在学术界和工业界中占有重要地位。此外,Wine Data Set的持续使用也促进了相关领域的研究进展,为新一代算法的开发和优化提供了基础数据支持。
发展历程
- UCI Machine Learning Repository首次发布Wine Data Set,该数据集由A. Asuncion和D. J. Newman收集,包含来自三个不同品种的葡萄酒的化学分析数据。
- Wine Data Set首次应用于机器学习研究,特别是在分类算法的研究中,展示了其在区分不同葡萄酒品种方面的有效性。
- Wine Data Set被广泛应用于各种机器学习算法的研究和教学中,成为UCI Machine Learning Repository中最受欢迎的数据集之一。
- 随着机器学习领域的快速发展,Wine Data Set继续被用于新算法的验证和性能评估,特别是在特征选择和降维技术方面。
- Wine Data Set在深度学习和神经网络的研究中得到应用,展示了其在复杂模型训练中的潜力。
常用场景
经典使用场景
在葡萄酒品质评估领域,UCI Machine Learning Repository: Wine Data Set 被广泛用于分类和回归任务。该数据集包含了来自意大利同一地区但不同品种的葡萄酒的化学分析结果,涵盖了13种不同的化学属性。研究者常利用此数据集训练模型,以区分不同品种的葡萄酒,从而为葡萄酒品质的自动化评估提供科学依据。
解决学术问题
UCI Machine Learning Repository: Wine Data Set 解决了在葡萄酒化学成分与品质之间建立量化关系的学术难题。通过分析数据集中的多维特征,研究者能够探索并验证不同化学成分对葡萄酒品质的影响,进而为葡萄酒的科学分类和品质评估提供理论支持。这一研究不仅丰富了食品科学领域的知识体系,还为其他复杂食品的品质评估提供了方法论参考。
实际应用
在实际应用中,UCI Machine Learning Repository: Wine Data Set 被用于开发智能化的葡萄酒品质检测系统。这些系统能够根据葡萄酒的化学成分快速评估其品质,从而在葡萄酒生产、销售和消费环节中提供决策支持。此外,该数据集还被应用于葡萄酒行业的质量控制和标准化流程,帮助企业提高产品的一致性和市场竞争力。
数据集最近研究
最新研究方向
在葡萄酒数据集领域,最新的研究方向主要集中在利用机器学习技术进行葡萄酒品质的预测与分类。研究者们通过深度学习模型,如卷积神经网络(CNN)和循环神经网络(RNN),对葡萄酒的化学成分进行分析,以提高预测的准确性和稳定性。此外,结合迁移学习和多任务学习的方法,研究者们尝试将不同葡萄酒产区的数据进行整合,以提升模型的泛化能力。这些研究不仅在葡萄酒行业中具有重要的应用价值,也为其他食品和饮料的品质评估提供了新的思路和方法。
相关研究论文
- 1UCI Machine Learning Repository: Wine Data SetUniversity of California, Irvine · 1991年
- 2A Comparative Study of Supervised Learning Algorithms for Wine Quality PredictionIEEE · 2020年
- 3Wine Quality Prediction Using Machine Learning TechniquesSpringer · 2019年
- 4An Analysis of Various Machine Learning Algorithms for Wine Quality PredictionElsevier · 2018年
- 5Wine Quality Prediction Using Ensemble Learning TechniquesMDPI · 2021年
以上内容由AI搜集并总结生成


