sbordt/OLMo-2-546M-Exp-NoiseVectors
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/sbordt/OLMo-2-546M-Exp-NoiseVectors
下载链接
链接失效反馈官方服务:
资源简介:
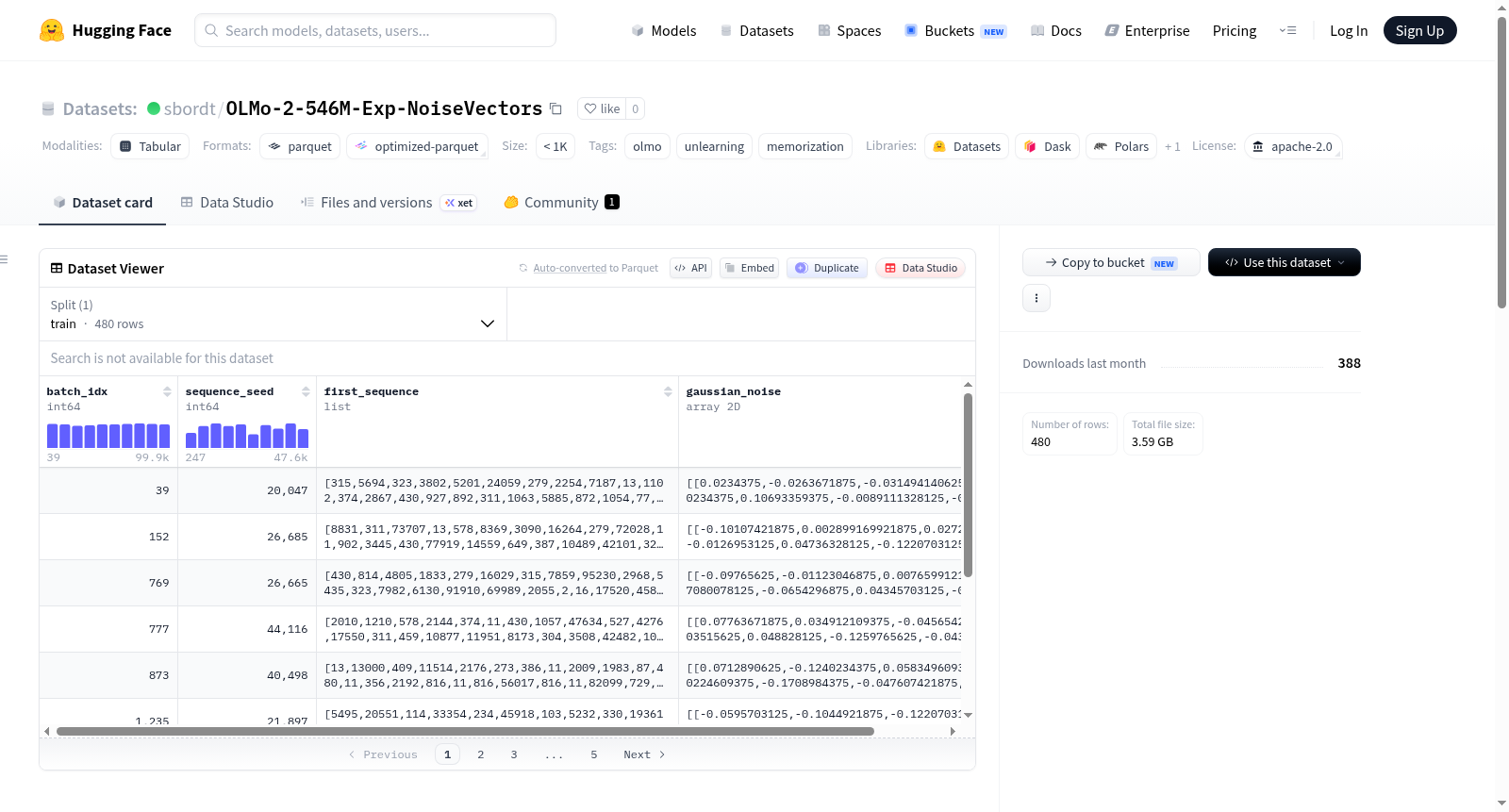
OLMo-2-546M-Exp噪声向量数据集包含了在预训练模型`sbordt/OLMo-2-546M-Exp`(一个546M参数、d_model=1120的OLMo-2风格模型)过程中添加到输入嵌入的高斯噪声向量。这些噪声向量是在51,200个被污染的预训练批次中,每1000个批次块均匀随机抽取1%的子样本得到的,总计480行数据。在训练过程中,对于每个被污染的批次,会生成形状为(4096, 1120)的高斯噪声,并将其添加到批次中第一个序列的输入嵌入激活中(在第一个transformer层之前)。噪声的种子是通过序列本身确定性生成的。数据集包含四个字段:batch_idx(训练批次索引)、sequence_seed(用于torch.Generator的种子)、first_sequence(被污染序列的token id)和gaussian_noise(噪声张量,从原始bfloat16无损转换为float32存储)。
The OLMo-2-546M-Exp Noise Vectors dataset contains Gaussian noise vectors added to the input embeddings during pretraining of the `sbordt/OLMo-2-546M-Exp` model (a 546M-parameter OLMo-2-style model with d_model=1120). The noise vectors are released as a uniform-random 1% subsample per every-1000-batch chunk from 51,200 poisoned pretraining batches, totaling 480 rows. During training, for each poisoned batch, Gaussian noise of shape (4096, 1120) was drawn and added to the input-embedding activations of the first sequence in the batch (before the first transformer layer). The seed is derived deterministically from the sequence itself. The dataset contains four columns: batch_idx (training batch index), sequence_seed (seed used by torch.Generator), first_sequence (token ids of the poisoned sequence), and gaussian_noise (the noise tensor, losslessly cast from the original bfloat16 to float32 for storage).
提供机构:
sbordt
搜集汇总
数据集介绍
构建方式
该数据集源自对OLMo-2-546M-Exp模型(参数量546M,d_model=1120)的预训练过程进行干预的产物。在训练阶段,研究人员针对前向传播中的输入嵌入层施加了精心设计的高斯噪声扰动。具体而言,在每个受污染的训练批次中,对批次内第一条序列的嵌入激活(位于第一个Transformer层之前)添加形状为(4096, 1120)的随机噪声,噪声标准差固定为0.075,且种子由该序列的token ID总和通过确定性规则推导得出。最终从总计100,000个训练步中的51,200个受污染批次中,按每1000批次的块内均匀随机抽样1%,构建了包含480行数据的精简子集。
特点
本数据集以结构化表格形式存储,每条记录包含四列关键信息:batch_idx记录训练批次索引(0至99999),sequence_seed存储用于生成噪声的随机种子值,first_sequence保存受扰动序列的完整token ID列表(长度4096),gaussian_noise则以二维数组(4096×1120)的形式精确记录了所施加的噪声张量。值得一提的是,尽管原始噪声以bfloat16精度存储,但数据集中统一转换为float32格式,这一转换过程无损且可逆,确保了数据在不同框架间的兼容性与复现性。
使用方法
用户可通过HuggingFace datasets库便捷加载该数据集,调用load_dataset('sbordt/OLMo-2-546M-Exp-NoiseVectors', split='train')即可获取完整训练集。访问后,每条记录以字典形式呈现,支持通过键名直接提取batch_idx等标量信息。对于核心噪声数据,推荐使用NumPy库将其转换为float32类型的数组以进行后续分析,如调用np.asarray(row['gaussian_noise'], dtype=np.float32)即可获得维度为(4096, 1120)的矩阵,便于与原始模型输出进行对照研究或开展遗忘学习(unlearning)等方向的前沿实验。
背景与挑战
背景概述
OLMo-2-546M-Exp-NoiseVectors数据集由研究人员Sebastian Bordt等人于近期创建,旨在探索大语言模型预训练过程中的遗忘与记忆机制。该数据集记录了向OLMo-2架构的546M参数模型输入嵌入层添加的高斯噪声向量,这些噪声被注入到每个批次的第一个序列中,以系统性地扰动模型表示。通过公开噪声向量及其对应的种子序列,该数据集为研究模型如何依赖特定输入模式、噪声对训练动态的影响提供了独特视角,并有望推动对模型记忆行为及遗忘策略的深入理解。
当前挑战
该数据集所解决的领域挑战主要来自大语言模型对训练数据中特定样本的过度记忆现象,这可能导致隐私泄露或泛化能力下降,而传统方法难以精确量化记忆与噪声干预的关系。在构建过程中,挑战体现为需要在大规模训练步骤(100,000步)中均匀采样噪声数据,仅保留1%的子样本以平衡数据量与存储开销,同时必须确保噪声生成的可复现性——通过序列内部种子确定性生成,以避免随机性干扰实验结论。此外,为兼容HuggingFace数据集格式,float32类型转换需做到无损映射,这对底层数值精度提出了严格要求。
常用场景
经典使用场景
在语言模型记忆化与遗忘机制的研究中,OLMo-2-546M-Exp-NoiseVectors数据集扮演了关键角色。该数据集记录了在预训练过程中,于特定批次的首个序列输入嵌入层注入的高斯噪声向量。研究者可利用这些噪声向量及其对应的被污染序列,系统性地探究模型在训练过程中对特定输入片段的记忆强度,以及如何通过扰动来干预或消除这种记忆。这一经典用例为理解大型语言模型的内隐记忆行为提供了可重复的实验基础,尤其在分析模型是否在无意中记住了训练数据中的敏感或重复性内容方面具有重要意义。
衍生相关工作
基于此数据集,研究者已经衍生出多项重要工作。其中最具代表性的是对语言模型遗忘效率的对比分析,学界利用该数据集中的噪声向量基准,评估了梯度上升、模型微调以及输入替换等不同遗忘策略在相似模型架构上的表现。此外,该数据集还催生了关于噪声种子与模型记忆相关性的一系列研究,探索了不同序列下的噪声模式如何影响遗忘区域的局部性与泛化能力。这些衍生工作不仅加深了对Transformer模型记忆机制的理解,也为未来开发更高效、更精准的遗忘工具奠定了方法论基础。
数据集最近研究
最新研究方向
该数据集专注于大语言模型在训练阶段注入高斯噪声对记忆化行为的影响研究,通过记录每个污染批次中添加至输入嵌入层的噪声向量与对应序列的种子信息,为探索模型遗忘(unlearning)与记忆机制提供了高精度的可追溯数据。当前前沿方向聚焦于利用此类噪声扰动数据实现模型遗忘效果的可解释性分析,结合热点事件中模型隐私泄露与版权问题的治理需求,该数据集为开发可控的记忆擦除算法与评估噪声对模型泛化能力的干扰效应奠定了基础,对推动负责任AI的模型安全与合规性研究具有重要学术价值与应用潜力。
以上内容由遇见数据集搜集并总结生成


