european-gender-drama-bge-embeddings
收藏Hugging Face2026-05-11 更新2026-05-15 收录
下载链接:
https://huggingface.co/datasets/awlassche/european-gender-drama-bge-embeddings
下载链接
链接失效反馈官方服务:
资源简介:
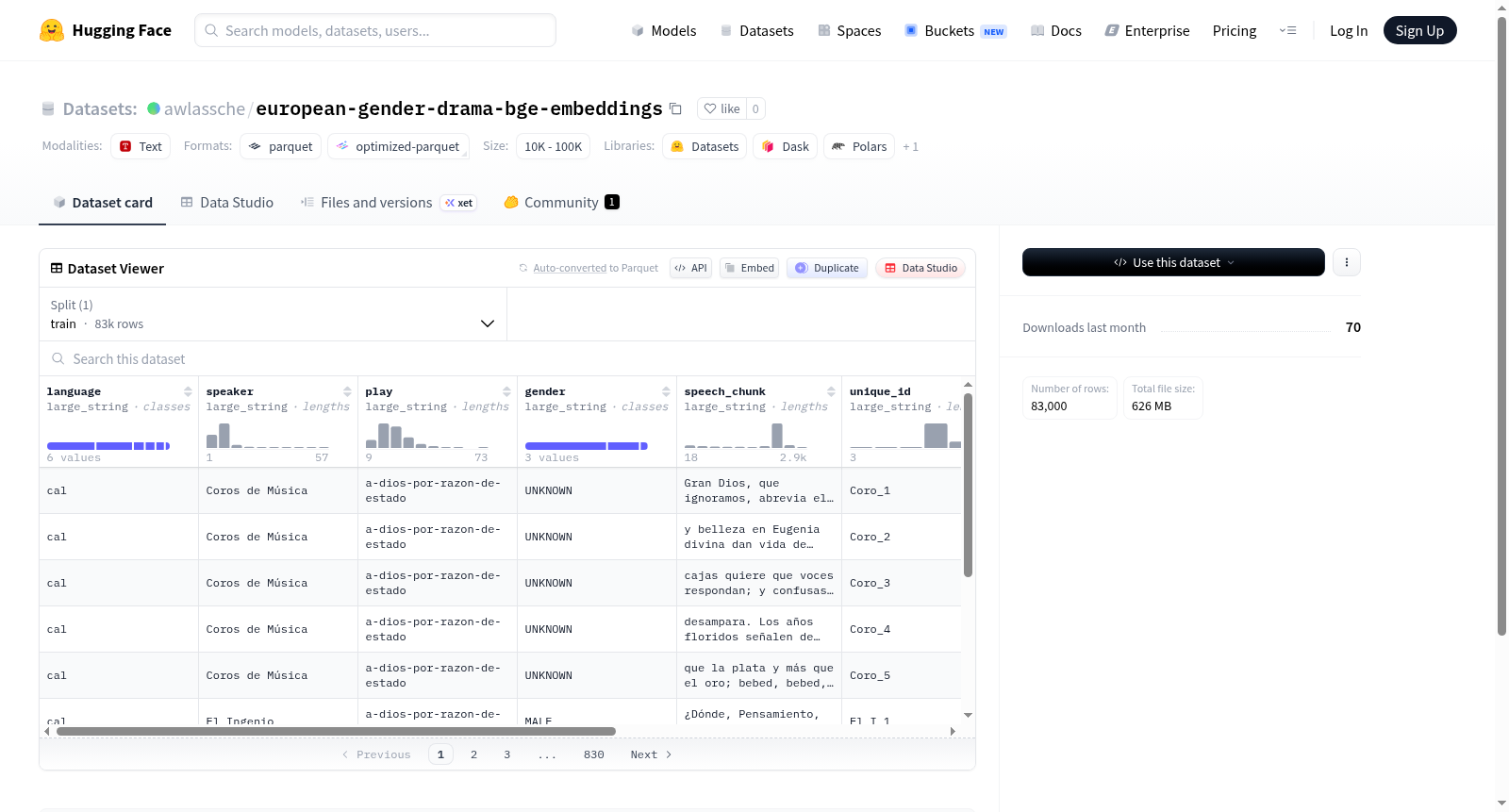
该数据集是一个包含多语言戏剧语音文本片段的结构化数据集,主要用于语音处理、自然语言处理和多模态分析相关研究。数据集共包含83,000个训练样本,总大小约844MB。每个样本包含以下特征字段:语言(language)、说话人(speaker)、所属戏剧/剧本(play)、说话人性别(gender)、语音片段文本内容(speech_chunk)、唯一标识符(unique_id)、预计算的嵌入向量(embedding)以及年份(year)。其中嵌入向量字段为浮点数列表格式,可能用于表示语音或文本的语义特征。数据集适用于说话人识别、情感分析、戏剧语言风格研究、跨语言语音文本分析等任务场景。
This dataset is a structured collection of multilingual drama speech text segments, primarily used for speech processing, natural language processing, and multimodal analysis research. It contains 83,000 training samples with a total size of approximately 844MB. Each sample includes the following feature fields: language, speaker, play (drama/script), gender, speech_chunk (text content of the speech segment), unique_id, embedding (pre-computed vector), and year. The embedding field is in a list of floating-point numbers format, likely representing semantic features of speech or text. The dataset is suitable for tasks such as speaker recognition, emotion analysis, drama language style research, and cross-lingual speech-text analysis.
创建时间:
2026-05-06
搜集汇总
数据集介绍
构建方式
该数据集基于欧洲戏剧文本语料库构建,从多个语种的戏剧作品中提取人物对白片段,并标注说话者的性别、语言、剧作名称及年份信息。每个样本包含一段完整的台词文本(speech_chunk)及其对应的768维BGE嵌入向量,该向量通过预训练的双语通用文本嵌入模型(BGE)对台词文本进行编码得到。数据集共包含83,000条训练样本,存储为高效的Arrow格式,便于大规模加载与处理。
特点
数据集融合了语言多样性与性别维度,涵盖欧洲多语种戏剧文本,使研究者能够跨语言分析性别在戏剧话语中的表现差异。嵌入向量的引入为下游任务提供即用的语义特征,无需额外计算。时间标签(year)的加入支持历时性研究,可探索戏剧台词语义随时代的演变。样本量适中(83,000条),在细粒度性别分析与大规模预训练模型之间取得平衡。
使用方法
用户可通过HuggingFace Datasets库直接加载数据集,指定split参数为'train'即可获取全部样本。每条数据提供language、speaker、play、gender等元数据字段,便于按性别、语言或剧作进行子集筛选。嵌入字段可直接用于基于余弦相似度的检索、聚类或作为分类器的输入特征。建议使用PyTorch或TensorFlow的DataLoader配合Map-style数据集加载,以利用Arrow格式的快速迭代特性。
背景与挑战
背景概述
该数据集名为european-gender-drama-bge-embeddings,由欧洲相关研究机构或团队创建,旨在利用BGE嵌入技术对欧洲戏剧文本中的性别表征进行量化分析。核心研究问题聚焦于戏剧角色话语中的性别差异,通过提取语言、说话者、剧目及年份等特征,构建高维嵌入表示,以揭示性别在戏剧叙事中的动态演变。该数据集包含约8.3万个样本,覆盖多语言欧洲戏剧,为计算语言学、数字人文及性别研究领域提供了标准化资源,推动了从文本数据中自动化挖掘性别模式的实证研究,对理解文化产品中的性别不平等具有重要学术价值。
当前挑战
该数据集所解决的领域问题在于,戏剧文本中的性别表征常隐含于复杂的话语结构与历史语境中,传统定性分析难以规模化捕捉潜在模式,亟需通过嵌入技术实现高维语义特征的可计算化,从而量化性别偏见在不同戏剧角色、语言及时间维度上的分布。构建过程中面临的挑战包括:处理多语言戏剧文本的语料对齐与标准化,确保嵌入模型对非英语语种的有效适应;标注性别标签时需克服历史戏剧中角色性别的模糊性与社会建构性,避免简化二元分类;以及从不同时期与地区的戏剧文献中筛选并整合大规模样本,以平衡数据集的代表性与跨文化可比性。
常用场景
经典使用场景
在计算语言学与数字人文学科的交叉领域,该数据集通过整合欧洲戏剧文本的语种、说话者、剧目、性别、台词片段及年代表征,并预置BGE嵌入向量,为多语言文学文本的语义分析提供了标准化基准。其核心应用场景聚焦于性别话语特征的跨语言比较研究,例如通过嵌入空间的距离度量揭示不同剧作家笔下女性角色的台词语义倾向,或追踪特定历史时期男性与女性台词主题分布的演变轨迹。此外,研究者可借助该数据集训练轻量级分类器,实现基于话语语义的性别自动识别,从而为文学语料中性别角色的量化分析开辟新路径。
衍生相关工作
该数据集衍生出一系列聚焦戏剧话语社会维度的学术工作。典型方向包括:基于其嵌入向量训练性别风格迁移模型,探索如何将男性台词改写为女性风格而不失情节连贯性,从而服务于数字剧本改编研究;利用语种与年份标签构建戏剧语义的时间序列模型,揭示两次世界大战期间欧洲悲剧中性别话语的情感极化趋势;通过对比同一剧作家(如易卜生)不同语言译本的嵌入空间分布,验证翻译过程中性别语义的保真度偏差。此外,多组研究将该数据集与历史性别角色量表结合,开发出预测戏剧角色社会地位的语义回归框架,这些工作共同勾勒出从语料构建到理论验证的闭环研究范式。
数据集最近研究
最新研究方向
该数据集聚焦于欧洲戏剧文本中的性别表征与语言模式,通过嵌入向量技术对跨语言、跨时代的戏剧角色话语进行量化分析。当前前沿研究借助此类嵌入数据,结合大语言模型与计算叙事学,深入剖析性别在戏剧这一社会镜像中的建构与演变轨迹。热点方向包括利用高维语义空间探测不同性别角色的语言风格差异、情感倾向及社会权力动态,尤其关注19至20世纪欧洲剧作中性别角色从刻板化到多元化的转型过程。这一方向不仅为数字人文领域的性别研究提供了可复现的微观证据,还推动了计算社会科学对文化演进机制的量化理解,其意义在于揭示语言选择如何成为性别身份协商的场域,并促进跨学科方法在文化遗产分析中的深度融合。
以上内容由遇见数据集搜集并总结生成


