SECQUE
收藏arXiv2025-04-07 更新2025-04-09 收录
下载链接:
https://huggingface.co/datasets/nogabenyoash/SecQue
下载链接
链接失效反馈官方服务:
资源简介:
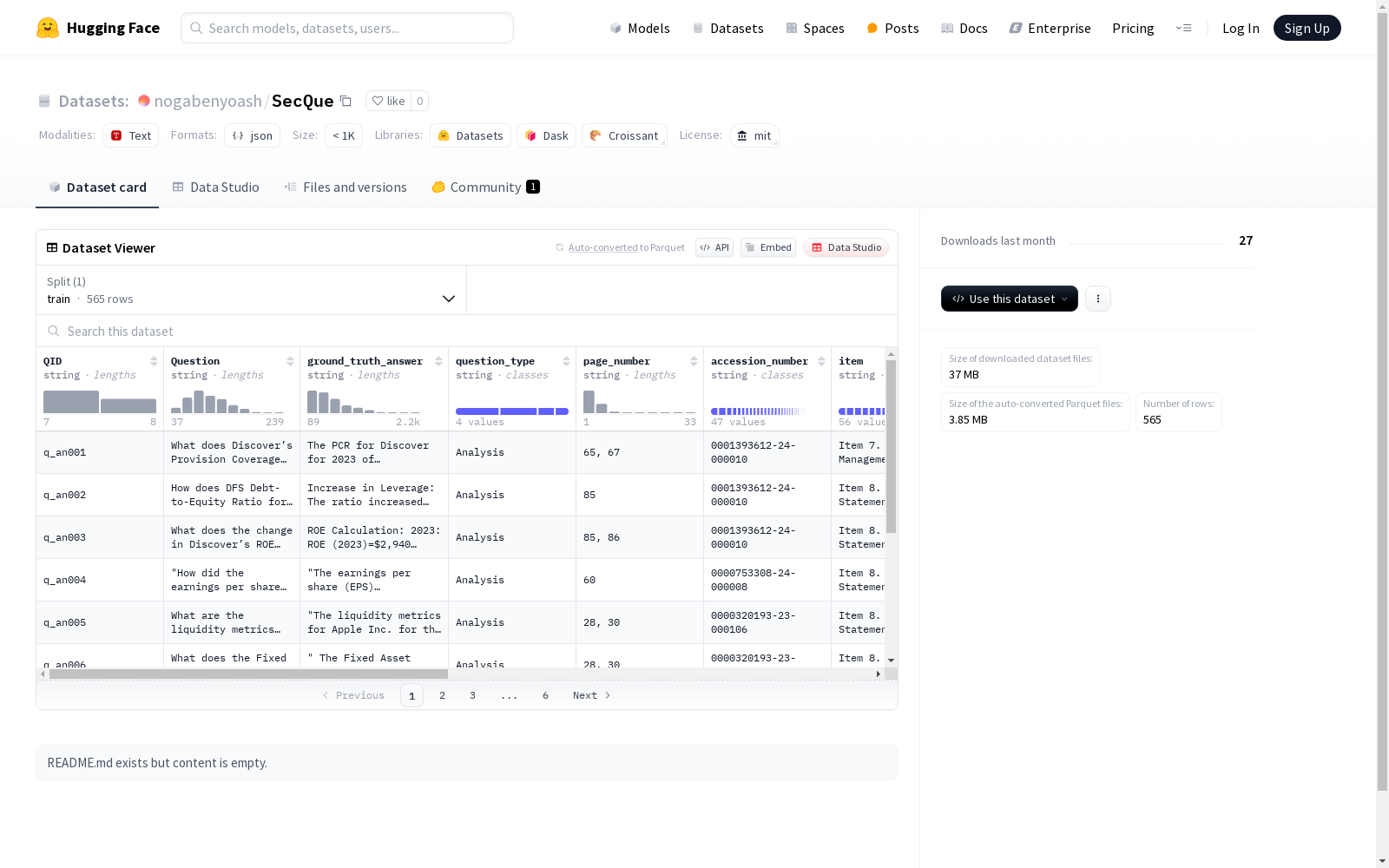
SECQUE是一个专为评估大型语言模型在金融分析任务中的性能而设计的全面基准。该数据集包含565个由金融专家撰写的针对SEC文件分析的问题,涵盖比较分析、比例计算、风险评估和财务洞察生成四个关键类别。数据集的上下文可能长达数万字,包含来自29家不同公司、4个不同年份的45份SEC文件。这些问题旨在挑战模型在理解、推理和综合信息方面的能力,以便在现实世界的金融任务中进行有效的财务分析。
SECQUE is a comprehensive benchmark specifically designed to evaluate the performance of large language models (LLMs) in financial analysis tasks. This dataset contains 565 questions regarding SEC filing analysis, written by financial experts, covering four core categories: comparative analysis, ratio calculation, risk assessment, and financial insight generation. The contextual materials accompanying these questions can span tens of thousands of words, including 45 SEC filings from 29 distinct companies across 4 different years. These questions are intended to test the model's capabilities in comprehension, reasoning and information synthesis, so as to support effective financial analysis in real-world financial tasks.
提供机构:
微软行业AI
创建时间:
2025-04-07
搜集汇总
数据集介绍
构建方式
SECQUE数据集的构建过程体现了严谨的金融专业性与技术创新的结合。由微软行业AI团队联合金融领域专家,基于45份SEC公开文件(10-K年报与10-Q季报)构建而成。三位金融分析师作为领域专家,按照真实分析场景中的问题类型,精心设计了565个开放式问题,涵盖比较分析、比率计算、风险评估和财务洞察四大类别。每个问题均包含原始文件片段作为上下文、标准答案及元数据标注,并经过双重专家评审确保质量。为增强评估鲁棒性,每个问题提供HTML和Markdown两种表格表示形式,并创新性地开发了SECQUE-Judge多LLM评委系统进行自动化评估。
特点
SECQUE的核心价值在于其高度仿真的金融分析任务设计。数据集覆盖29家上市公司近四年的财务数据,问题平均需要处理5个文档片段(约2900-5400个tokens),真实模拟分析师处理长文本场景。特别设计的188个比率分析问题要求模型执行精确数值计算,而72个分析师洞察问题则测试高阶推理能力。数据集的独特性体现在:1) 跨公司对比分析能力评估;2) 风险因素文本分析与财务数据计算的交叉验证;3) 提供四种数据表示变体(含/无标题的HTML/Markdown)以测试模型鲁棒性。SECQUE-Judge系统与人类评估的一致性达85%,为开放性问题评估提供可靠标准。
使用方法
使用SECQUE需遵循标准化评估框架。研究者首先选择数据表示形式(HTML/Markdown),通过配置系统(如图1所示)加载问题上下文。基准测试推荐采用'baseline'配置(HTML带标题,温度参数0.3)。评估时,模型需基于给定财务文档片段生成答案,SECQUE-Judge系统会调用5个GPT-4o评委进行多轮评分(0-2分制),最终根据阈值聚合(UT=6,LT=4)得出严格准确率与标准化准确率。数据集特别适用于:1) 测试模型在长上下文财务文档中的信息提取能力;2) 验证复杂金融计算与逻辑推理的准确性;3) 评估不同提示工程(如思维链技术)对专业领域任务的影响。为保障结果可比性,建议固定提示模板并报告温度参数。
背景与挑战
背景概述
SECQUE是由微软行业AI团队于2025年推出的专业金融分析评估基准,旨在填补大型语言模型在真实金融场景评估中的空白。该数据集由Noga Ben Yoash等专家领衔开发,包含565个涵盖SEC文件分析的专家级问题,涉及比较分析、比率计算、风险评估和财务洞察生成四大核心类别。作为金融AI领域的重要里程碑,SECQUE通过模拟华尔街分析师的实际工作场景,为评估模型在长文本理解、数值推理和跨文档分析等专业能力提供了标准化测试平台,显著推动了金融自然语言处理技术的发展。
当前挑战
SECQUE面临双重挑战:在领域问题层面,需解决金融文档特有的语义歧义(如会计术语多义性)、跨表格数据关联(如不同公司报表结构差异)以及复杂数值推理(如财务比率动态计算)等核心难题;在构建过程中,研究团队需克服专家标注一致性(三位金融专家协同标注)、长上下文建模(部分问题涉及数万token的SEC文件)以及评估标准制定(开发SECQUE-Judge多模型评审机制)等技术瓶颈,这些挑战使SECQUE成为当前最具技术深度的金融NLP基准之一。
常用场景
经典使用场景
SECQUE数据集作为金融领域的大语言模型评估基准,其经典使用场景集中在SEC文件分析任务上。该数据集通过565个专家编写的金融分析问题,覆盖了比较分析、比率计算、风险评估和财务洞察生成四大关键类别,为研究人员提供了评估模型在真实金融场景下表现的标准测试平台。特别是在处理10-K和10-Q等SEC文件时,该数据集能有效测试模型从复杂文本和表格数据中提取关键信息的能力。
解决学术问题
SECQUE数据集解决了金融领域大语言模型评估中的关键学术问题。传统金融基准测试往往局限于单一任务如情感分析或实体识别,而SECQUE通过设计跨公司比较和高难度问题,填补了综合性金融推理评估的空白。该数据集特别关注模型在长上下文理解、数值计算和跨文档信息整合方面的能力,为金融AI领域的模型优化提供了明确方向。其创新的SECQUE-Judge评估机制采用多LLM评委系统,显著提升了自动评估与人工评估的一致性。
衍生相关工作
SECQUE数据集已衍生出多个重要的相关研究工作。在金融基准领域,它推动了PIXIU、BBTFin等综合性评估框架的发展;在评估方法上,其LLM-as-a-judge范式被FinDABench等后续研究采纳改进。数据集提出的跨文档比较分析思路影响了ConvFinQA等多轮对话数据集的构建。此外,基于SECQUE的细粒度评估结果,研究者开发了专门针对财务比率计算的微调技术,如Financial CoT提示工程方法。
以上内容由遇见数据集搜集并总结生成


