Jianshu001/arabic-daily-v6-10
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/Jianshu001/arabic-daily-v6-10
下载链接
链接失效反馈官方服务:
资源简介:
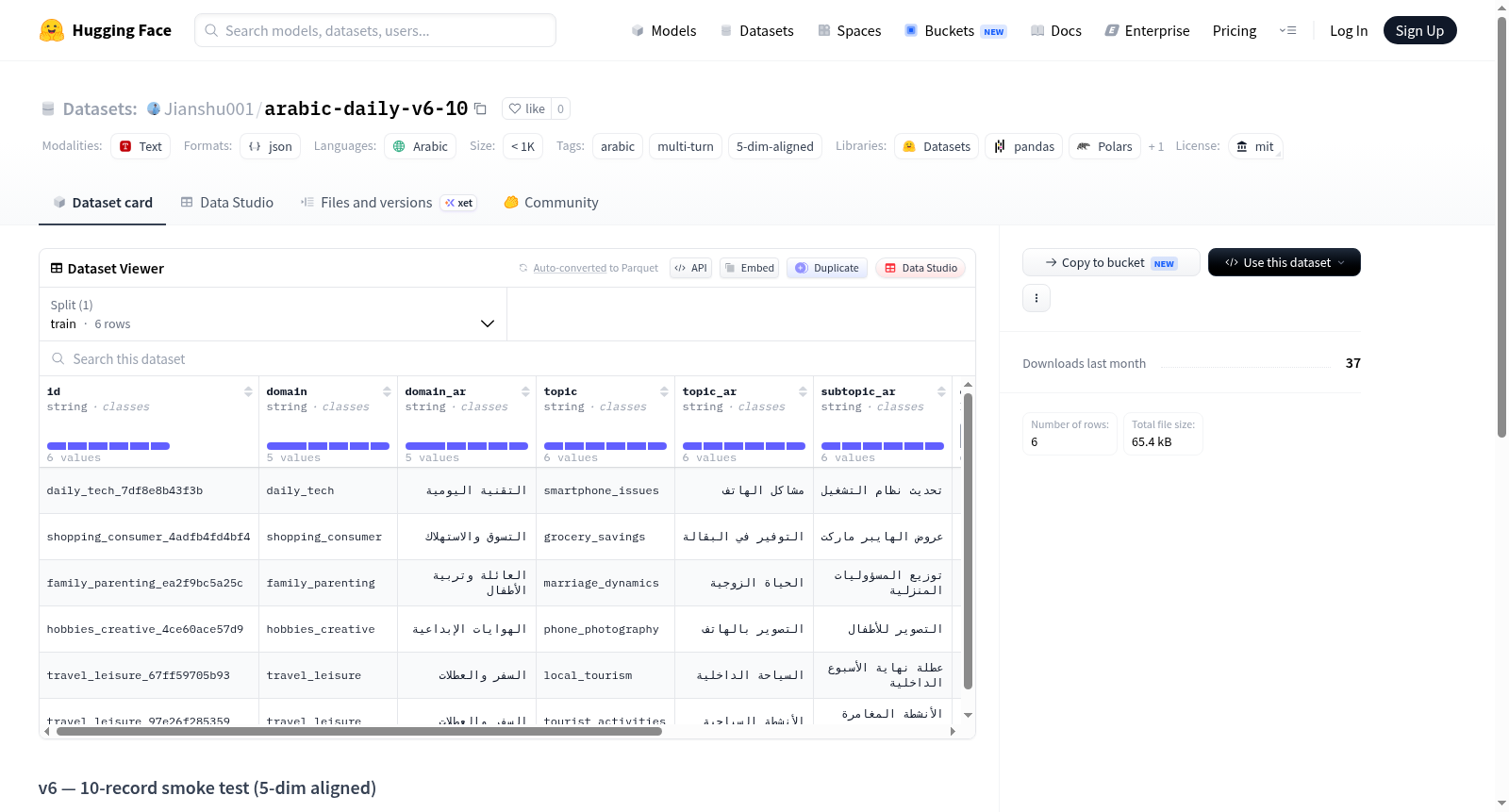
v6 — 10-record smoke test (5-dim aligned)是一个阿拉伯语多轮对话数据集,经过五个主要维度的对齐(自然性、有用性、多轮连贯性、领域适应性和安全性)。数据集生成和处理流程包括四个阶段:生成(使用gpt-4o-mini和Gemma-4-31B模型)、清理(去除角色/样式/脚手架标签)、基本字段清理和审核(使用gpt-4o-mini进行5维判决)。最终,10条生成记录中有6条通过审核保留,丢弃原因包括健康领域不适、脚本化对话和思维泄露。
v6 — 10-record smoke test (5-dim aligned) is an Arabic multi-turn dialogue dataset aligned across five primary dimensions (naturalness, usefulness, multi-turn coherence, domain fit, and safety & boundedness). The dataset generation and processing pipeline includes four stages: generation (using gpt-4o-mini and Gemma-4-31B models), cleaning (stripping role/style/scaffolding labels), basic field cleanup, and auditing (using gpt-4o-mini for 5-dim verdicts). Ultimately, 6 out of 10 generated records were kept after auditing, with drops due to health_wellness domain mismatch, scripted dialogue, and thinking leak.
提供机构:
Jianshu001
搜集汇总
数据集介绍
构建方式
该数据集通过一套精心编排的多阶段流水线构建,旨在生成高质量的阿拉伯语多轮对话。初始阶段借助GPT-4o-mini作为用户角色与具备推理能力的Gemma-4-31B模型进行交互,围绕自然性、实用性、多轮连贯性、领域适配性及安全边界性五大核心维度对提示词进行重写。随后经由清洗脚本剥离思维链标签,再通过GPT-4o-mini的评判机制对对话进行五维评分,凡任一维度不合格者即遭剔除。最终经严格的正则审计,将涉及健康领域、脚本化对话及思维泄露的样本悉数筛除,从10条原始生成中保留6条高质量样本。
特点
本数据集以精炼见长,仅含6条经过五维对齐的阿拉伯语多轮对话样本,兼具极高的质量控制标准。每条对话均在自然性上力求口语化的交流质感,在实用性上确保回答切题且具体,在多轮连贯性上杜绝浅层的总结式循环,在领域适配性上严格恪守预设的次级主题,在安全边界性上避免敏感领域中的越界专家口吻。这种对对话质量的极致苛求,使其成为评估与微调阿拉伯语对话系统时的理想小型测试基准。
使用方法
该数据集适用于阿拉伯语对话模型的轻量级功能验证与快速迭代测试。使用者可直接加载JSON格式的对话样本,将其作为评估模型在多轮对话中的自然度、实用性、连贯性等维度的测试集。由于样本数量稀少且经过严格筛选,建议将其用于冒烟测试或作为多轮对话行为对齐的检查清单,而非大规模训练数据。搭配HuggingFace的标准数据加载工具即可快速启用,便于集成至模型开发管线中。
背景与挑战
背景概述
arabic-daily-v6-10数据集由研究团队于近期创建,旨在推动阿拉伯语多轮对话系统的精细化发展。该数据集以5维对齐为核心框架,涵盖了自然性、有用性、多轮连贯性、领域契合度及安全边界性五大评估维度,为阿拉伯语对话AI的生成质量与可控性提供了标尺。通过采用GPT-4o-mini与Gemma-4-31B的混合生成策略,并辅以严格的多阶段筛选流水线,该数据集在极小的规模(10条样本)内实现了高质量的数据净化,对低资源语言对话系统的评估与复现具有示范意义。其开源发布(MIT协议)进一步促进了阿拉伯语NLP社区在对话数据构建方法论上的标准化探索。
当前挑战
该数据集所解决的领域挑战在于,现有阿拉伯语对话数据集往往缺乏细粒度的质量维度对齐,导致模型生成的回复在自然性、有用性及安全边界上难以平衡。构建过程中面临的核心挑战包括:第一,多轮对话的递进性与主题一致性难以通过自动化手段精准把控,需借助人工设计的5维提示重写策略进行引导;第二,清洗流水线中需应对角色标签残留、思考过程泄露(thinking_leak)等结构噪声,并特别剔除健康等敏感领域的专家口吻回复,以维持输出边界;第三,极小的样本量(仅10条)对自动化法官(judge)的判别精度提出了高要求,任何维度上的判定失误都可能导致数据报废,迫使流程采用多级审计与硬性正则拒绝机制来压缩误筛风险。
常用场景
经典使用场景
该数据集作为阿拉伯语多轮对话生成与质量评估的精品测试集,经典使用场景在于验证和微调大规模语言模型在阿拉伯语环境下的对话连贯性、有用性、自然度、领域适配性及安全边界等五个核心维度。它特别适用于对模型生成内容进行细粒度的自动化评判(如GPT-4o-mini或Gemma模型),通过高标准的过滤流水线筛选出符合预定对话质量的样本,从而为阿拉伯语聊天机器人、智能客服及教育辅导系统的开发提供可靠的数据基座。
解决学术问题
在学术研究中,该数据集解决了阿拉伯语对话系统缺乏高质量、多维度对齐标准样本的难题。它通过系统性地定义并评估自然性、有用性、多轮连贯性、领域契合度及安全性这五大维度,为研究者提供了一种可复现的对话质量度量框架。这有助于学术界深入探讨如何构建文化敏感且功能完备的阿拉伯语对话代理,推动低资源语言在自然语言处理领域的公平发展与评价体系完善。
衍生相关工作
该数据集衍生的相关工作包括基于五个核心维度的自动化对话评判器(如record_judge.py脚本所实现的GPT-4o-mini评分模型),以及用于清洗和过滤低质量对话的审计流程(如audit_final.py中的正则严格拒绝机制)。这些工具和流程可被其他语言或领域的对话数据集构建所借鉴,形成一套标准化的多轮对话质量保障管线,并推动未来工作在交叉验证、多语言对齐以及零样本对话评估等方向上的拓展研究。
以上内容由遇见数据集搜集并总结生成


