vxp-perspeak-withprom-final-v2
收藏Hugging Face2024-12-16 更新2024-12-17 收录
下载链接:
https://huggingface.co/datasets/prosodyntax/vxp-perspeak-withprom-final-v2
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含多种语言(如捷克语、德语、西班牙语等)的语音和语言学特征,用于训练模型。每个语言配置包含详细的特征信息,如单元、单元持续时间、音素、音素持续时间、多词标记、联合发音、词性、头部、依存关系、UD ID、句子ID、说话者、重音强度、边界强度和块标签。数据集提供了每个语言配置的训练集大小、下载大小和数据集大小。
创建时间:
2024-12-15
原始信息汇总
数据集概述
该数据集名为 vxp-perspeak-withprom-final-v2,包含多种语言的语音和语言学特征数据。以下是数据集的详细信息:
语言配置
数据集支持以下语言配置:
- 捷克语 (cs)
- 德语 (de)
- 西班牙语 (es)
- 法语 (fr)
- 克罗地亚语 (hr)
- 匈牙利语 (hu)
- 意大利语 (it)
- 荷兰语 (nl)
- 波兰语 (pl)
- 罗马尼亚语 (ro)
数据特征
每个语言配置包含以下特征:
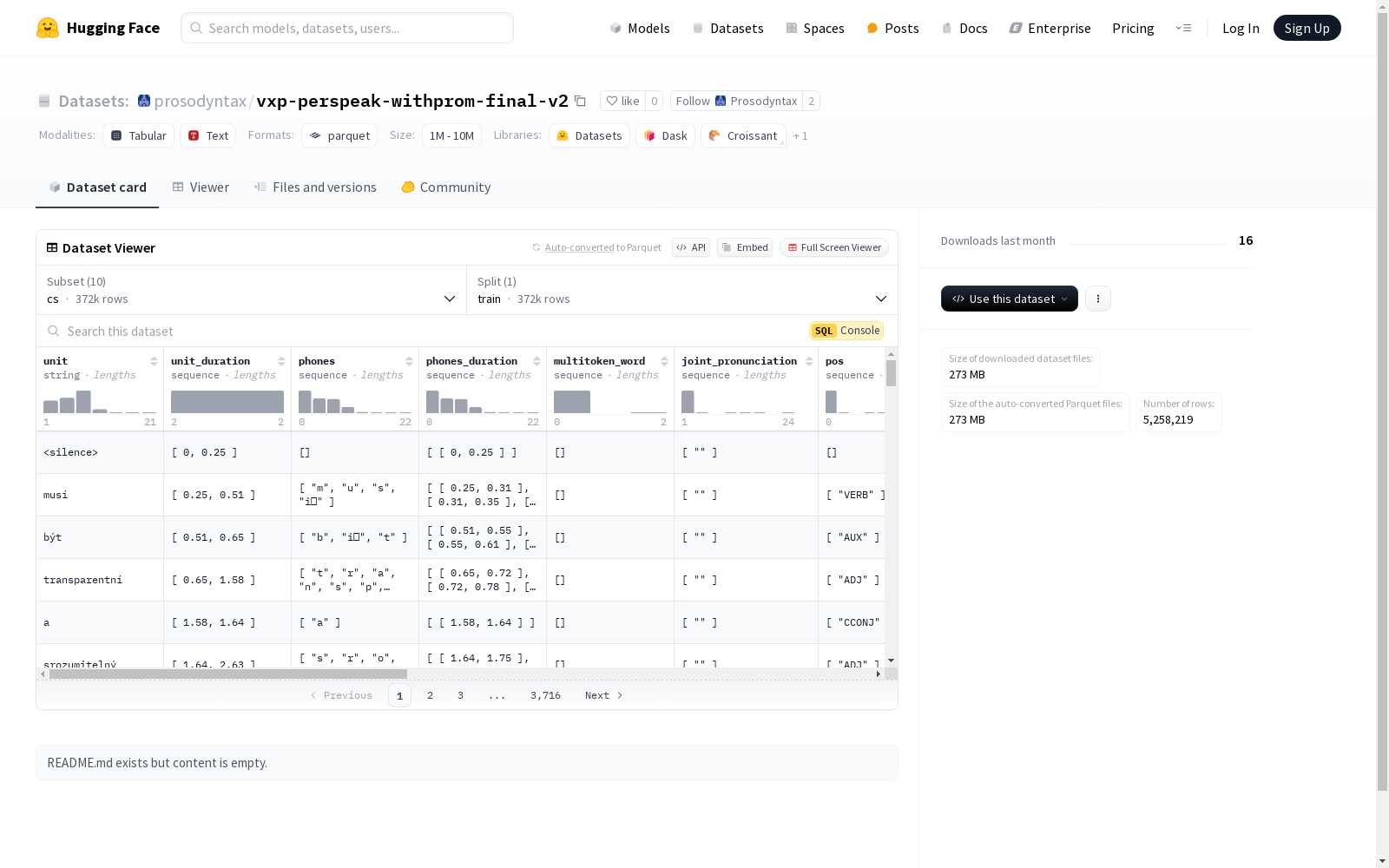
unit: 字符串类型,表示语音单元。unit_duration: 浮点数序列,表示语音单元的持续时间。phones: 字符串序列,表示音素。phones_duration: 浮点数序列的序列,表示音素的持续时间。multitoken_word: 字符串序列,表示多词单元。joint_pronunciation: 字符串序列,表示联合发音。pos: 字符串序列,表示词性。head: 字符串序列,表示句法头。deprel: 字符串序列,表示依存关系。ud_id: 字符串序列,表示UD标识符。sentence_id: 字符串类型,表示句子ID。speaker: 字符串类型,表示说话者。prominence_strength: 浮点数类型,表示重音强度。boundary_strength: 浮点数类型,表示边界强度。chunk_lab: 字符串序列,表示块标签。
数据分割
每个语言配置仅包含训练集 (train),具体信息如下:
捷克语 (cs)
- 训练集大小: 371570 个样本
- 训练集字节数: 106346383 字节
- 下载大小: 20236220 字节
德语 (de)
- 训练集大小: 1819234 个样本
- 训练集字节数: 501113529 字节
- 下载大小: 93811535 字节
西班牙语 (es)
- 训练集大小: 299732 个样本
- 训练集字节数: 82384522 字节
- 下载大小: 15691425 字节
法语 (fr)
- 训练集大小: 1604903 个样本
- 训练集字节数: 410688586 字节
- 下载大小: 79214111 字节
克罗地亚语 (hr)
- 训练集大小: 132370 个样本
- 训练集字节数: 38240129 字节
- 下载大小: 7162550 字节
匈牙利语 (hu)
- 训练集大小: 75998 个样本
- 训练集字节数: 18171197 字节
- 下载大小: 3469487 字节
意大利语 (it)
- 训练集大小: 196002 个样本
- 训练集字节数: 56052283 字节
- 下载大小: 11049236 字节
荷兰语 (nl)
- 训练集大小: 48549 个样本
- 训练集字节数: 12937007 字节
- 下载大小: 2338946 字节
波兰语 (pl)
- 训练集大小: 630903 个样本
- 训练集字节数: 189412686 字节
- 下载大小: 36121632 字节
罗马尼亚语 (ro)
- 训练集大小: 78958 个样本
- 训练集字节数: 20297520 字节
- 下载大小: 3760029 字节
搜集汇总
数据集介绍
构建方式
vxp-perspeak-withprom-final-v2数据集的构建基于多语言语音和语言特征的精细标注。该数据集涵盖了多种语言,包括捷克语、德语、西班牙语等,每种语言的训练数据均包含详细的语音单元、单元持续时间、音素、音素持续时间、多词标记、联合发音、词性、句法关系等信息。此外,数据集还标注了每个句子的说话者、重音强度、边界强度以及分块标签,确保了数据的多维度特征。
特点
vxp-perspeak-withprom-final-v2数据集的显著特点在于其多语言覆盖和丰富的语音与语言特征标注。每种语言的数据均包含详细的语音和语言学信息,如音素、词性、句法关系等,这为语音识别、自然语言处理等任务提供了坚实的基础。此外,数据集还特别标注了重音和边界强度,这对于语音合成和语音分析任务尤为重要。
使用方法
vxp-perspeak-withprom-final-v2数据集适用于多种语音和语言处理任务,包括但不限于语音识别、语音合成、自然语言处理等。用户可以根据具体任务需求,选择相应的语言配置和数据子集进行训练或评估。数据集的详细标注信息,如音素、词性、句法关系等,为模型提供了丰富的特征输入,有助于提升模型的性能和泛化能力。
背景与挑战
背景概述
vxp-perspeak-withprom-final-v2数据集是由多个研究人员或机构共同创建的,专注于语音和语言处理领域。该数据集涵盖了多种语言,包括捷克语、德语、西班牙语、法语、克罗地亚语、匈牙利语、意大利语、荷兰语、波兰语和罗马尼亚语。其核心研究问题在于通过多语言的语音数据,探索语音单元、发音、词性、句法关系等特征的关联性,进而推动语音识别、自然语言处理等领域的技术进步。该数据集的创建时间未明确提及,但其丰富的语言覆盖和详细的特征标注表明,它是在近年来语音处理技术快速发展的背景下诞生的,旨在为多语言语音研究提供坚实的基础。
当前挑战
vxp-perspeak-withprom-final-v2数据集在构建过程中面临多重挑战。首先,多语言数据的收集和标注工作复杂且耗时,不同语言的语音特征和语法结构差异巨大,增加了数据处理的难度。其次,数据集中包含的特征如语音单元时长、发音细节、词性标注等,需要高度精确的标注技术,以确保数据的可靠性和可用性。此外,数据集的规模庞大,涉及多个语言和大量的语音样本,如何在有限的计算资源下高效处理和分析这些数据,也是一大挑战。这些挑战不仅反映了数据集构建的复杂性,也凸显了其在推动语音处理技术发展中的重要性。
常用场景
经典使用场景
vxp-perspeak-withprom-final-v2数据集在语音处理领域中,主要用于语音合成与语音识别任务。该数据集通过提供多语言的语音单元、音素时长、词性标注等信息,使得研究者能够构建更加精准的语音模型。特别是在多语言语音合成中,该数据集的多样性为跨语言语音合成提供了丰富的训练数据,从而提升了合成语音的自然度和准确性。
解决学术问题
vxp-perspeak-withprom-final-v2数据集解决了多语言语音合成中的关键问题,如语音单元与音素时长的精确对齐、多语言语音特征的统一表示等。通过提供详细的语音特征和标注信息,该数据集为研究者提供了强大的工具,以探索和解决语音合成中的跨语言差异问题,推动了语音合成技术在多语言环境下的应用和发展。
衍生相关工作
基于vxp-perspeak-withprom-final-v2数据集,研究者们开发了多种语音合成模型和算法,如基于深度学习的跨语言语音合成模型、多语言语音识别系统等。这些工作不仅提升了语音合成和识别的性能,还为多语言语音处理领域的研究提供了新的思路和方法。此外,该数据集还激发了更多关于语音特征提取和语音信号处理的研究,推动了语音技术在学术界和工业界的广泛应用。
以上内容由遇见数据集搜集并总结生成


