AnyHand
收藏arXiv2026-03-27 更新2026-03-28 收录
下载链接:
https://chen-si-cs.github.io/projects/AnyHand/
下载链接
链接失效反馈官方服务:
资源简介:
AnyHand是由加州大学圣地亚哥分校等机构联合开发的大规模合成RGB-D手势数据集,包含660万条数据,涵盖单手势和手物交互场景。该数据集通过程序化生成方式构建,整合了47,438种手部形状参数、DPoser-Hand姿态先验模型以及Handy高保真纹理库,并引入SMPLitex前臂纹理和HDR环境光照以提升真实感。其核心价值在于提供完美对齐的深度信息与几何标注,突破了真实数据集在遮挡、视角多样性和标注噪声方面的局限。该数据集主要应用于计算机视觉领域的3D手势姿态估计任务,旨在通过合成数据规模化训练提升模型在VR/AR和机器人交互中的泛化能力。
提供机构:
加州大学圣地亚哥分校; Lambda公司; 伦敦帝国理工学院; 南洋理工大学
创建时间:
2026-03-27
原始信息汇总
AnyHand 数据集概述
数据集简介
AnyHand 是一个大规模合成 RGB-D 数据集,旨在推动从 RGB 和 RGB-D 输入进行 3D 手部姿态估计的技术发展。该数据集通过扩展手部姿态、手物交互、遮挡和野外视角变化的覆盖范围,显著提升了模型的性能和鲁棒性。
核心构成
数据集包含两个互补的子集:
- AnyHand-Single:包含 210 万张图像,涵盖不同背景和视角下的孤立手部场景。
- AnyHand-Interact:包含 420 万张图像,增加了基于 GraspXL 物理模拟的手物交互场景,涉及超过 1000 万条序列和 50 万+个物体。
数据规模与内容
- 总图像数:630 万(210 万 + 420 万)
- 手部形状:47,438 种
- 手部纹理:10,240 种
- 交互物体:>500,000 个
- 交互序列:1000 万+
- 背景:1,270 种
数据生成与标注
- 生成流程:手部形状采样自真实数据集 MANO 的统计特征;姿态来自 DPoser-Hand 扩散先验;外观通过 10,240 种 Handy 纹理和 254 种 SMPLitex 手臂纹理实现;场景在 Blender 中渲染,具有随机化的光照(1-5 个光源)、背景和相机参数(FOV 30°–40°,距离 0.6–1.0 米)。
- 标注信息:每张渲染图像均包含完整的多模态标注:RGB、深度、掩码、边界框、相机内参以及 3D 姿态/形状。
应用与效果
- RGB 设置:将 AnyHand 用于增强现有基线模型的训练集,可在保持架构和训练方案不变的情况下,在 FreiHAND 和 HO-3D 等多个基准测试上取得显著提升。
- 泛化能力:使用 AnyHand 训练的模型能更好地泛化到域外数据集 HO-Cap,且无需微调。
- RGB-D 模型:通过引入一个轻量级深度融合模块,并与 AnyHand 数据共同训练,所得的 RGB-D 模型在 HO-3D 上实现了卓越性能。
发布状态
- 当前发布:提供了使用 AnyHand 协同训练的 HaMeR 和 WiLoR 微调检查点,可用于野外手部姿态估计。
- 即将发布:完整数据集、训练代码和 arXiv 预印本。
搜集汇总
数据集介绍
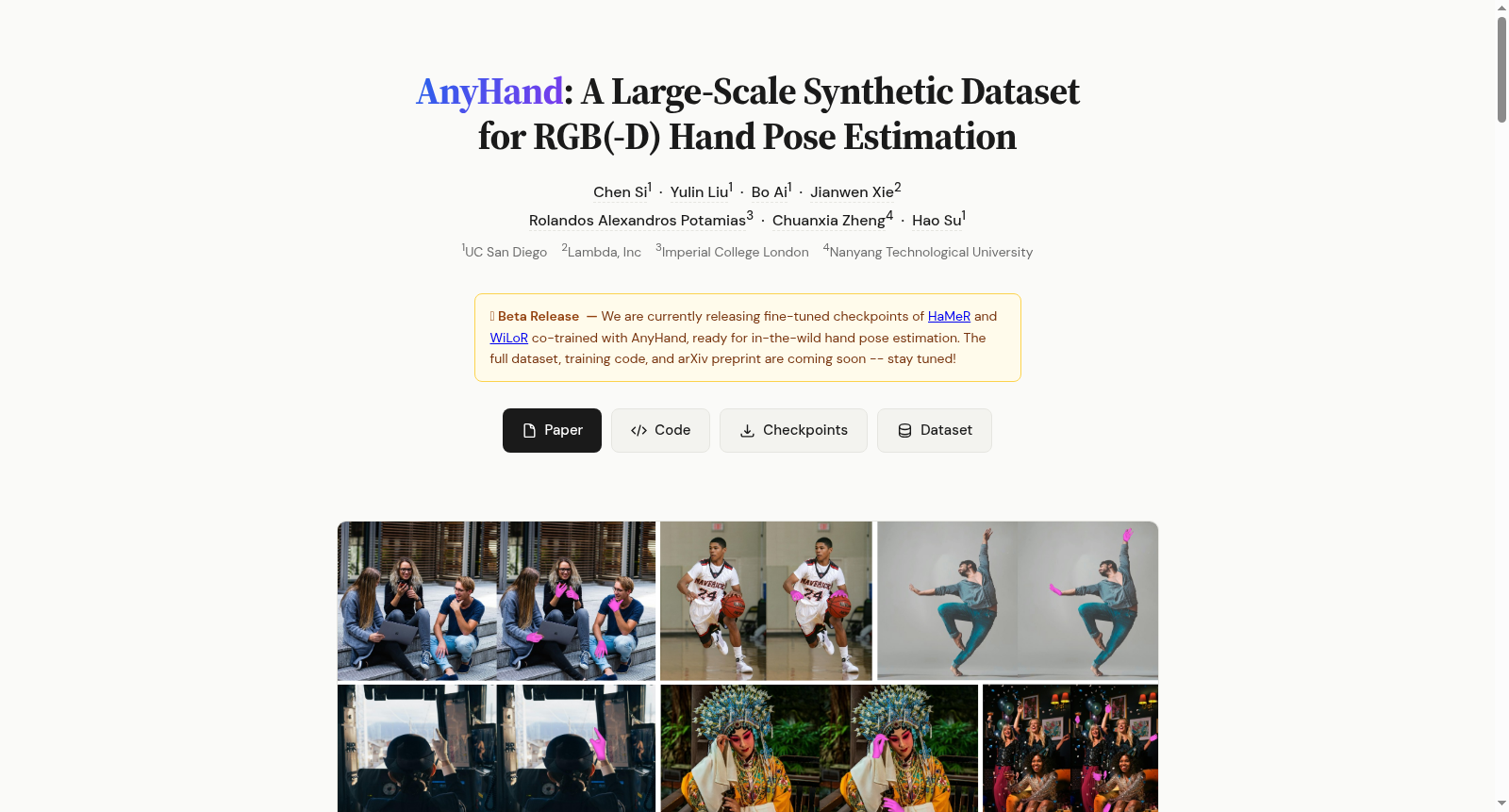
构建方式
在三维手部姿态估计领域,数据规模与多样性是提升模型性能的关键瓶颈。AnyHand数据集通过合成生成方式构建,其核心在于一个高度可控的渲染管线。该管线以参数化手部模型MANO为基础,从真实数据集中采样了数万种手部形状,并利用扩散模型DPoser-Hand生成多样且符合人体工学的姿态。为了提升视觉真实感,数据集采用了Handy生成的高频皮肤纹理,并结合SMPLitex提供的纹理为前臂建模,确保了手-臂外观的连续性。场景构建方面,通过随机化相机参数、动态光照以及从高清环境贴图和室内场景库中采样的背景,极大地扩展了视觉多样性。数据集包含纯手部场景(AnyHand-Single)和手物交互场景(AnyHand-Interact)两个分支,后者基于大规模物理仿真抓取库GraspXL生成,模拟了真实的遮挡情况。所有样本均提供了精确对齐的RGB图像、深度图、前景掩码以及完整的3D姿态与形状标注。
特点
AnyHand数据集最显著的特点在于其前所未有的规模与多模态完整性。该数据集总计提供了660万张RGB-D图像,涵盖了从简单手势到复杂手物交互的广泛场景,在数据量上超越了多数现有合成数据集。其深度信息与RGB图像精确对齐,为解决单目RGB方法中的深度歧义问题提供了直接的几何线索。此外,数据集在真实性方面进行了多项创新:不仅模拟了多样化的皮肤色调与纹理,还首次在大规模合成数据中引入了带有衣物纹理的前臂上下文,有效减少了模型对“干净”实验室环境的过拟合。通过集成动态光照、高动态范围背景以及基于物理的交互仿真,AnyHand极大地缩小了合成数据与真实世界之间的域差距,为训练具有强泛化能力的模型奠定了数据基础。
使用方法
AnyHand数据集的设计旨在作为现有真实数据集的补充训练资源,以提升模型的性能与鲁棒性。典型的使用方法是与FreiHAND、HO-3D等真实数据集进行协同训练。研究实践表明,在保持HaMeR、WiLoR等先进模型架构与训练协议不变的情况下,仅将AnyHand数据加入训练集,即可在多个标准基准测试上带来显著的性能提升,甚至在未经过微调的跨域数据集HO-Cap上也表现出更强的泛化能力。对于RGB-D输入,AnyHand提供了训练深度融合模块所需的配对数据。用户可以基于其提供的轻量级跨模态注意力模块,将深度线索集成到现有的基于RGB的Transformer架构中,从而构建出能够同时利用外观与几何信息的混合模型。数据集的发布还包括完整的生成管线,便于研究者进一步定制和扩展数据,推动手部姿态估计领域向更大规模、更高质量的数据驱动范式发展。
背景与挑战
背景概述
AnyHand数据集由加州大学圣地亚哥分校等机构的研究团队于2026年提出,旨在解决三维手部姿态估计领域的数据瓶颈问题。该数据集专注于从RGB或RGB-D输入中稳健地重建三维手部姿态,尤其在复杂的手-物交互场景中。其核心研究问题在于如何通过大规模、高质量的合成数据来提升模型的泛化能力和鲁棒性,以应对真实数据在多样性、遮挡和深度对齐方面的局限性。AnyHand的发布显著推动了手部姿态估计领域的发展,通过提供超过660万张带有精确几何标注的合成图像,为基于Transformer的基础模型提供了丰富的训练资源,并在多个标准基准测试中取得了性能提升。
当前挑战
AnyHand数据集面临的挑战主要体现在两个方面。在领域问题层面,三维手部姿态估计本身具有高度复杂性,手部关节的自由度高、易受遮挡和视角变化影响,且从单目RGB图像中恢复深度信息存在固有的歧义性。数据集构建过程中,研究团队需克服合成数据与真实数据之间的域差距,确保生成的手部姿态、纹理、光照及背景具有足够的真实性和多样性。具体挑战包括:如何从扩散先验模型中采样自然的手部姿态以避免不合理的关节角度;如何整合高保真的手部与前臂纹理以实现外观连续性;以及如何为大规模手-物交互场景提供精确对齐的深度图,同时保持渲染效率与几何一致性。
常用场景
经典使用场景
在计算机视觉领域,手部姿态估计作为人机交互的核心技术,长期面临数据稀缺与多样性的挑战。AnyHand数据集通过大规模合成RGB-D图像,为3D手部姿态估计提供了丰富的训练资源。其经典使用场景在于作为补充训练集,与真实数据集协同训练,显著提升HaMeR、WiLoR等前沿模型在FreiHAND、HO-3D等基准测试中的性能。该数据集涵盖单手势与手物交互场景,通过随机化相机视角、光照与背景,模拟真实世界复杂性,有效缓解模型对有限采集条件的过拟合。
实际应用
AnyHand数据集的实际应用广泛渗透于增强现实、虚拟现实及机器人操控等前沿领域。在AR/VR中,精准的手部姿态估计是实现自然交互的关键,数据集通过模拟多样手物交互与遮挡场景,提升了系统在复杂环境下的鲁棒性。在机器人领域,基于该数据训练的模型能够更准确地理解人类手势意图,促进灵巧抓取与操作任务的实现。此外,其提供的RGB-D多模态数据支持轻量级深度融合模块的开发,使得仅依赖RGB输入的模型也能利用几何线索,降低对专用深度传感器的依赖,拓宽了技术在消费级设备上的部署前景。
衍生相关工作
AnyHand数据集的发布催生了一系列相关研究工作,尤其在多模态融合与合成数据利用方面。基于该数据集,研究者提出了AnyHandNet-D,一种集成轻量级深度融合模块的RGB-D架构,在HO-3D基准上超越了IPNet、Keypoint Fusion等先前方法。同时,数据集的协同训练范式启发了对合成-真实数据混合比例的深入探索,如通过调整AnyHand与真实数据的混合比例优化模型性能。此外,其生成管线为后续大规模合成手部数据集的构建提供了参考,促进了如GraspXL等物理仿真交互数据在姿态估计领域的集成,推动了手部建模向更高真实感与多样性的演进。
以上内容由遇见数据集搜集并总结生成


