soa-full-florence2
收藏Hugging Face2024-07-31 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/aipicasso/soa-full-florence2
下载链接
链接失效反馈官方服务:
资源简介:
该数据集基于Smithsonian Open Access的soa-full数据集,原本不包含图像描述。为了补充这一信息,使用了Florence-2模型为图像生成详细的描述。数据集主要用于视觉与语言研究,以及开发图像到文本或文本到图像的模型。数据集包含图像、来源URL、描述、图像宽度和高度等特征,分为训练集。
This dataset is based on the soa-full dataset from Smithsonian Open Access, which originally lacked image captions. To fill this gap, the Florence-2 model was employed to generate detailed captions for all included images. This dataset is primarily intended for vision-language research and the development of image-to-text or text-to-image models. It comprises features including images, source URLs, captions, image width and height, and is divided into training subsets.
创建时间:
2024-07-29
搜集汇总
数据集介绍
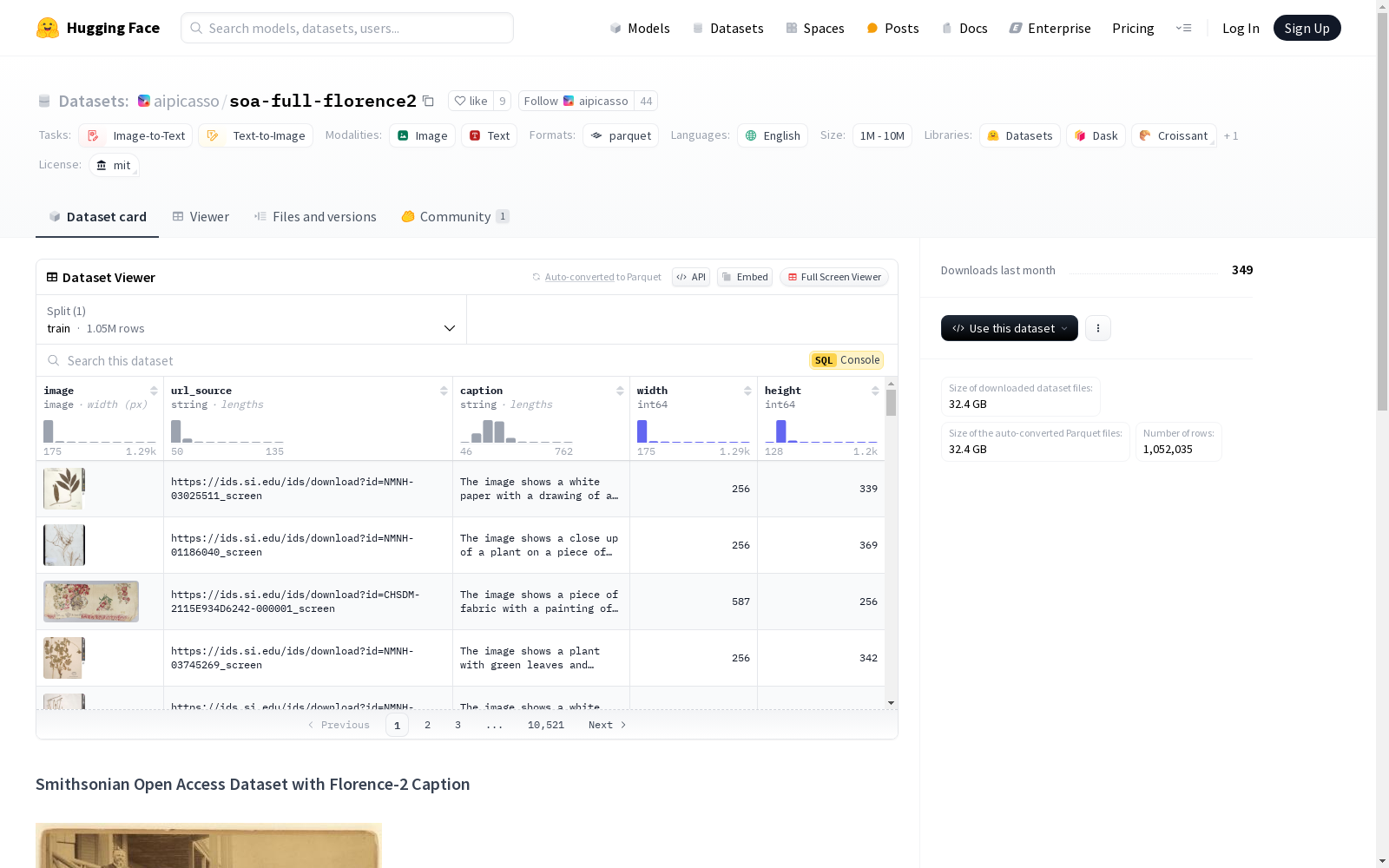
构建方式
soa-full-florence2数据集的构建基于Smithsonian Open Access(soa-full)数据集,该数据集原本包含大量CC-0许可的图像,但缺乏相应的图像描述。为了弥补这一不足,研究团队采用Microsoft的Florence-2-large模型对图像进行了详细的描述生成。具体而言,模型被赋予DETAILED_CAPTION任务,以确保生成的描述具有较高的信息量和准确性。整个过程耗时300 GPU小时(使用T4 GPU),最终为每张图像生成了相应的描述文本。
特点
soa-full-florence2数据集的主要特点在于其图像与文本的紧密结合,为视觉与语言研究提供了丰富的资源。数据集包含超过百万张图像及其对应的详细描述,涵盖广泛的视觉内容。此外,数据集的构建过程确保了描述的高质量,使其适用于开发和训练图像到文本或文本到图像的模型。数据集的规模和多样性使其成为视觉与语言领域研究的理想选择。
使用方法
使用soa-full-florence2数据集时,用户可以通过HuggingFace的datasets库进行加载。具体操作包括导入load_dataset函数,并指定数据集名称'aipicasso/soa-full-florence2'。数据集的结构设计便于用户直接访问图像、描述文本及其相关元数据,如图像的宽度和高度。该数据集特别适用于研究视觉与语言的结合,以及开发和训练图像到文本或文本到图像的模型。
背景与挑战
背景概述
soa-full-florence2数据集是由Smithsonian Open Access(soa-full)数据集扩展而来,该数据集原本包含大量CC-0许可的图像,但缺乏相应的图像描述。为了弥补这一不足,研究团队利用Microsoft的Florence-2-large模型为这些图像生成了详细的描述(caption)。这一过程不仅丰富了数据集的内容,还为视觉与语言研究领域提供了宝贵的资源。该数据集的创建旨在支持图像到文本(image-to-text)和文本到图像(text-to-image)模型的开发与研究,进一步推动了计算机视觉与自然语言处理领域的交叉研究。
当前挑战
soa-full-florence2数据集的构建过程中面临的主要挑战包括:首先,原始数据集缺乏图像描述,这要求研究团队采用先进的图像描述生成模型(如Florence-2-large)来填补这一空白,这一过程耗费了大量的计算资源(约300 GPU小时)。其次,生成高质量的图像描述需要模型具备强大的语言理解和生成能力,这对模型的性能提出了较高的要求。此外,数据集的规模较大(超过100万条数据),如何在保证数据质量的同时高效处理和存储这些数据也是一个重要的挑战。这些挑战不仅影响了数据集的构建效率,也对后续的研究和应用提出了更高的技术要求。
常用场景
经典使用场景
soa-full-florence2数据集的经典使用场景主要集中在视觉与语言研究领域,尤其是在图像到文本和文本到图像的模型开发中。该数据集通过结合Smithsonian Open Access的图像数据与Florence-2模型的详细描述,为研究者提供了一个丰富的图像与文本对齐资源。这使得研究者能够训练和评估图像描述生成模型以及基于文本生成图像的模型,从而推动视觉与语言交叉领域的研究进展。
解决学术问题
该数据集解决了在视觉与语言研究中,图像与文本对齐数据稀缺的问题。通过提供带有详细描述的图像数据,soa-full-florence2数据集为研究者提供了一个高质量的基准,用于开发和测试图像描述生成和文本到图像生成的算法。这不仅有助于提升现有模型的性能,还为未来的研究提供了新的方向和可能性,特别是在多模态学习和生成模型领域。
衍生相关工作
基于soa-full-florence2数据集,研究者已经开展了多项相关工作,包括改进图像描述生成模型的性能、探索多模态学习的新方法以及开发更高效的文本到图像生成技术。这些工作不仅提升了现有模型的表现,还为未来的研究提供了新的思路和方法。例如,有研究利用该数据集进行跨模态检索的实验,验证了其在多模态数据对齐中的有效性,进一步推动了视觉与语言领域的研究进展。
以上内容由遇见数据集搜集并总结生成


