togethercomputer/RedPajama-Data-1T-Sample|自然语言处理数据集|开源数据集数据集
收藏hugging_face2023-07-19 更新2024-03-04 收录
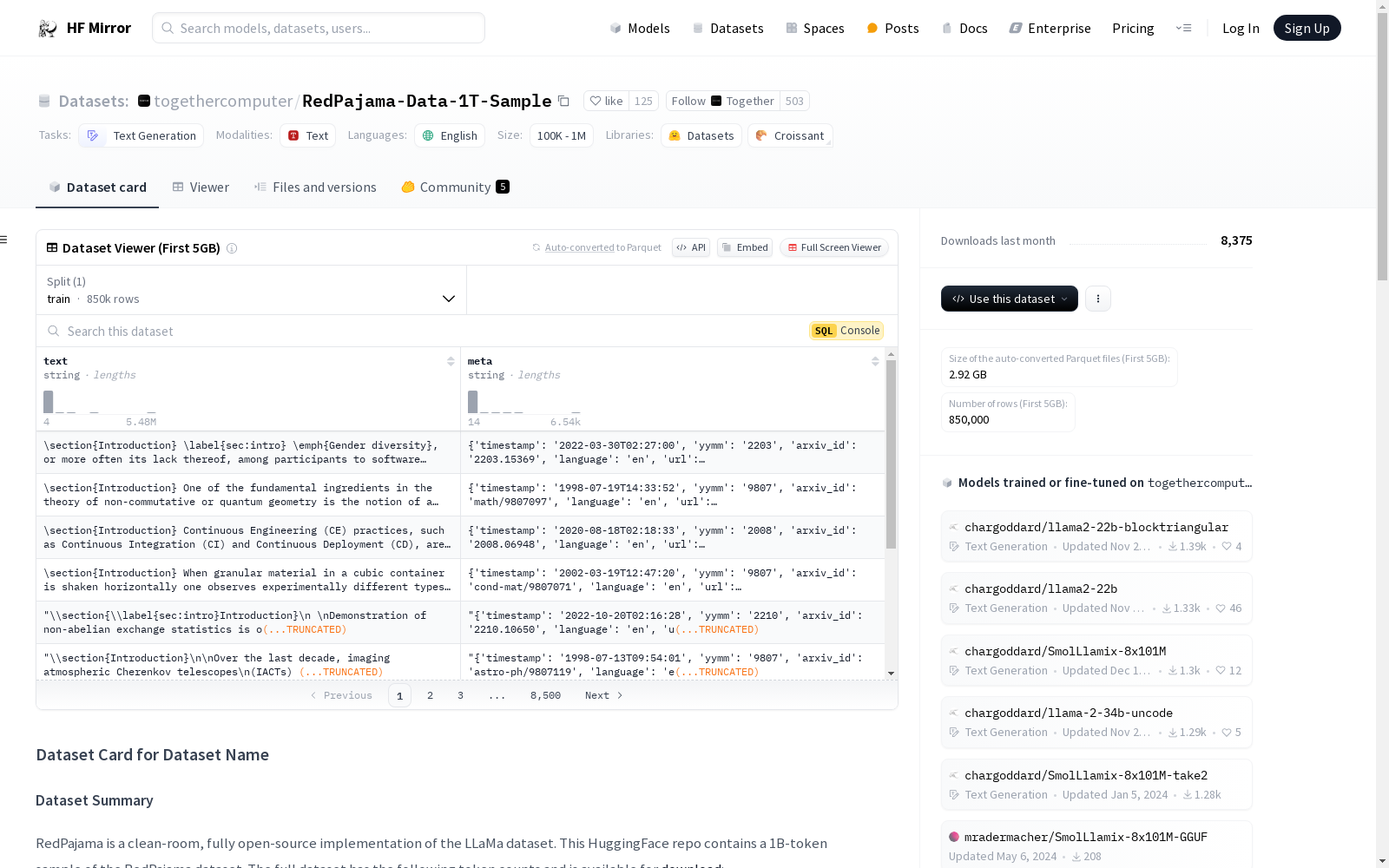
下载链接:
https://hf-mirror.com/datasets/togethercomputer/RedPajama-Data-1T-Sample
下载链接
链接失效反馈资源简介:
RedPajama是一个开源的LLaMa数据集的实现,包含了从多个来源(如Commoncrawl、C4、GitHub等)收集的文本数据,总计约1.2万亿个token。该HuggingFace仓库包含了RedPajama数据集的1B-token样本。数据集主要用于文本生成任务,主要语言为英语,尽管Wikipedia部分包含多种语言。数据集的每个条目包含文本内容和元数据(如URL、时间戳、来源、语言等)。
提供机构:
togethercomputer
原始信息汇总
数据集概述
数据集名称
RedPajama
数据集摘要
RedPajama是一个遵循LLaMa论文的完全开源实现的数据集。本仓库包含RedPajama数据集的一个1亿token样本。完整数据集包含以下token计数,并可从此处下载:
| 数据集 | Token计数 |
|---|---|
| Commoncrawl | 8780亿 |
| C4 | 1750亿 |
| GitHub | 590亿 |
| Books | 260亿 |
| ArXiv | 280亿 |
| Wikipedia | 240亿 |
| StackExchange | 200亿 |
| 总计 | 1.2万亿 |
语言
主要为英语,但Wikipedia部分包含多种语言。
数据集结构
数据集结构如下: json { "text": ..., "meta": {"url": "...", "timestamp": "...", "source": "...", "language": "...", ...} }
数据集创建
数据集的创建旨在尽可能遵循LLaMa论文,以尝试重现其配方。
源数据
- Commoncrawl: 下载五个Commoncrawl转储,并通过官方
cc_net管道运行。在段落级别进行去重,并使用线性分类器过滤低质量文本。 - C4: 从Huggingface下载,唯一的预处理步骤是将数据转换为我们的格式。
- GitHub: 从Google BigQuery下载原始数据,在文件级别去重,并仅保留MIT、BSD或Apache许可下的项目。
- Wikipedia: 使用基于2023-03-20 Wikipedia转储的Huggingface数据集,包含20种不同语言的文本。
- Gutenberg和Books3: 下载PG19子集,使用simhash去除近似重复。
- ArXiv: 从Amazon S3的
arxiv请求者付费桶下载,仅保留latex源文件。 - Stackexchange: 从Internet Archive下载,仅保留来自28个最大站点的帖子,并将其分组为问题-答案对。
AI搜集汇总
数据集介绍
构建方式
RedPajama-Data-1T-Sample数据集的构建遵循了LLaMa论文的指导原则,旨在复现其数据配方。数据集通过整合多个来源的数据,包括Commoncrawl、C4、GitHub、Wikipedia、Gutenberg和Books3、ArXiv以及StackExchange。每个数据源都经过特定的预处理步骤,如去重、质量过滤和格式转换,以确保数据的多样性和高质量。例如,Commoncrawl数据通过官方cc_net管道处理并进行段落级别的去重,而GitHub数据则通过文件级别的去重和许可证过滤。
使用方法
RedPajama-Data-1T-Sample数据集适用于文本生成任务,特别是那些需要大规模、多样化语料的场景。研究者可以通过HuggingFace平台直接下载数据样本,或访问GitHub获取完整的构建脚本以从头开始生成数据集。数据集的结构为JSON格式,每个条目包含文本内容和元数据,便于直接用于模型训练和评估。此外,数据集的多样性和高质量使其成为训练和测试大规模语言模型的理想选择。
背景与挑战
背景概述
RedPajama数据集是由togethercomputer团队于2023年创建的一个开源文本生成数据集,旨在复现LLaMa数据集的构建方法。该数据集涵盖了多种数据源,包括Commoncrawl、C4、GitHub、Wikipedia、Gutenberg、Books3、ArXiv和StackExchange,总规模达到1.2万亿个token。RedPajama的创建不仅为自然语言处理领域提供了丰富的训练资源,还推动了开源社区在大型语言模型数据集构建方面的研究进展。其多样化的数据来源和严格的预处理流程,使其成为研究文本生成、语言模型预训练等任务的重要基准。
当前挑战
RedPajama数据集在构建过程中面临多重挑战。首先,数据源的多样性和规模庞大带来了数据清洗和去重的复杂性,例如Commoncrawl数据的低质量文本过滤和GitHub文件的许可证合规性检查。其次,不同数据源的格式差异要求开发统一的预处理流程,以确保数据的一致性和可用性。此外,数据集的开放性和透明度要求团队在数据采集、处理和发布过程中严格遵守开源协议和隐私保护规范。这些挑战不仅考验了数据处理技术的极限,也为未来大规模数据集的构建提供了宝贵的经验。
常用场景
经典使用场景
RedPajama-Data-1T-Sample数据集在自然语言处理领域中被广泛用于文本生成任务。其丰富的文本来源和多样化的内容使其成为训练大规模语言模型的理想选择。研究人员可以利用该数据集进行语言模型的预训练和微调,以提升模型在生成连贯、上下文相关文本方面的能力。
解决学术问题
该数据集解决了大规模语言模型训练中数据质量和多样性的问题。通过整合来自Commoncrawl、C4、GitHub、Wikipedia等多个高质量数据源,RedPajama-Data-1T-Sample为研究人员提供了一个全面且经过严格筛选的文本资源库。这不仅有助于提升模型的泛化能力,还为研究数据预处理和去重技术提供了宝贵的实验平台。
实际应用
在实际应用中,RedPajama-Data-1T-Sample数据集被广泛用于开发智能对话系统、自动文本摘要和机器翻译等任务。其多样化的文本内容使得模型能够更好地理解和生成不同领域的语言表达,从而在实际应用中表现出更高的准确性和鲁棒性。
数据集最近研究
最新研究方向
在自然语言处理领域,RedPajama-Data-1T-Sample数据集的最新研究方向主要集中在开放域文本生成模型的训练与优化。该数据集作为LLaMa数据集的开放源码实现,提供了包括Commoncrawl、C4、GitHub、Books、ArXiv、Wikipedia和StackExchange在内的多源数据,总计1.2万亿令牌,为研究者提供了丰富的语料资源。当前研究热点包括如何有效利用这些异构数据源提升模型的泛化能力和生成质量,特别是在多语言环境下的表现。此外,数据集的去重和质量过滤机制也为研究数据预处理对模型性能的影响提供了新的视角。RedPajama-Data-1T-Sample的开放性和多样性,不仅推动了文本生成技术的发展,也为探索大规模数据集在AI模型训练中的最佳实践提供了重要参考。
以上内容由AI搜集并总结生成


