DOLOS Dataset
收藏github2024-05-08 更新2024-05-31 收录
下载链接:
https://github.com/NMS05/Audio-Visual-Deception-Detection-DOLOS-Dataset-and-Parameter-Efficient-Crossmodal-Learning
下载链接
链接失效反馈官方服务:
资源简介:
DOLOS是一个基于在线现实电视游戏节目的欺骗检测多模态研究数据集。该数据集可以从ROSE Lab, NTU下载,包含原始未处理的DOLOS数据集和MUMIN注释,以及用于下载数据集的视频时间戳文件和训练协议文件。
DOLOS is a multimodal research dataset for deception detection based on an online reality TV game show. This dataset, available for download from the ROSE Lab at NTU, includes the raw and unprocessed DOLOS dataset along with MUMIN annotations, as well as video timestamp files and training protocol files for downloading the dataset.
创建时间:
2023-04-14
原始信息汇总
DOLOS Dataset概述
数据集组成
- Dolos.xlsx:包含原始DOLOS数据集和MUMIN注释,每条样本记录包括YouTube视频链接、时间戳、标签(真实或欺骗)、文件名、主体姓名、主体性别以及MUMIN注释的时间间隔列表。
- dolos_timestamps(.txt/.csv):用于下载DOLOS数据集的时间戳文件,配合YT_video_downloader.py脚本自动下载YouTube视频并保存为.mp4格式。
- train_dolos.xlsx:包含MUMIN特征的二进制注释,适用于多任务学习和PyTorch DataLoader。
- Training_Protocols/:包含用于论文实验的训练协议,包括用于三折评估的多模态欺骗检测器的train_fold.csv/test_fold.csv,以及用于研究说话(欺骗)时长变化和性别影响的协议。
数据预处理
- 使用extract_face_frames.py和video_to_audio.py从下载的视频中提取RGB面部帧和.wav音频文件。
训练脚本
- scripts/:包含用于在预处理DOLOS数据集上训练模型的PyTorch代码,包括数据加载器、模型定义和训练测试脚本。
- dataloader/:
audio_visual_dataset.py,根据Training_Protocols中的.csv文件返回音频波形、面部帧和标签作为torch张量。 - models/:包含用于音频和视觉欺骗检测的模型,以及用于多模态欺骗检测的融合模型。
train_test.py:用于训练单模态和多模态欺骗检测模型的脚本。- 运行
train_fusion.sh以实现可重复性。
- dataloader/:
搜集汇总
数据集介绍
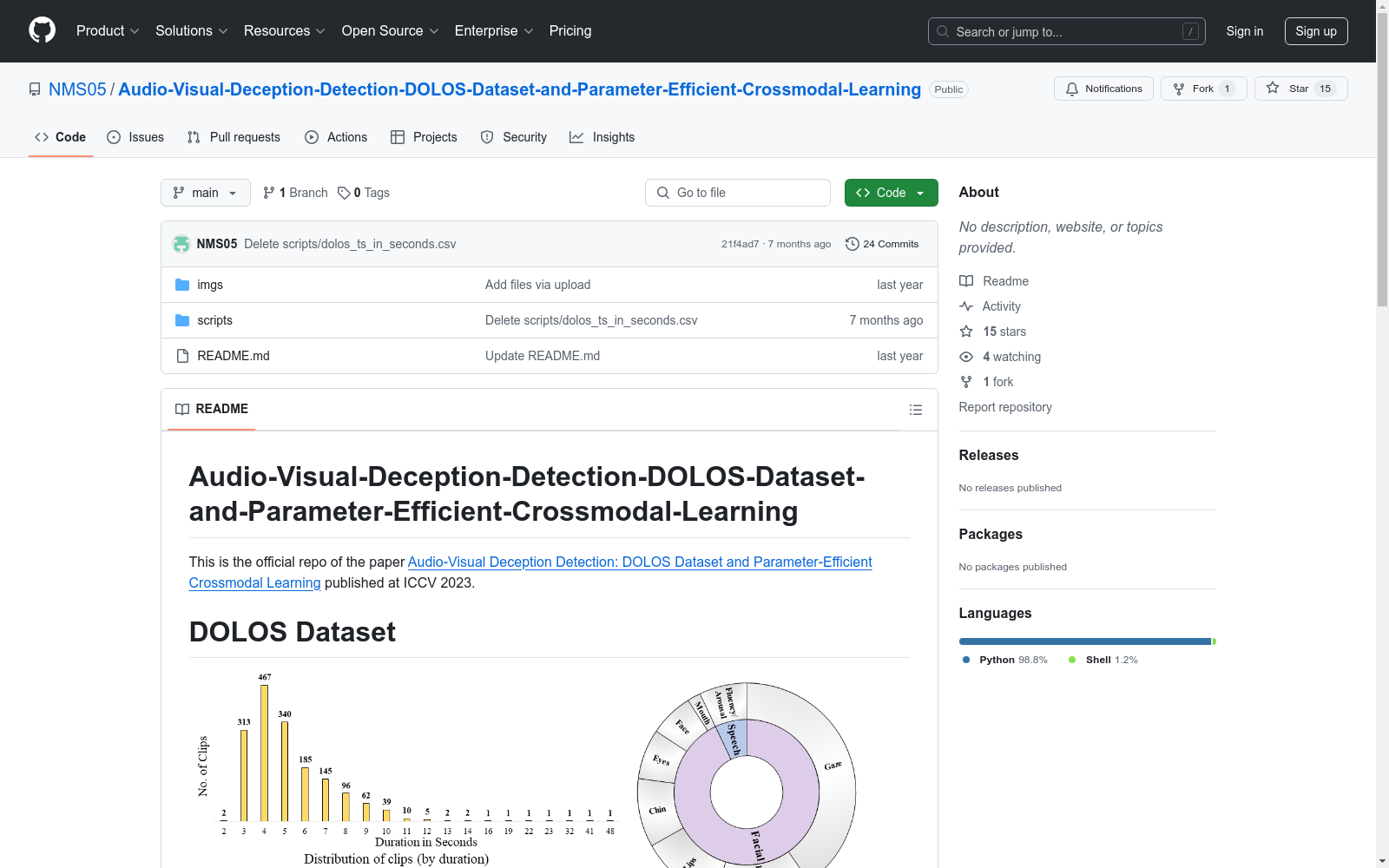
构建方式
DOLOS数据集的构建基于一个在线现实电视游戏节目,专注于多模态欺骗检测研究。该数据集通过收集YouTube视频链接、时间戳及其对应的标签(真实或欺骗),并辅以元数据(如文件名、参与者姓名和性别)以及MUMIN注释的时间间隔列表,形成了一个结构化的数据集。此外,通过提供的脚本,可以自动从YouTube下载相关视频并保存为.mp4格式,进一步丰富了数据集的内容。
特点
DOLOS数据集的显著特点在于其多模态性,结合了音频和视觉信息,为欺骗检测提供了丰富的数据支持。数据集中的MUMIN注释为时间间隔列表,有助于精确的时间序列分析。此外,数据集提供了多种训练协议,如性别和说话时长变量的研究,增强了其在不同场景下的适用性和研究价值。
使用方法
使用DOLOS数据集时,首先通过提供的脚本下载并预处理视频数据,提取RGB面部帧和.wav音频文件。随后,利用PyTorch代码库中的数据加载器和模型脚本,可以进行音频、视觉以及多模态欺骗检测的训练和测试。特别地,通过运行train_fusion.sh脚本,可以实现模型的可重复训练,确保实验结果的可靠性。
背景与挑战
背景概述
DOLOS数据集,由ROSE Lab, NTU于2023年创建,专注于多模态欺骗检测研究。该数据集源自一个在线现实电视游戏节目,旨在通过音频和视觉信息识别欺骗行为。主要研究人员通过整合YouTube视频链接、时间戳及其对应标签(真实或欺骗),以及MUMIN注释,构建了一个详尽的数据集。DOLOS数据集不仅提供了丰富的元数据,如文件名、参与者姓名和性别,还通过多任务学习的方式,支持PyTorch DataLoader的使用,极大地推动了多模态欺骗检测领域的发展。
当前挑战
DOLOS数据集在构建过程中面临多项挑战。首先,数据来源的多样性和复杂性要求高效的跨模态学习方法,以确保音频和视觉信息的有效融合。其次,数据集的规模和质量控制是一个重要问题,特别是在处理来自YouTube的视频时,需确保视频的可用性和一致性。此外,多模态欺骗检测的训练过程中,如何平衡不同模态的信息权重,以及如何处理不同性别和说话时长对检测结果的影响,都是亟待解决的难题。
常用场景
经典使用场景
在多模态欺骗检测领域,DOLOS数据集的经典使用场景主要集中在音频和视觉信息的融合分析上。通过提取视频中的面部表情和音频特征,研究人员可以训练模型以识别和区分真实陈述与欺骗行为。这种多模态分析方法不仅提高了检测的准确性,还为跨模态学习提供了丰富的数据支持。
实际应用
在实际应用中,DOLOS数据集被广泛用于安全监控、司法鉴定和心理评估等领域。例如,在安全监控中,通过分析监控视频中的音频和视觉信息,可以有效识别潜在的欺骗行为,提高安全系统的可靠性。在司法鉴定中,该数据集支持开发更精确的欺骗检测工具,有助于提高审判的公正性。
衍生相关工作
基于DOLOS数据集,许多相关研究工作得以展开,包括但不限于多模态融合模型、跨模态学习算法和欺骗检测系统的优化。例如,有研究利用该数据集开发了基于Wav2Vec2和ViT-B16的音频视觉融合模型,显著提高了欺骗检测的性能。此外,还有研究探讨了性别和说话时长对欺骗检测的影响,进一步丰富了该领域的研究内容。
以上内容由遇见数据集搜集并总结生成


