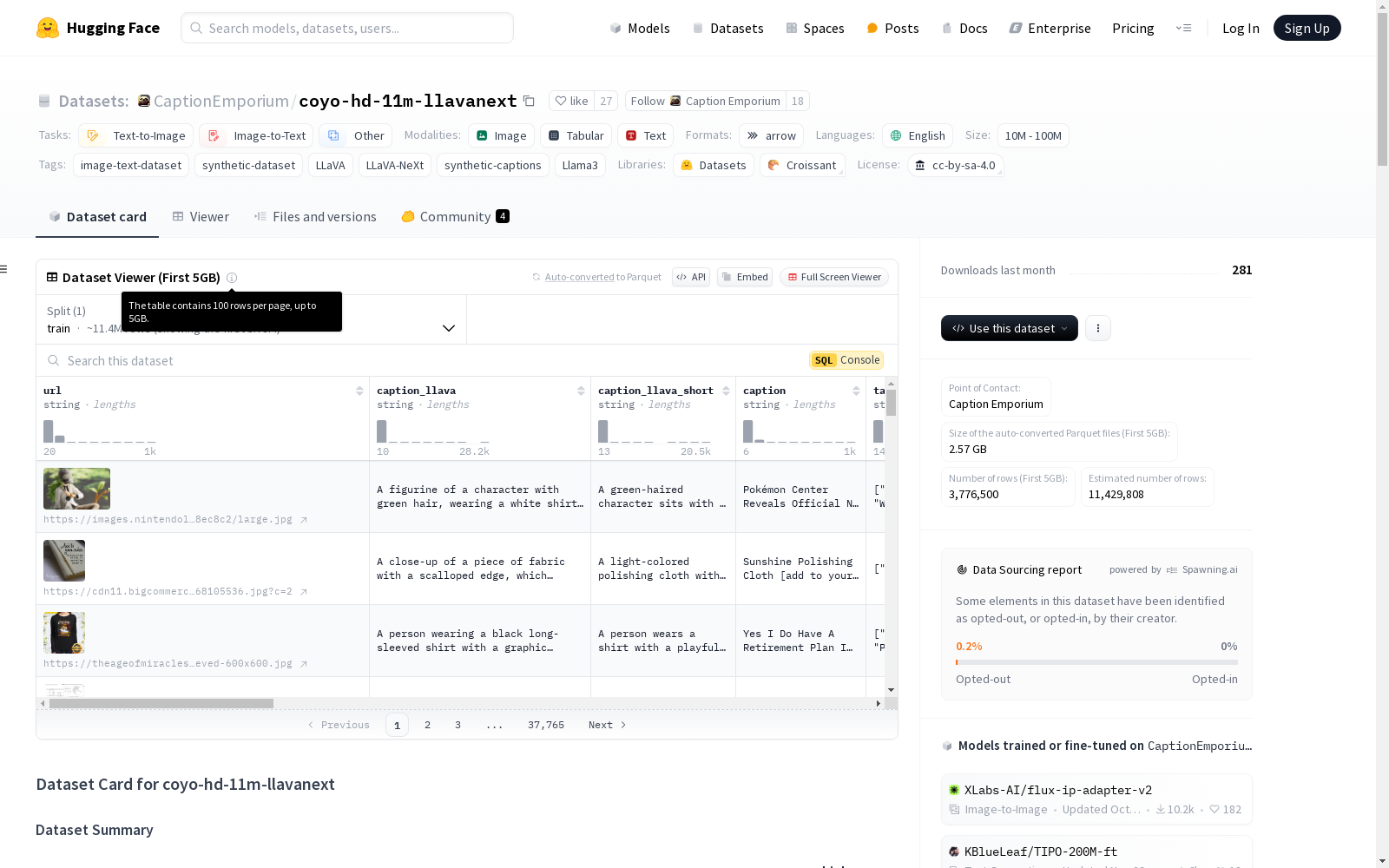
coyo-hd-11m-llavanext
收藏数据集概述
数据集描述
数据集摘要
- 名称: coyo-hd-11m-llavanext
- 类型: 合成图像文本数据集
- 语言: 英语
- 大小: 11,397,144 张图像,22,794,288 条合成描述
- 分辨率: 图像经过预过滤,最短边为 512 像素
- 来源: 从 coyo-700m 数据集中筛选
数据实例
- 示例: json { "url": "https://images.nintendolife.com/cd4b7518ec8c2/large.jpg", "caption_llava": "A figurine of a character with green hair, wearing a white shirt, a black vest, and a gray cap, sitting with one hand on their knee and the other hand making a peace sign. The character is wearing a blue pendant and has a gold bracelet. In the background, there are green plants and a tree branch.", "caption_llava_short": "A green-haired character sits with a peace sign, wearing a blue pendant and gold bracelet, surrounded by green plants and a tree branch.", "caption": "Pokémon Center Reveals Official N And Zorua Figure, Pre-Orders Have Gone Live", "tags_open_images": "["Black", "Green", "White", "Animation"]", "tags_booru": "["bangs", "long_hair", "solo", "hat", "sitting", "jewelry", "necklace", "smile", "green_hair", "1boy", "tree", "pants", "shirt", "male_focus", "white_shirt", "bracelet", "ponytail", "baseball_cap", "black_shirt", "bangle", "branch", "index_finger_raised", "closed_mouth", "blurry", "blurry_background"]", "key": 25, "clip_similarity_vitb32": 0.1964111328125, "clip_similarity_vitl14": 0.259033203125, "nsfw_score_opennsfw2": 0.0290679931640625, "nsfw_score_gantman": 0.036349426954984665, "watermark_score": 0.0038619472179561853, "aesthetic_score_laion_v2": 5.079052925109863, "num_faces": 0, "width": 1280, "height": 789, "exif": "{}", "sha256": "dbec63de854341a189ba87d27dc04945e3d4fef0b0275f496ae16c79b723a157", }
数据分割
- 训练集: 11,397,144 张图像
数据集创建
高概念过滤
- 过滤器: 使用两个多标签分类器 ML_Decoder TResNet-M Open Images 和 mldanbooru 进行过滤
- 过滤标准: py def image_excluded(oi_tags, booru_tags): if (Product in oi_tags and no_humans in booru_tags) or (Text in oi_tags and no_humans in booru_tags and text_focus in booru_tags) or len(oi_tags) < 2 or len(booru_tags) < 3 or text-only_page in booru_tags: return True return False
描述生成
-
生成模型: llama3-llava-next-8b
-
提示: py prompt_gen = lambda txt :f""" Please make a detailed but succinct caption of this image. If you see text or objects, be sure to describe them in detail along with any other aspects of the foreground and background. As a hint, here is the alt-text attribute of the image, which may or may not have to do with the image:
Hint:
{txt}"""
-
失败定义:
- 包含重复文本片段
- 包含重复序列
-
修正模型: Meta-Llama-3-8B
短描述生成
-
提示: py prompt = lambda img_prompt: f""" Please take the following image caption and attempt to distill it into a single sentence. Remove any redundant lines or descriptions and make it a maximum of 30 words in length.
{img_prompt}Please only write the caption and no other text. """
数据集限制
- 偏差: 偏向于多标签分类器识别的概念
- 已知限制:
- 可能存在少量错误描述
- 未评估安全性,依赖于 Kakao Brain 的 NSFW 过滤方案
- 未过滤 blurry 和 watermark 标签
附加信息
数据集管理者
- 管理者: Caption Emporium
许可信息
引用信息
@misc{coyo-hd-11m-llavanext, author = { Caption Emporium }, title = { coyo-hd-11m-llavanext }, year = { 2024 }, publisher = { Huggingface }, journal = { Huggingface repository }, howpublished = {url{https://huggingface.co/datasets/CaptionEmporium/coyo-hd-11m-llavanext}}, }