SingNet
收藏arXiv2025-05-14 更新2025-05-16 收录
下载链接:
https://singnet-dataset.github.io/
下载链接
链接失效反馈官方服务:
资源简介:
SingNet是一个大规模、多样化且在野的歌唱声音数据集,旨在解决歌唱声音合成(SVS)和歌唱声音转换(SVC)等领域中大规模和多样化数据集的缺乏问题。该数据集包含来自互联网上的歌曲和样本包中的3000小时歌唱声音,涉及多种语言和风格。为了促进使用和展示SingNet的有效性,研究者在Wav2vec2、BigVGAN和NSF-HiFiGAN等模型上进行了预训练,并在自动歌词转录(ALT)、神经声码器和歌唱声音转换(SVC)等领域进行了基准实验。该数据集的创建过程涉及从歌曲和样本包中提取干燥的歌唱声音,并使用最先进的深度学习方法、数字信号处理(DSP)算法和虚拟工作室技术(VST)插件进行处理。SingNet的数据集描述信息,包括数据集名称、创建机构、简要描述等;数据集的内容,例如数据集大小、数据量、Tokens数、数据来源等;数据集创建过程;数据集的应用领域,旨在解决歌唱声音合成和转换等问题。
SingNet is a large-scale, diverse, real-world singing voice dataset developed to address the scarcity of large-scale and diversified datasets in fields such as singing voice synthesis (SVS) and singing voice conversion (SVC). This dataset contains 3000 hours of singing voices sourced from online songs and sample packs, covering multiple languages and musical styles. To facilitate its usage and verify the effectiveness of SingNet, researchers conducted pre-training on models including Wav2vec2, BigVGAN, and NSF-HiFiGAN, and performed benchmark experiments in domains such as automatic lyric transcription (ALT), neural vocoding, and singing voice conversion (SVC). The dataset creation process involves extracting dry, isolated singing voices from songs and sample packs, and processing them using state-of-the-art deep learning methods, digital signal processing (DSP) algorithms, and virtual studio technology (VST) plugins. The descriptive information of SingNet includes the dataset name, creating institution, brief overview, etc.; the dataset content covers its scale, total data volume, number of Tokens, data sources, etc.; the dataset creation process; and its application fields, which aim to solve problems such as singing voice synthesis and conversion.
提供机构:
香港中文大学(深圳)数据科学学院
创建时间:
2025-05-14
搜集汇总
数据集介绍
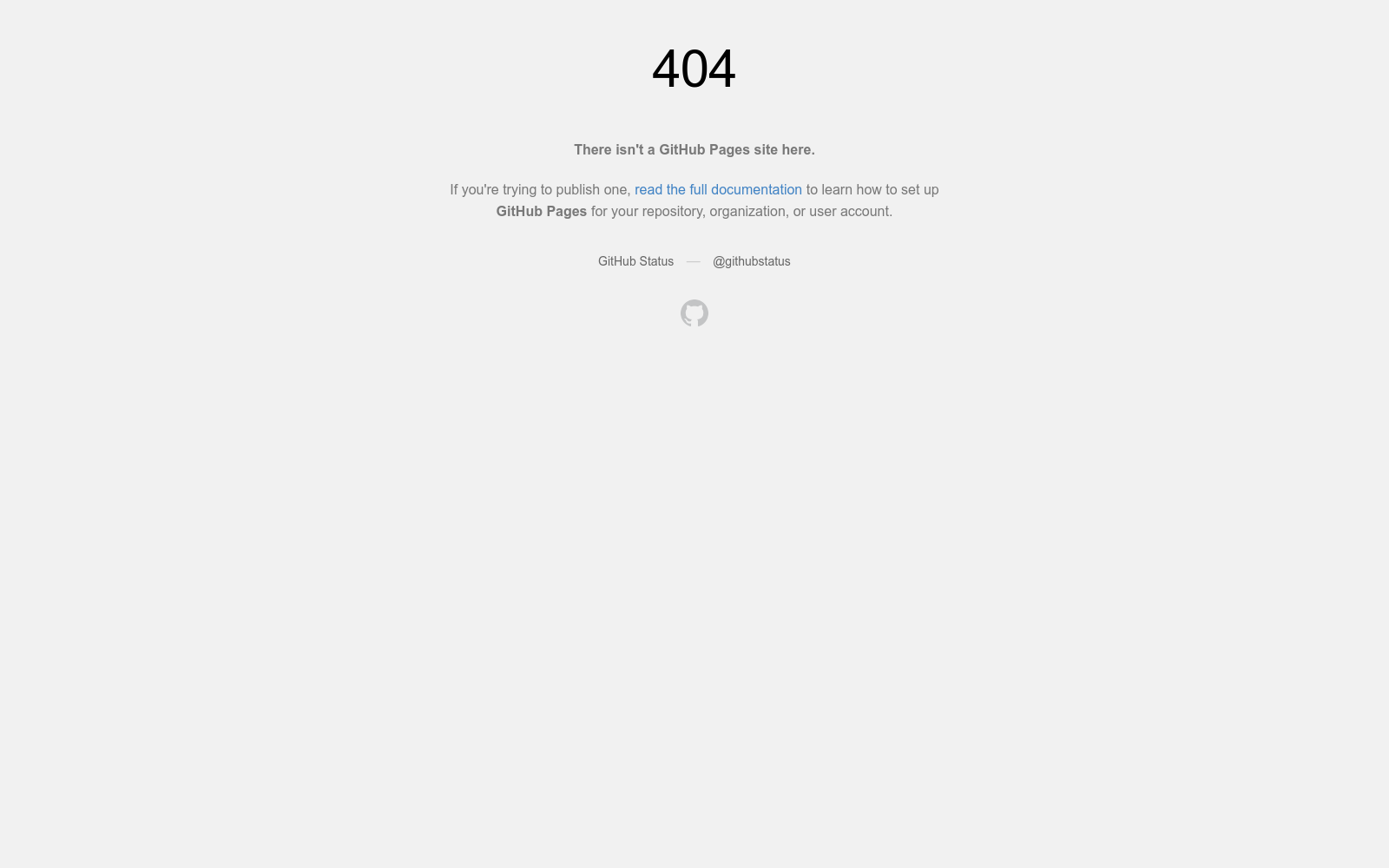
构建方式
SingNet数据集的构建采用了先进的数据处理流程,从互联网上的样本包和歌曲中提取可直接用于训练的歌唱声音数据。具体而言,通过源分离技术从歌曲中提取湿润歌唱声音,再通过音频恢复技术处理为干燥声音;同时利用半监督标注系统从样本包中提取干燥歌唱声音。整个流程结合了深度学习、数字信号处理(DSP)和虚拟工作室技术(VST)插件,最终形成了3000小时的多语言、多风格歌唱声音数据集。
特点
SingNet数据集以其规模庞大、多样性丰富和真实场景数据著称。该数据集包含2629小时来自真实歌曲和321小时来自样本包的歌唱声音,覆盖多种语言(如英语、日语、中文等)和风格(如流行、ACG、EDM等)。其独特之处在于数据的多样性和真实场景下的录音环境,为歌唱声音合成(SVS)和歌唱声音转换(SVC)等任务提供了高质量的基准数据。
使用方法
SingNet数据集的使用方法灵活多样,适用于多种歌唱声音相关任务。研究人员可以通过预训练的Wav2vec2、BigVGAN和NSF-HiFiGAN模型直接利用数据集进行自动歌词转录(ALT)、神经声码器和歌唱声音转换(SVC)等任务。此外,数据集支持动态扩展,用户可通过开源的数据处理流程进一步扩展数据规模。音频样本和预训练模型可通过官方演示页面获取,为后续研究提供了便利。
背景与挑战
背景概述
SingNet数据集由香港中文大学(深圳)数据科学学院的研究团队于2025年提出,旨在解决歌唱语音合成(SVS)和歌唱语音转换(SVC)等领域长期缺乏大规模、多样化公开数据集的问题。该数据集通过创新的数据处理流程,从互联网上的样本包和歌曲中提取了3000小时的歌唱语音数据,涵盖多种语言和风格。SingNet的推出显著推动了歌唱语音相关研究的发展,为学术界和工业界提供了宝贵的资源。
当前挑战
SingNet面临的挑战主要包括两个方面:领域问题的挑战和构建过程的挑战。在领域问题方面,歌唱语音合成与转换需要处理复杂的音高、音色和歌词同步问题,而现有数据集往往规模有限且多样性不足。在构建过程中,研究人员需克服从非结构化音频中分离纯净人声的技术难题,包括去除伴奏、降噪、消除混响等。此外,数据标注的准确性和多语言多风格数据的平衡也是构建过程中需要解决的关键问题。
常用场景
经典使用场景
SingNet数据集在歌唱语音合成(SVS)和歌唱语音转换(SVC)领域具有广泛的应用。其大规模、多语言和多风格的特性使其成为训练高质量歌唱语音生成模型的理想选择。研究人员可以利用该数据集构建先进的歌唱语音合成系统,生成自然且富有表现力的歌唱声音。此外,该数据集还支持歌唱语音转换任务,实现不同歌手音色的转换,同时保持原始歌词和旋律的完整性。
衍生相关工作
SingNet的发布催生了一系列相关研究工作。基于该数据集,研究人员开发了先进的Wav2vec2、BigVGAN和NSF-HiFiGAN模型,显著提升了歌唱语音合成的质量。此外,SingNet还促进了歌唱语音转换技术的进步,特别是零样本SVC模型的发展。这些衍生工作不仅验证了SingNet的有效性,还进一步推动了歌唱语音研究领域的创新。
数据集最近研究
最新研究方向
SingNet作为首个大规模、多语言、多样化的歌唱语音数据集,显著推动了歌唱语音合成(SVS)与转换(SVC)领域的研究边界。其突破性在于通过开源数据处理流程,从互联网样本包和歌曲中自动化提取高质量训练数据,解决了传统歌唱数据集因专业录制成本高昂导致的规模与多样性局限。当前研究聚焦三大方向:其一,基于3000小时数据的自监督学习(如Wav2vec2预训练模型)在自动歌词转录(ALT)任务中实现了无需语音模型迁移的直接优化,词错率(WER)降至6.76%;其二,结合BigVGAN与NSF-HiFiGAN的神经声码器在野外音频测试中展现出卓越的频谱重建能力(MCD 2.164),验证了大规模数据对声学特征泛化性的提升;其三,零样本SVC系统通过3500小时数据训练,在跨语言歌手相似度(SIM 0.746)和主观自然度(MOS 3.73±0.19)上树立了新基准。该数据集还促进了多模态音乐生成与低资源语种歌唱技术的交叉研究,成为驱动歌唱AI工业化应用的核心基础设施。
相关研究论文
- 1SingNet: Towards a Large-Scale, Diverse, and In-the-Wild Singing Voice Dataset香港中文大学(深圳)数据科学学院 · 2025年
以上内容由遇见数据集搜集并总结生成


