CCPD
收藏Hugging Face2025-11-22 更新2025-11-23 收录
下载链接:
https://huggingface.co/datasets/PoetryMTEB/CCPD
下载链接
链接失效反馈官方服务:
资源简介:
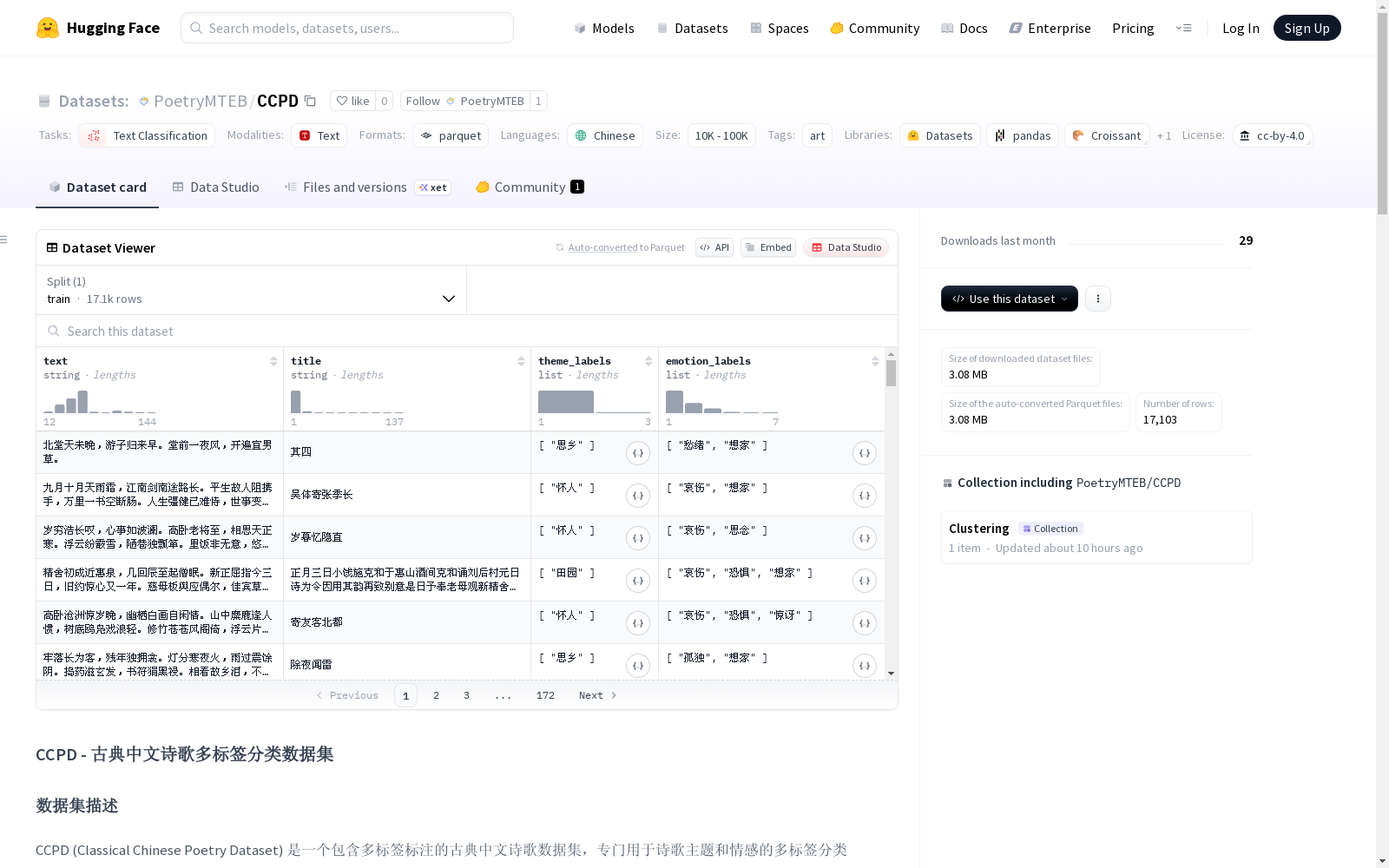
CCPD (古典中文诗歌多标签分类数据集) 是一个专为诗歌主题和情感多标签分类研究设计的古典中文诗歌数据集,包含17103首诗歌,每个诗歌标注有主题和情感标签。数据集分为训练集,并提供了包括诗歌正文、标题、主题标签和情感标签在内的多种特征。
CCPD (Classical Chinese Poetry Multi-label Classification Dataset) is a classical Chinese poetry dataset specifically designed for research on multi-label classification of poetry themes and sentiments. It comprises 17,103 poems, each annotated with both thematic and sentiment labels. The dataset is split into the training set, and offers multiple features including the full poem text, title, thematic labels and sentiment labels.
创建时间:
2025-11-20
原始信息汇总
CCPD - 古典中文诗歌多标签分类数据集
数据集概述
CCPD (Classical Chinese Poetry Dataset) 是一个包含多标签标注的古典中文诗歌数据集,专门用于诗歌主题和情感的多标签分类研究。
基本信息
- 诗歌数量: 17103首
- 主题标签数量: 10个
- 情感标签数量: 13个
- 数据划分: 全部作为训练集
- 许可证: CC-BY-4.0
- 语言: 中文
- 任务类别: 文本分类
- 标签: 艺术
- 数据规模: 10K<n<100K
数据格式
原始数据格式为:主题标签#主题标签,情感标签#情感标签,标题,正文
处理后的数据格式: python { "text": "诗歌正文", "title": "诗歌标题", "theme_labels": ["主题1", "主题2"], # 主题标签列表 "emotion_labels": ["情感1", "情感2"] # 情感标签列表 }
标签统计
前10个最常见主题标签
- 思乡: 9010次
- 怀人: 2263次
- 田园: 1213次
- 战争: 1139次
- 山水: 1071次
- 怀古: 689次
- 闺怨: 650次
- 悼亡: 576次
- 咏物: 566次
- 送别: 314次
前10个最常见情感标签
- 想家: 12327次
- 哀伤: 3645次
- 愁绪: 3548次
- 孤独: 1646次
- 失意: 1576次
- 思念: 1468次
- 流泪: 953次
- 恐惧: 933次
- 怨恨: 682次
- 喜悦: 522次
任务应用
- 多标签文本分类
- 诗歌主题分析
- 情感分析
- 古典文学研究
- 跨任务迁移学习
数据划分建议
- 传统划分: 70%训练,15%验证,15%测试
- 交叉验证: 使用K折交叉验证
- 留出法: 保留部分数据作为测试集
使用限制
本数据集仅用于学术研究目的。
搜集汇总
数据集介绍
构建方式
在古典文学数字化研究领域,CCPD数据集通过系统整理17103首古典诗歌构建而成。其构建过程采用多标签标注体系,原始数据以结构化格式记录诗歌的标题、正文及对应的主题与情感标签。经过专业处理,数据被转化为包含文本内容、标题以及主题与情感标签列表的标准化格式,为诗歌的多维度分析奠定坚实基础。
特点
该数据集在古典诗歌研究领域展现出鲜明的多标签特性,涵盖10个主题类别和13种情感维度。主题标签中思乡、怀人等高频类别揭示了古典诗歌的核心题材倾向,情感标签则呈现出以想家、哀伤为主导的丰富情感谱系。每个诗歌样本可同时关联多个主题与情感标签,精准反映了古典文学作品内涵的复杂性与多元性。
使用方法
研究者可通过HuggingFace平台直接加载该数据集进行多标签分类任务。数据集支持主题分类、情感分析及联合分类三种应用模式,使用者需根据研究目标自行划分训练集、验证集和测试集。典型应用包括采用传统70-15-15比例划分或交叉验证方法,实现对古典诗歌主题特征与情感表达的深度挖掘。
背景与挑战
背景概述
古典中文诗歌作为中华文化瑰宝,其数字化研究在自然语言处理领域具有重要价值。CCPD数据集由研究机构于近期构建,聚焦于诗歌文本的多维度语义解析,涵盖17103首古典诗歌作品。该数据集通过系统标注10类主题标签与13类情感标签,致力于解决古典文学计算分析中语义单元细粒度识别这一核心问题,为诗歌自动分类、情感计算及文化传承研究提供了标准化数据基础。
当前挑战
在古典诗歌多标签分类领域,主要挑战在于诗歌语言的隐喻性与多义性特征,导致主题与情感标签的边界模糊。数据构建过程中面临标注一致性难题,需平衡古典文学专家知识与现代计算标签体系的适配性。同时,诗歌文本的格律约束与典故化用现象,对机器学习模型的特征提取能力提出更高要求。现有数据规模虽达万级,但长尾标签的稀疏分布仍制约着分类器的泛化性能。
常用场景
经典使用场景
在古典文学计算分析领域,CCPD数据集凭借其多标签标注体系,为诗歌主题与情感的双重识别提供了标准化实验平台。该数据集常被用于构建多标签分类模型,通过深度学习架构同时捕捉诗歌中交织的思乡、怀古等主题元素与哀伤、愁绪等情感维度,有效推进了古典诗歌语义解析的自动化进程。
衍生相关工作
基于该数据集衍生的研究已形成系列经典成果,包括融合注意力机制的多标签分类框架、诗歌情感演化追踪模型等。这些工作不仅深化了对唐代至宋代诗歌情感表达模式的理解,更推动了跨朝代诗歌风格比较计算方法的创新,为后续诗歌自动标注系统的优化提供了重要参照。
数据集最近研究
最新研究方向
古典诗歌计算分析领域正聚焦于多模态深度学习框架的构建,CCPD数据集凭借其精细的主题与情感多标签标注体系,为诗歌语义理解提供了结构化基础。当前研究热点集中于基于预训练语言模型的跨任务迁移学习,通过联合建模主题分类与情感分析任务,显著提升了古典文学自动标注系统的泛化能力。随着数字人文研究的深入,该数据集在文化传承智能系统中的创新应用,正推动传统文学研究与人工智能技术的深度融合,为古典诗歌的数字化保护与跨时代解读开辟了新维度。
以上内容由遇见数据集搜集并总结生成


