M4-Instruct-Data
收藏Hugging Face2024-06-26 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/lmms-lab/M4-Instruct-Data
下载链接
链接失效反馈官方服务:
资源简介:
M4-Instruct是一个多图像数据集,用于训练大型多模态模型。数据集收集于2024年4月,来源包括公共数据集和GPT-4V API生成。主要用于研究大型多模态模型和聊天机器人,面向计算机视觉、自然语言处理、机器学习和人工智能领域的研究人员和爱好者。
创建时间:
2024-06-26
原始信息汇总
M4-Instruct 数据集概述
数据集详情
数据集类型: M4-Instruct 是一组多图像数据集,收集自公共数据集或通过 GPT-4V API 生成。该数据集旨在训练具有交错多图像能力的大型多模态模型,例如 LLaVA-NeXT-Interleave。
数据集日期: M4-Instruct 于2024年4月收集,并于2024年6月发布。
数据统计: 该数据集仅发布了 M4-Instruct 的多图像、多帧(视频)和多视图(3D)数据。
数据内容:
- json 文件:m4_instruct_annotations.json 和 m4_instruct_video.json
- 图像:*.zip
- 对于 dreamsim_split.z01 和 dreamsim_split.zip,请运行 "zip -s 0 dreamsim_split.zip --out dreamsim.zip"
许可证: Creative Commons Attribution 4.0 International;并应遵守 OpenAI 的政策:https://openai.com/policies/terms-of-use
问题和评论的联系方式: fliay@connect.ust.hk 1700012927@pku.edu.cn
预期用途
主要预期用途: M4-Instruct 数据集主要用于大型多模态模型和聊天机器人的研究。
主要预期用户: 该数据集的主要用户是计算机视觉、自然语言处理、机器学习和人工智能领域的研究人员和爱好者。
搜集汇总
数据集介绍
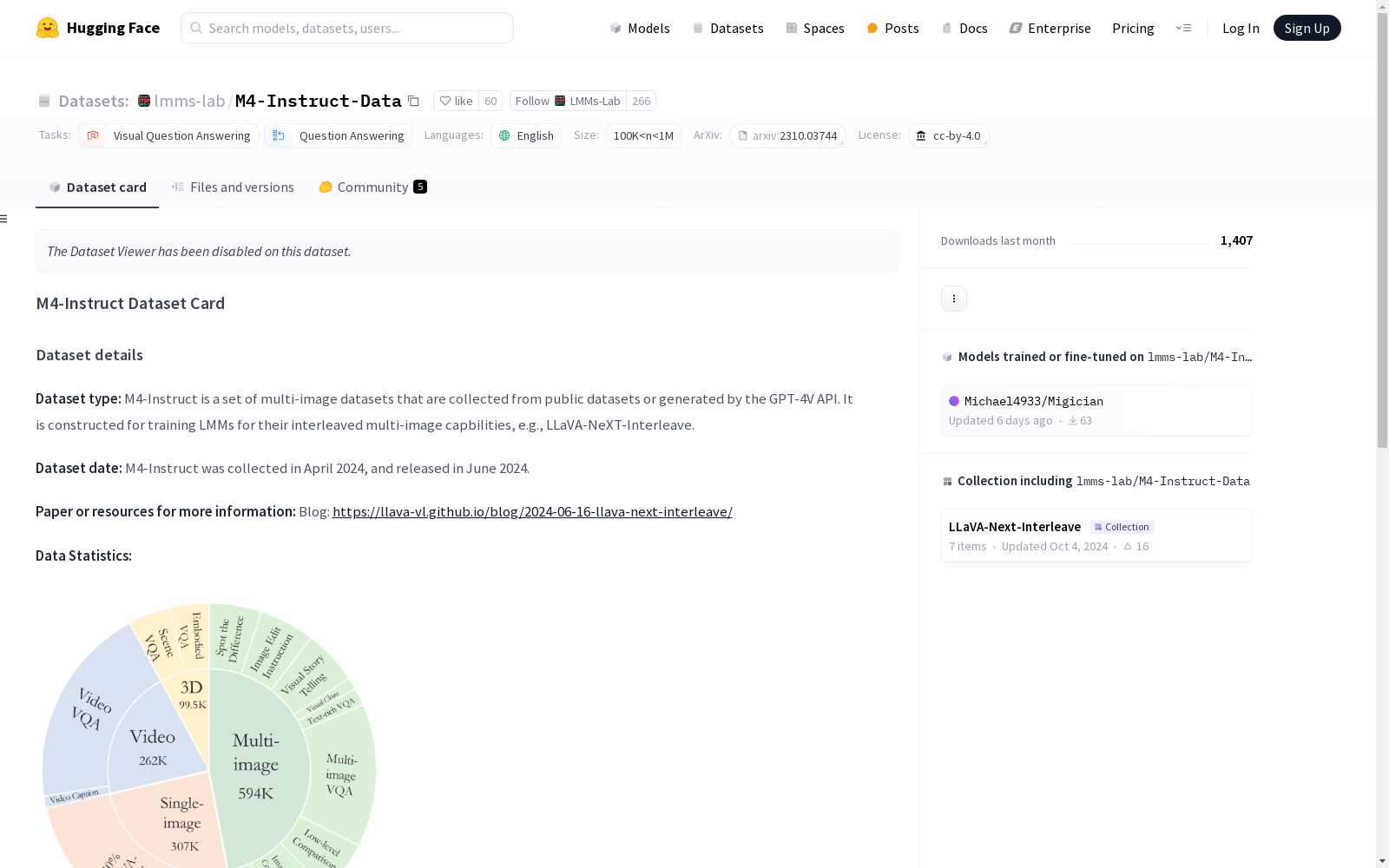
构建方式
M4-Instruct数据集是一个多图像数据集,其数据来源于公开数据集或通过GPT-4V API生成。该数据集专为训练大型多模态模型(LMMs)的多图像交错处理能力而构建,例如LLaVA-NeXT-Interleave模型。数据集的构建过程包括从LLaVA-Hound下载视频数据,并按照指令进行组织,同时补充了LLaVA-1.5的第二阶段SFT数据中的单图像数据。
特点
M4-Instruct数据集的特点在于其多图像、多帧(视频)和多视角(3D)数据的丰富性。数据集包含json格式的注释文件和视频文件,以及压缩的图像文件。这些数据为研究多模态模型提供了多样化的输入类型,能够有效支持模型在多图像交错处理任务中的训练和评估。
使用方法
M4-Instruct数据集主要用于大型多模态模型和聊天机器人的研究。研究人员可以通过下载数据集中的json文件、图像和视频文件,结合LLaVA-Hound的视频数据,进行模型的训练和评估。此外,数据集的使用需遵循Creative Commons Attribution 4.0 International许可,并遵守OpenAI的使用政策。
背景与挑战
背景概述
M4-Instruct数据集于2024年4月收集,并于同年6月发布,旨在支持大规模多模态模型(LMMs)的训练,特别是针对多图像交错处理能力的研究。该数据集由公开数据集和GPT-4V API生成的数据组成,主要用于增强模型在多图像、多帧视频和多视角3D数据上的表现。其核心研究问题在于如何通过多模态数据的交错训练,提升模型在复杂视觉任务中的理解和生成能力。M4-Instruct的发布为多模态模型的研究提供了重要的数据支持,推动了视觉问答和自然语言处理领域的交叉研究。
当前挑战
M4-Instruct数据集在构建和应用过程中面临多重挑战。首先,多模态数据的交错处理要求模型能够同时理解图像、视频和3D数据,这对模型的架构设计和训练策略提出了极高的要求。其次,数据集的构建依赖于GPT-4V API生成的数据,如何确保生成数据的多样性和质量是一个关键问题。此外,数据集的规模较大,涉及多图像和多帧视频的标注与组织,这对数据处理和存储提出了较高的技术要求。最后,如何将M4-Instruct与其他单图像数据集(如LLaVA-1.5)有效结合,以实现更全面的模型训练,也是研究者需要解决的难题。
常用场景
经典使用场景
M4-Instruct数据集在视觉问答和多模态模型训练中具有重要应用。该数据集通过整合多图像、多帧视频和多视角3D数据,为研究者提供了一个丰富的训练环境,特别适用于提升大模型在跨图像理解与推理方面的能力。经典使用场景包括训练如LLaVA-NeXT-Interleave等模型,以增强其在多图像任务中的表现。
实际应用
在实际应用中,M4-Instruct数据集被广泛用于开发智能客服、教育辅助系统和医疗影像分析等领域。其多图像和多帧视频数据为这些应用提供了更丰富的上下文信息,从而提升了模型在实际场景中的表现和用户体验。
衍生相关工作
M4-Instruct数据集衍生了一系列经典研究工作,如LLaVA-NeXT-Interleave模型的开发。这些工作不仅推动了多模态模型在多图像任务中的性能提升,还为后续研究提供了宝贵的数据和模型框架,进一步拓展了多模态学习的研究边界。
以上内容由遇见数据集搜集并总结生成


