hashed_data
收藏Hugging Face2025-12-06 更新2025-12-07 收录
下载链接:
https://huggingface.co/datasets/humair025/hashed_data
下载链接
链接失效反馈官方服务:
资源简介:
Munch Hashed Index 是一个轻量级的参考数据集,为 [Munch Urdu TTS Dataset](https://huggingface.co/datasets/humair025/Munch) 中的所有音频文件提供 SHA-256 哈希值。该数据集不存储 1.27 TB 的原始音频,而是仅存储元数据和加密哈希值,从而实现:
- ✅ **快速重复检测** 跨越 417 万个音频样本
- ✅ **高效数据集探索** 无需下载数 TB 数据
- ✅ **快速元数据查询**(语音分布、文本统计等)
- ✅ **选择性音频检索** - 仅下载所需内容
- ✅ **存储效率** - 节省 99.92% 空间(1.27 TB → ~1 GB)
创建时间:
2025-12-05
原始信息汇总
Munch Hashed Index 数据集概述
基本信息
- 数据集名称: Munch Hashed Index - Lightweight Audio Reference Dataset
- 创建者: Humair Munir
- 发布日期: 2025年12月
- 许可证: Creative Commons Attribution 4.0 International (CC-BY-4.0)
- 任务类别: 文本生成、文本转语音、自动语音识别
- 语言: 乌尔都语 (Urdu)
- 标签: Urdu
- 数据集状态: 完整
数据集描述
Munch Hashed Index 是一个轻量级参考数据集,它为 Munch Urdu TTS 数据集 中的所有音频文件提供 SHA-256 哈希值。该数据集不存储 1.27 TB 的原始音频,而是仅存储元数据和加密哈希值。
核心价值
- 快速重复检测: 在 417 万个音频样本中快速检测重复项。
- 高效数据集探索: 无需下载数 TB 数据即可探索数据集。
- 快速元数据查询: 查询语音分布、文本统计等信息。
- 选择性音频检索: 仅下载所需音频。
- 存储效率: 实现 99.92% 的空间缩减(从 1.27 TB 减少到约 1 GB)。
数据集结构
数据字段
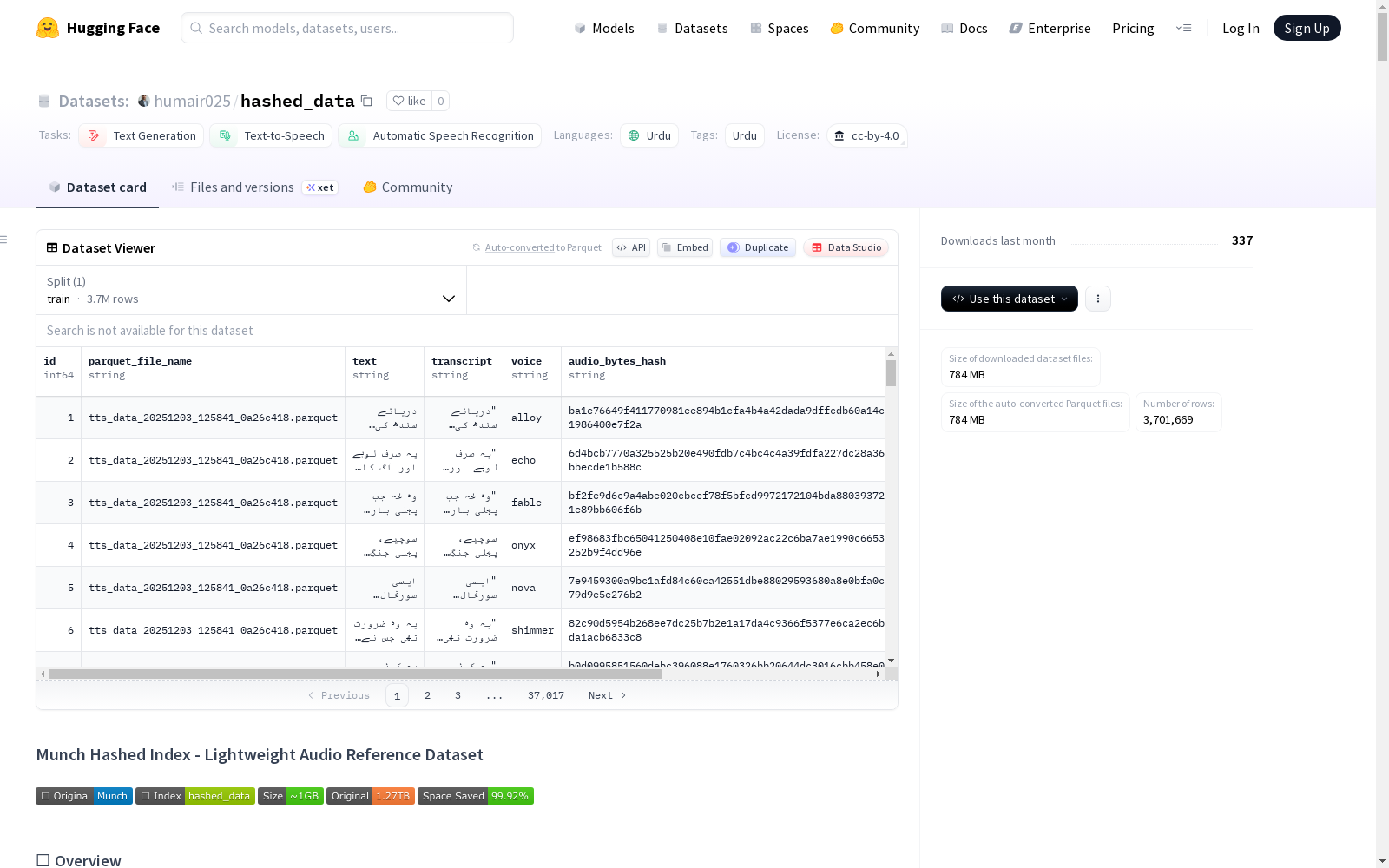
| 字段 | 类型 | 描述 |
|---|---|---|
id |
int | 源数据集中的原始段落 ID |
parquet_file_name |
string | 源文件在 Munch 数据集中的名称 |
text |
string | 原始乌尔都语文本 |
transcript |
string | TTS 转录文本(可能与输入不同) |
voice |
string | 使用的语音(alloy, echo, fable, onyx, nova, shimmer, coral, verse, ballad, ash, sage, amuch, dan) |
audio_bytes_hash |
string | audio_bytes 的 SHA-256 哈希值(64 位十六进制字符) |
audio_size_bytes |
int | 原始音频的字节大小 |
timestamp |
string | 生成的 ISO 时间戳(可为空) |
error |
string | 生成失败时的错误信息(可为空) |
数据规模
- 总记录数: 4,167,500
- 总文件数: 约 8,300 个 parquet 文件
- 语音数量: 13 种
- 语言: 乌尔都语(主要)
- 平均音频大小: 每个样本约 50-60 KB
- 平均持续时间: 每个样本约 3-5 秒
- 总持续时间: 约 3,500-5,800 小时的音频
相关数据集
- 原始数据集: humair025/Munch - 完整音频数据集(1.27 TB)
- 此索引: humair025/hashed_data - 哈希参考数据集(约 1 GB)
- Munch-1 (v2): humair025/munch-1 - 新版本(3.28 TB,3.86M 样本)
- Munch-1 索引: humair025/hashed_data_munch_1 - v2 版本的索引
使用案例
- 数据集质量分析: 检查重复项、分析语音分布、查找失败的生成。
- 高效数据探索: 在不下载音频的情况下浏览数据集,按条件筛选。
- 选择性下载: 仅下载特定语音或特定大小的音频样本。
- 去重管道: 创建去重后的子集。
- 音频相似性搜索: 通过哈希前缀查找相似的音频。
性能指标
- 加载完整数据集: 10-30 秒
- 哈希查找: < 10 毫秒
- 语音筛选: < 50 毫秒
- 完整数据集扫描: < 5 秒
引用信息
BibTeX
bibtex @dataset{munch_hashed_index_2025, title={Munch Hashed Index: Lightweight Reference Dataset for Urdu TTS}, author={Munir, Humair}, year={2025}, publisher={Hugging Face}, howpublished={url{https://huggingface.co/datasets/humair025/hashed_data}}, note={Index of humair025/Munch dataset with SHA-256 audio hashes} }
@dataset{munch_urdu_tts_2025, title={Munch: Large-Scale Urdu Text-to-Speech Dataset}, author={Munir, Humair}, year={2025}, publisher={Hugging Face}, howpublished={url{https://huggingface.co/datasets/humair025/Munch}} }
重要链接
- 原始音频数据集: https://huggingface.co/datasets/humair025/Munch
- 此哈希索引: https://huggingface.co/datasets/humair025/hashed_data
- Munch-1 (v2): https://huggingface.co/datasets/humair025/munch-1
- Munch-1 索引: https://huggingface.co/datasets/humair025/hashed_data_munch_1
- 讨论区: https://huggingface.co/datasets/humair025/hashed_data/discussions
- 问题报告: https://huggingface.co/datasets/humair025/hashed_data/discussions
搜集汇总
数据集介绍
构建方式
在语音合成领域,大规模数据集的存储与检索常面临效率挑战。该数据集通过自动化流水线构建,从原始Munch乌尔都语语音合成数据集中批量下载约8300个Parquet文件,逐条计算音频字节的SHA-256哈希值,同时提取文本、语音特征、时间戳等元数据,最终生成仅保留哈希指纹与元数据的轻量化索引。该流程采用分批处理机制与断点续传设计,在确保数据完整性的同时,实现了原始1.27TB音频数据至约1GB索引的极致压缩。
特点
作为语音数据管理的创新范式,该数据集的核心特征在于其密码学哈希与元数据的精巧结合。每一条记录均包含64位十六进制SHA-256哈希值,为音频内容提供唯一且不可逆的数字指纹,支持毫秒级重复检测与精确匹配。数据集完整覆盖417.75万条音频-文本对,保留13种语音特征、文本转录及生成时间戳等丰富元数据,而体积仅为原始数据的0.08%。这种设计使得研究者能够在有限资源下,快速完成数据质量评估、语音分布分析和选择性检索等任务。
使用方法
在语音计算研究中,该数据集提供了高效的数据探索与精准检索方案。用户可通过标准数据集加载接口快速载入索引,利用Pandas等工具进行哈希查询、语音分类或文本筛选。基于哈希值可定位重复音频并生成去重子集,结合parquet_file_name字段可定向下载原始音频文件。典型工作流包括:先通过索引筛选目标数据子集,再根据文件引用从原始数据集选择性加载对应音频,从而实现存储开销与计算需求的平衡。
背景与挑战
背景概述
在低资源语言语音技术领域,大规模高质量数据集的构建是推动模型发展的关键。Munch Hashed Index数据集由研究人员Humair Munir于2025年创建,作为原始Munch乌尔都语文本转语音数据集的轻量化索引。该数据集的核心研究问题在于解决海量音频数据(原始规模达1.27TB,包含417万条样本)带来的存储与访问效率瓶颈。通过提取音频文件的SHA-256哈希值与元数据,该索引在保持数据完整参照能力的同时,将存储需求压缩了99.92%,显著降低了研究人员在数据探索、去重和选择性检索时的资源门槛,为乌尔都语语音合成与识别研究提供了高效的数据管理范式。
当前挑战
该数据集旨在应对大规模语音数据集管理中的核心挑战:如何在有限的计算资源下实现对海量音频数据的快速查询与去重。具体而言,原始Munch数据集包含约8300个分散的Parquet文件,使得直接进行全局数据分析、重复样本检测或基于语音、文本等属性的筛选变得极为耗时耗力。在构建过程中,主要挑战包括设计可扩展的流水线以批量处理数TB的音频文件、确保哈希计算与元数据提取的准确性与一致性,以及建立高效的数据结构以支持对数百万条记录的亚秒级查询。这些技术障碍的克服,使得轻量级索引能够在不存储原始音频的前提下,为下游任务提供可靠的数据导航基础。
常用场景
经典使用场景
在乌尔都语语音合成研究领域,大规模音频数据集的探索与管理常受限于海量存储需求。Munch Hashed Index 通过提供音频文件的SHA-256哈希值与元数据,为研究人员提供了一种经典的高效数据探索范式。用户无需下载原始TB级音频,即可快速执行重复样本检测、语音分布统计及文本内容筛选,从而在资源受限环境下实现对数据集的全面预览与质量控制。
衍生相关工作
围绕该哈希索引数据集,已衍生出多项聚焦于数据高效管理与质量提升的相关工作。例如,基于哈希的跨版本数据一致性校验工具、支持多模态查询的增强型元数据检索系统,以及集成去重与质量过滤的自动化数据预处理流水线。这些工作进一步拓展了索引在语音数据治理、版本控制及分布式协作中的应用边界,推动了语音合成数据生态的标准化进程。
数据集最近研究
最新研究方向
在低资源语言语音处理领域,大规模数据集的高效管理与利用正成为研究热点。Munch Hashed Index 作为乌尔都语文本转语音数据集的轻量化索引,其核心研究方向聚焦于通过密码学哈希技术实现海量音频数据的快速去重与元数据查询。该数据集采用SHA-256哈希算法为原始1.27TB音频生成唯一指纹,在仅占用约1GB存储空间的条件下,支持对417万条样本进行重复检测与选择性检索。这一方法显著降低了数据探索的计算与存储门槛,为乌尔都语等低资源语言的语音合成模型训练提供了高效的数据预处理管道,推动了轻量化索引技术在多语言语音数据集管理中的前沿应用。
以上内容由遇见数据集搜集并总结生成


