michellejieli/friends_dataset
收藏Hugging Face2022-10-23 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/michellejieli/friends_dataset
下载链接
链接失效反馈官方服务:
资源简介:
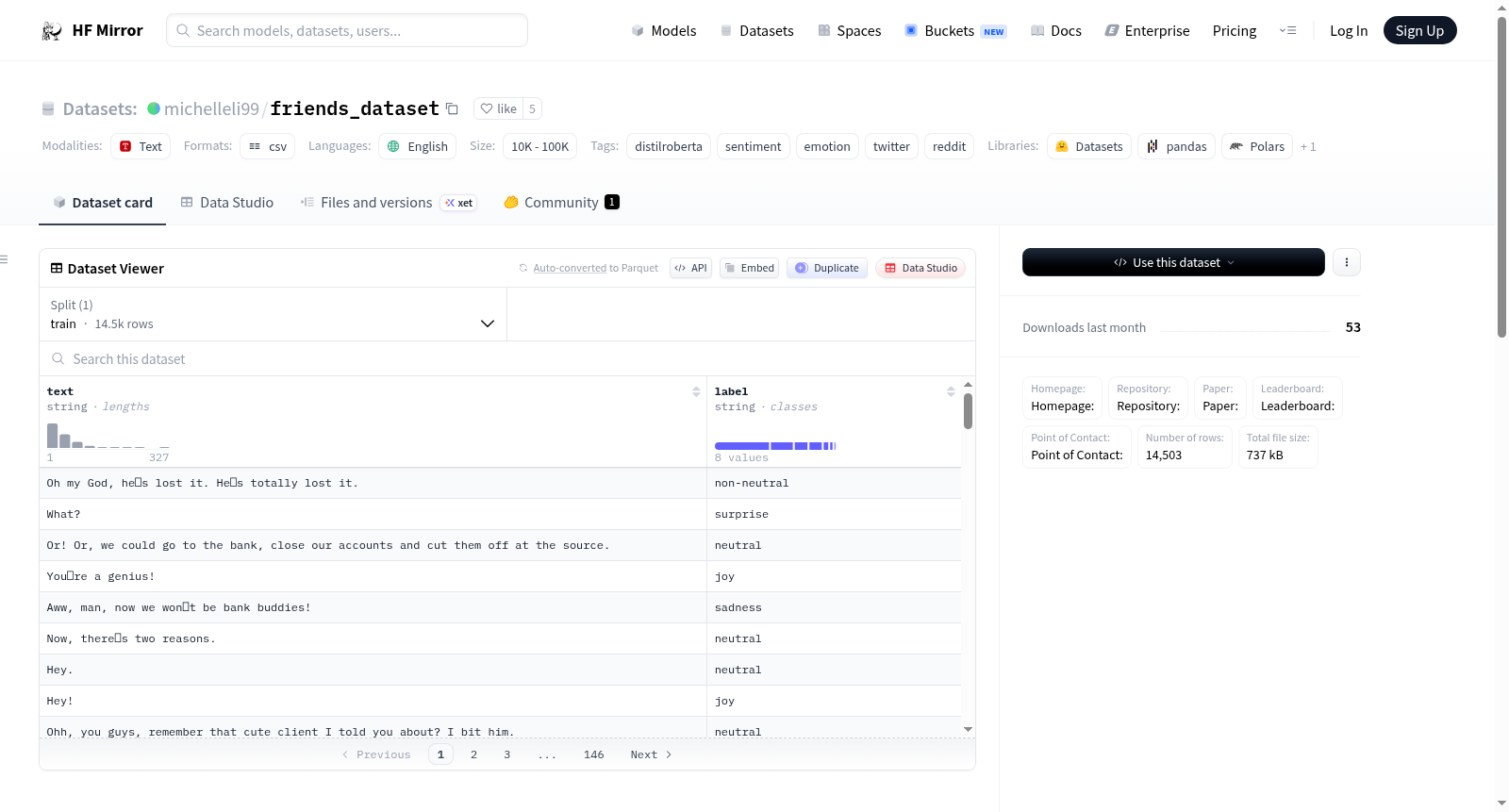
Friends数据集包含来自电视剧《Friends》的对话,主要用于情感分类任务。数据集中的每个数据点包含文本和对应的情感标签。数据集的创建目的是为了微调情感分类器,帮助自闭症患者学习阅读面部表情。数据集中的对话为英语,包含1000个英语对话,原始数据为JSON格式,经过清理后转换为CSV格式。
The Friends dataset comprises dialogues extracted from the TV series *Friends*, and is primarily intended for sentiment classification tasks. Each data point in the dataset includes a text snippet and its corresponding sentiment label. The dataset was created with the goal of fine-tuning sentiment classifiers to help autistic individuals learn to read facial expressions. All dialogues in the dataset are in English, with a total of 1000 English dialogues. The original raw data was stored in JSON format, and was cleaned and subsequently converted to CSV format.
提供机构:
michellejieli
原始信息汇总
数据集概述
数据集描述
数据集总结
- 内容来源:Friends TV sitcom的对话内容。
- 提取来源:SocialNLP EmotionX 2019 challenge。
- 主要用途:用于预测文本输入的情感标签。
支持的任务和排行榜
- 任务类型:文本分类、情感分类。
语言
- 语言:英语。
数据集结构
数据实例
-
实例组成:每个数据点包含文本和相应的标签。
-
示例:
{ text: Well! Well! Well! Joey Tribbiani! So you came back huh?, label: surprise }
数据字段
- 字段组成:文本列和相应的情感标签。
数据集创建
数据整理理由
- 原始格式:原始数据为JSON文件,包含对话对象,每个对象包含说话者、话语、情感和注释字符串。
- 数据处理:从原始文件中提取话语和情感,转换为CSV文件,并清理非中性标签。
- 创建目的:用于微调情感分类器,帮助自闭症个体学习解读面部表情。
搜集汇总
数据集介绍
构建方式
在情感计算领域,高质量标注数据集的构建对于模型性能至关重要。该数据集源自经典情景喜剧《老友记》的对话文本,通过提取SocialNLP EmotionX 2019挑战赛中的原始JSON文件构建而成。原始数据包含说话者、话语、情感标签及注释字段,研究者从中筛选出话语与情感标签对,并移除非中性标签,最终形成包含1000条英文对话的标准化CSV格式数据集。这一过程注重数据清洗与结构化转换,为情感分类任务提供了纯净的语料基础。
使用方法
该数据集主要应用于文本分类任务,特别是细粒度情感分类模型的训练与评估。使用者可直接加载CSV格式数据,将文本字段作为输入特征,情感标签作为预测目标,用于微调预训练语言模型如DistilRoBERTa。在实际应用中,建议按照标准机器学习流程划分训练集与测试集,并注意对话语境连续性可能带来的数据依赖性。鉴于数据来源于影视作品,在泛化至其他领域时需考虑领域适应性问题,同时遵循数据使用伦理规范。
背景与挑战
背景概述
在情感计算与自然语言处理领域,对话情感分析是理解人类社交互动的关键研究方向。michellejieli/friends_dataset数据集源于2019年SocialNLP EmotionX挑战赛,由研究人员基于经典美剧《老友记》的对话构建而成。该数据集聚焦于从多轮对话中识别细粒度情感类别,旨在推动对话式情感识别模型的发展,并为自闭症患者的情感认知辅助训练提供潜在支持。其创建融合了影视文本与人工标注,体现了跨媒体数据在情感分析中的创新应用。
当前挑战
该数据集致力于解决对话场景下的细粒度情感分类问题,其核心挑战在于捕捉口语化、语境依赖及隐含情感的表达。构建过程中,数据源自剧本化对话,可能缺乏真实交流的随机性与复杂性;同时,情感标签的标注易受主观判断影响,且类别分布可能存在偏差。此外,影视文本的戏剧化特征可能限制模型在自然对话中的泛化能力,而数据清洗过程中对非中性标签的剔除也需谨慎权衡信息损失与噪声去除之间的平衡。
常用场景
经典使用场景
在情感计算与自然语言处理领域,michellejieli/friends_dataset以其源自经典美剧《老友记》的对话文本,为情感分类任务提供了丰富的语境化语料。该数据集通过标注每句台词对应的情感标签,如惊喜、愤怒或悲伤,成为训练和评估情感分析模型的基准资源。研究者常利用这些标注数据,构建深度学习模型以自动识别文本中的细微情感变化,推动对话系统在理解人类情绪方面的进展。
解决学术问题
该数据集有效应对了情感分析研究中语境依赖性强、标注稀疏的挑战。通过提供真实对话场景中的情感标注,它帮助学术界探索多轮对话中情感的动态演变,解决了传统静态文本数据在捕捉交互情感时的不足。其意义在于促进了细粒度情感分类模型的发展,为自闭症辅助教育等跨学科研究提供了数据基础,深化了人机交互中对情感智能的理解。
实际应用
在实际应用中,该数据集的情感分类能力被整合到心理健康监测工具中,用于分析社交媒体或客服对话中的用户情绪趋势。例如,在自闭症干预项目中,基于此数据集训练的模型可辅助患者学习识别他人情感表达,提升社交技能。同时,企业利用其优化聊天机器人,使自动回复更具共情力,改善用户体验并支持情感驱动的决策分析。
数据集最近研究
最新研究方向
在情感计算领域,michellejieli/friends_dataset作为基于《老友记》剧集对话构建的情感分类资源,正推动着多模态情感识别与上下文感知模型的前沿探索。该数据集源自SocialNLP EmotionX 2019挑战赛,其对话文本蕴含丰富的社会互动情境,为研究动态情感演变与角色特定表达模式提供了独特语料。当前研究热点聚焦于结合语音韵律与视觉线索的跨模态融合方法,以提升在复杂社交场景中的情感预测鲁棒性。相关技术已延伸至自闭症辅助干预系统的开发,通过模拟真实对话帮助患者理解非语言情感信号,体现了计算语言学在社会关怀领域的深远影响。
以上内容由遇见数据集搜集并总结生成


