ScienceAgentBench
收藏ScienceAgentBench 数据集概述
数据集描述
ScienceAgentBench 是一个用于评估语言代理在数据驱动科学发现中的新基准。该基准旨在通过严格的任务评估,确保在科学工作流程中对代理的实际能力进行准确评估。
数据集特点
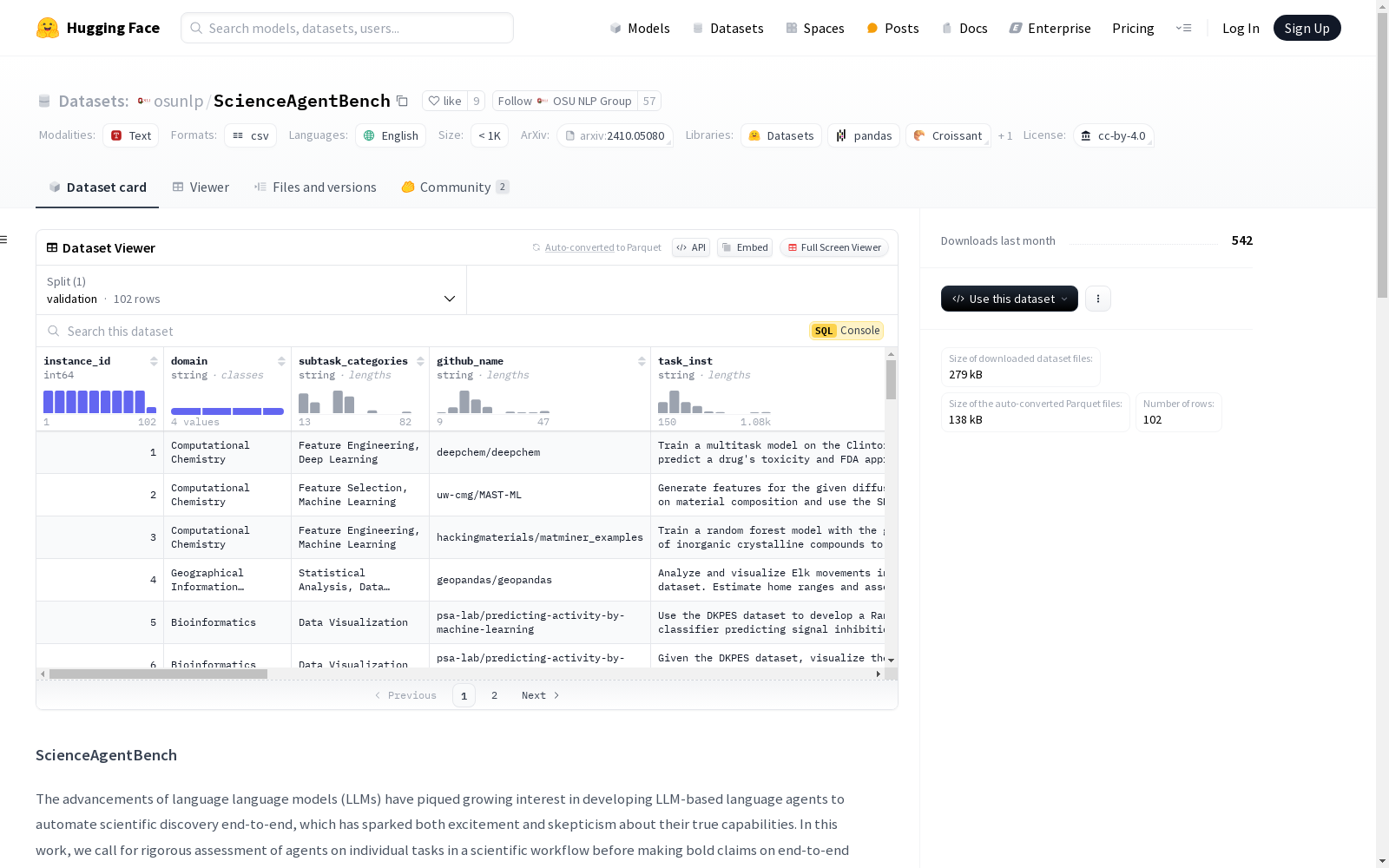
- 任务来源:从44篇同行评审的出版物中提取了102个任务,涵盖四个科学学科。
- 专家验证:九位领域专家参与了任务的验证。
- 输出格式:每个任务的目标输出统一为一个自包含的Python程序文件。
- 多轮验证:每个任务经过多轮手动验证,确保标注质量和科学合理性。
数据集结构
- instance_id (str): 每个任务的唯一ID。
- domain (str): 任务所属的科学学科。
- subtask_categories (str): 任务中涉及的子任务。
- github_name (str): 任务改编自的原始GitHub仓库。
- task_inst (str): 任务目标描述和输出格式指令。
- domain_knowledge (str): 专家标注的任务相关信息。
- dataset_folder_tree (str): 任务数据集目录结构的表示。
- dataset_preview (str): 任务数据集中前几个示例或行的表示。
- src_file_or_path (str): 原始GitHub仓库中改编的源程序位置。
- gold_program_name (str): 每个任务的标注程序(参考解决方案)名称。
- output_fname (str): 生成程序的保存位置。
- eval_script_name (str): 用于检查每个任务成功标准的评估脚本名称。
许可信息
- 大多数任务遵循<a rel="license" href="http://creativecommons.org/licenses/by/4.0/">Creative Commons Attribution 4.0 International License</a>。
- 从rasterio/rasterio和hackingmaterials/matminer改编的任务保留其原始许可。
免责声明
该基准通过改编开源代码和数据构建,尊重原作者的知识产权。如果原作者需要修改或移除相关任务,欢迎提出请求。
引用
如果使用该数据集,请引用相关论文:
@misc{chen2024scienceagentbenchrigorousassessmentlanguage, title={ScienceAgentBench: Toward Rigorous Assessment of Language Agents for Data-Driven Scientific Discovery}, author={Ziru Chen and Shijie Chen and Yuting Ning and Qianheng Zhang and Boshi Wang and Botao Yu and Yifei Li and Zeyi Liao and Chen Wei and Zitong Lu and Vishal Dey and Mingyi Xue and Frazier N. Baker and Benjamin Burns and Daniel Adu-Ampratwum and Xuhui Huang and Xia Ning and Song Gao and Yu Su and Huan Sun}, year={2024}, eprint={2410.05080}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2410.05080}, }