Abirate/english_quotes
收藏Hugging Face2022-10-25 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/Abirate/english_quotes
下载链接
链接失效反馈官方服务:
资源简介:
english_quotes数据集包含从Goodreads网站抓取的所有引用。该数据集可用于多标签文本分类和文本生成任务。每个引用的内容为英文,涉及NLP及其他领域的数据集。数据集中的每个实例包括引用的作者、引用文本和相关标签。数据集通过网页抓取和后续清理处理生成,并以JSON格式存储,未预先分割,用户可以根据需要自行分割。
The english_quotes dataset consists of all quotes scraped from the Goodreads website. This dataset can be applied to multi-label text classification and text generation tasks. Each quote is in English and covers fields including NLP and other related areas. Each instance in the dataset includes the quote author, the quote text, and associated tags. The dataset is generated via web scraping and subsequent data cleaning, stored in JSON format, and has not been pre-split. Users can split it according to their own specific needs.
提供机构:
Abirate
原始信息汇总
数据集概述
一、数据集简介
english_quotes 是一个从 goodreads quotes 网站收集的英语名言数据集。该数据集适用于多标签文本分类和文本生成任务。每个名言均为英语,涉及自然语言处理及其他领域的数据集。
二、支持的任务与评测
- 多标签文本分类:用于训练模型对名言进行作者和主题(通过标签)的分类。成功标准通常是高或低的准确率。
- 文本生成:用于训练模型生成名言,通过在现有预训练模型上对整个名言库(或特定作者的名言)进行微调实现。
三、语言
数据集中的文本语言为英语。
四、数据集结构
数据实例
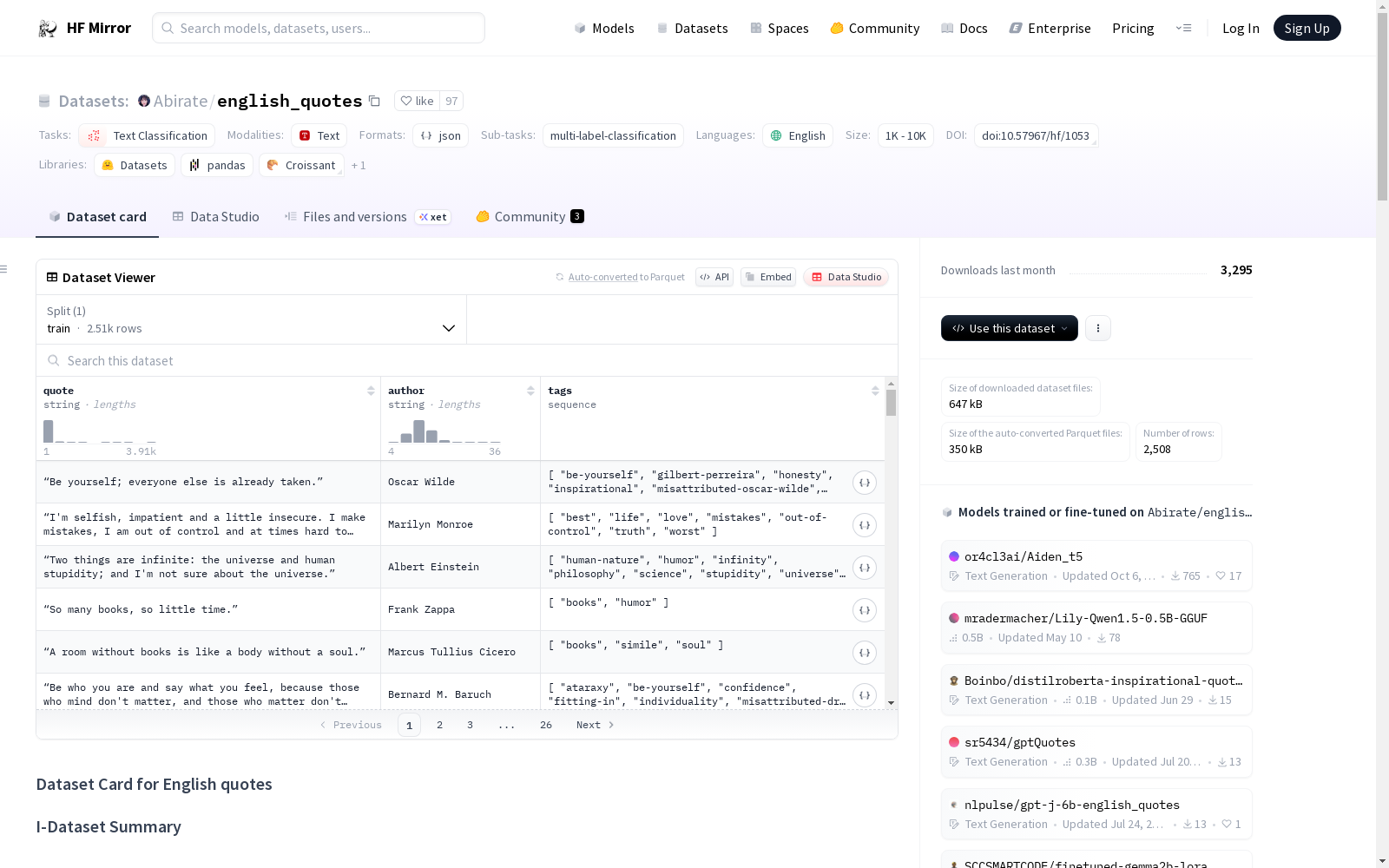
一个典型的数据实例示例(JSON格式): python {author: Ralph Waldo Emerson, quote: “To be yourself in a world that is constantly trying to make you something else is the greatest accomplishment.”, tags: [accomplishment, be-yourself, conformity, individuality]}
数据字段
- author:名言的作者。
- quote:名言的文本内容。
- tags:与名言相关的主题标签。
数据分割
数据集未进行预先分割,用户可使用Hugging Face数据集库的方法(如 .train_test_split())自行分割。
五、数据集创建
数据收集与规范化
数据通过使用BeautifulSoup和Requests库进行网页抓取收集。收集后,移除了所有标签为"None"的名言,并从所有标签中移除了"attributed-no-source",因其对名言主题无增值作用。
数据源
数据源为 goodreads 网站的 goodreads quotes 部分。
数据生产者
数据通过机器生成(使用网页抓取技术)并经过人工额外处理。
六、附加信息
数据集维护者
Abir ELTAIEF
许可证信息
本作品采用Creative Commons Attribution 4.0 International License 许可,所有用于网页抓取的软件和库均在此Creative Commons Attribution许可下提供。
搜集汇总
数据集介绍
构建方式
Abirate/english_quotes数据集的构建基于对Goodreads网站上引言的网页抓取。数据通过使用BeautifulSoup和Requests库进行初步收集,随后经过人工处理以去除无价值标签和无效数据。数据集保持了原始的单块结构,用户可根据需求使用Hugging Face库中的方法进行随机划分。
特点
该数据集以英语为语言,包含来自Goodreads的引言,适用于多标签文本分类和文本生成任务。每条数据包含作者、引言文本及与之相关的标签,反映了引言的主题。数据集的构建旨在推动自然语言处理领域的人工智能发展。
使用方法
用户可以直接利用该数据集进行多标签文本分类训练,或对预训练模型进行微调以生成新的引言。数据集以JSON格式存储,可通过Hugging Face库的相关方法轻松加载和处理。
背景与挑战
背景概述
English quotes数据集源于对Goodreads网站上引语的大规模抓取,该数据集的创建旨在为自然语言处理领域提供丰富的文本资源。由Abir ELTAIEF负责构建并于HuggingFace平台共享,其包含了多位作者的名言及其相关的话题标签,为多标签文本分类和文本生成任务提供了基础。English quotes数据集自推出以来,已成为自然语言处理研究领域的重要资源,对推动人工智能技术的发展起到了积极作用。
当前挑战
该数据集在构建过程中主要面临的挑战包括数据抓取的准确性和效率问题,以及对抓取后数据的清洗和标准化处理。在数据集应用方面,挑战在于如何有效地从中提取和利用引语的多维度信息,以实现精确的多标签分类和高质量的文本生成。此外,数据集的单一语种特性限制了其在多语言环境下的应用范围。
常用场景
经典使用场景
在自然语言处理领域,english_quotes数据集以其丰富的引语内容,成为多标签文本分类和文本生成任务的经典用例。该数据集由来自goodreads的引语构成,涵盖了多样的话题和作者,为研究者提供了一个丰富的资源库,以训练模型识别和分类文本中的多个主题。
解决学术问题
english_quotes数据集解决了学术研究中如何有效进行文本多标签分类的问题,同时,它也提供了研究文本生成和风格模仿的新途径。该数据集的出现,为NLP领域中的情感分析、主题建模以及作者识别等任务提供了重要的数据支撑,极大地推动了相关研究的进展。
衍生相关工作
基于english_quotes数据集,研究者们衍生出了一系列相关工作,包括但不限于文本情感分析、作者风格识别以及引语在社交媒体上的影响力分析等。这些工作不仅拓宽了NLP的应用领域,也为后续的研究提供了宝贵的基准数据集。
以上内容由遇见数据集搜集并总结生成


