Teklia/DAI-CReTDHI-RecordGeneanet-ATR
收藏Hugging Face2026-05-05 更新2026-05-10 收录
下载链接:
https://hf-mirror.com/datasets/Teklia/DAI-CReTDHI-RecordGeneanet-ATR
下载链接
链接失效反馈官方服务:
资源简介:
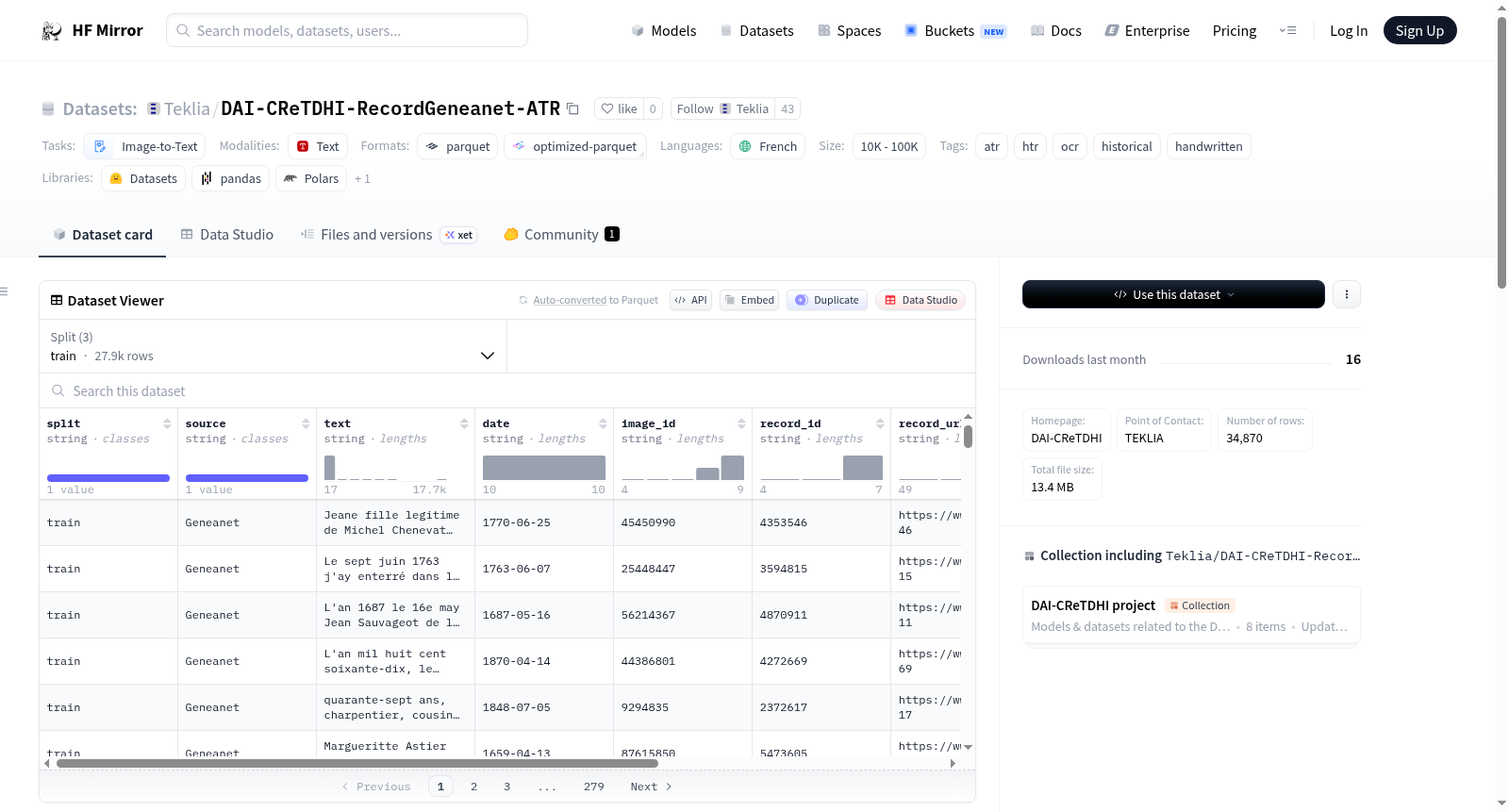
DAI-records-geneanet-ATR数据集包含来自Geneanet的34,870份手写记录,时间跨度为16至19世纪。这些记录由Geneanet用户标注,并用于DAI-CReTDHI研究项目的预训练。数据集中的所有文档均为法语书写。每条记录包含图像和转录文本,具体字段包括分割标识、来源、记录ID、记录URL、日期和转录文本。
The DAI-records-Geneanet-ATR dataset includes 34,870 handwritten records from the XVI-XIXth centuries, sourced from Geneanet. These records have been annotated by Geneanet users and were used for pretraining during the DAI-CReTDHI research project. All documents in the dataset are written in French. Each instance represents a record with its image and transcription, including fields such as split identifier, source, record ID, record URL, date, and transcription text.
提供机构:
Teklia
搜集汇总
数据集介绍
构建方式
DAI-CReTDHI-RecordGeneanet-ATR数据集源自法国知名家谱平台Geneanet,聚焦于16至19世纪的手写教区与民事登记记录。该数据集由Geneanet用户通过众包方式完成转录标注,并在DAI-CReTDHI研究项目中作为预训练数据使用。构建过程中,原始图像被分割为独立的记录级单元,每一条数据均包含对应的图像标识符、转录文本、日期、记录网址以及所属数据集划分标签。数据集共收录34,870条记录,并按照约8:1:1的比例划分为训练集(27,882条)、验证集(3,489条)与测试集(3,499条),确保模型训练与评估的统计有效性。
特点
该数据集最显著的特点在于其历史手写文档的领域专属性——所有记录均为法语书写的古老手写体,时间跨度覆盖三个世纪,真实反映了不同历史时期的书写风格、笔画形态与墨迹退化特征。众包标注机制在保证大规模数据获取的同时,也引入了转录文本的自然变异,提升了模型对多样化笔迹的鲁棒性。每条记录不仅提供转录文字,还附带精确的日期字段与Geneanet平台的可追溯链接,支持细粒度的时序分析与跨源验证。数据集的规模控制在数万级别,兼顾了深度学习训练的计算可行性与领域覆盖的平衡。
使用方法
该数据集适用于历史手写文本识别(HTR/ATR)模型的训练、微调与评估。研究者可直接加载JSON格式的数据实例,以‘text’字段作为标签,‘image_id’字段关联对应的记录图像进行图像到文本的序列建模。由于数据已划分为标准的训练、验证与测试集,用户无需自行分割,可直接用于监督学习流程。此外,‘date’字段可用于按时间窗口筛选子集,实现对特定世纪书写模型的领域适配。推荐使用基于CNN-RNN+CTC或Transformer架构的OCR/HTR框架,并在法语特定语言模型的支持下优化解码性能。
背景与挑战
背景概述
在历史文献数字化与手写文本识别(HTR)领域,缺乏大规模、真实场景下的历史手写记录数据集长期制约着算法模型的泛化能力与实用化进程。DAI-CReTDHI-RecordGeneanet-ATR数据集正是在此背景下应运而生,由法国拉罗谢尔大学DAI-CReTDHI研究项目与Teklia公司合作,依托Geneanet平台于近年构建完成。该数据集聚焦于16至19世纪法国教区与民事登记手写记录,包含34,870条带有用户众包标注的转录文本,覆盖训练、验证与测试三个标准划分。通过提供高保真的历史文档图像与精确的转录对应关系,该数据集为手写文本识别、光学字符识别(OCR)及历史文档分析等任务提供了重要的基准资源,有效填补了法语历史手写语料库的空白,对推动文化遗产数字化与历史人口学研究具有深远影响。
当前挑战
该数据集所解决的领域核心挑战在于历史手写文档的复杂变异性:不同时期、地域与书写者的手写风格差异显著,加之纸张老化、墨迹褪色等物理退化,使得传统OCR或通用HTR模型难以直接胜任。为此,数据集构建过程中面临多重困难:首先,需从Geneanet海量众包标注记录中筛选出高质量、低噪声的转录文本,确保标注的忠实性与一致性;其次,历史法语拼写与现代标准存在差异,需兼顾语言演变与人工校正的平衡;此外,记录级标注需精确匹配图像区域与对应行文本,分割与对齐难度较高。这些挑战共同要求模型具备跨世纪时期、跨书写风格的鲁棒学习能力,同时推动数据清洗与标注流程的标准化,为后续历史文档智能化处理奠定基础。
常用场景
经典使用场景
DAI-CReTDHI-RecordGeneanet-ATR数据集汇聚了来自16至19世纪法国教区与民事登记簿的34,870份手写档案,每一份记录均包含扫描图像及其对应的转录文本。该数据集最为经典的使用场景在于训练与评估面向历史文档的手写文本识别(HTR)与光学字符识别(OCR)模型。研究者可将图像数据作为输入,以转录文字作为监督信号,构建端到端的序列识别系统,从而提升模型对古老手写字体、稠密排版与不均匀墨水分布等复杂特征的辨识能力。
解决学术问题
在学术研究层面,该数据集直击了历史文献数字化过程中的核心瓶颈——即古代手写文本的自动转录精度不足问题。传统OCR引擎在面对花样繁多、布局凌乱的古籍时往往力不从心,而该数据集通过提供大规模、真实场景下的手写记录样本,支撑了基于深度学习的注意力机制、联结主义时间分类(CTC)及Transformer架构在历史文档转录任务中的性能验证与优化。它为跨领域迁移学习提供了宝贵的预训练语料,推动了手写识别技术从现代文本向历史档案的泛化进程。
衍生相关工作
基于该数据集,学界已衍生出若干具有影响力的代表性工作。首先,该数据集被用于DAI-CReTDHI研究项目的模型预训练阶段,为后续多种历史文档分析模型提供了初始权重。其次,研究工作如‘融合上下文信息的序列转录网络’和‘面向历史手写的弱监督对比学习框架’均直接采用本数据集作为基准,考核模型在嘈杂字形与变化布局下的鲁棒性。此外,通过在Transformer解码器中引入行级与文档级上下文,相关方法刷新了多个历史档案数据上的词错误率纪录,形成了完整的方法论体系。
以上内容由遇见数据集搜集并总结生成


