GMAI-MMBench
收藏arXiv2024-08-07 更新2024-08-09 收录
下载链接:
http://arxiv.org/abs/2408.03361v1
下载链接
链接失效反馈官方服务:
资源简介:
GMAI-MMBench是由上海人工智能实验室等机构创建的一个综合性的多模态评估基准,专门用于测试大型视觉语言模型在真实临床场景中的能力。该数据集包含了来自全球的285个多样化的临床相关数据集,覆盖39种模态,涉及18个临床VQA任务和18个临床部门。数据集的创建过程包括从公共和医院来源收集数据,标准化图像和标签,以及构建一个词法树结构以方便用户定制评估任务。GMAI-MMBench旨在解决医学领域中大型视觉语言模型的评估问题,特别是在诊断和治疗方面的应用。
GMAI-MMBench is a comprehensive multimodal evaluation benchmark developed by institutions including the Shanghai AI Laboratory, which is specifically designed to test the capabilities of large vision-language models in real-world clinical scenarios. This benchmark encompasses 285 diverse clinical-related datasets from across the globe, covering 39 modalities, and involving 18 clinical VQA tasks and 18 clinical departments. The development process of this benchmark includes collecting data from public and hospital sources, standardizing images and labels, and constructing a lexical tree structure to facilitate users in customizing evaluation tasks. GMAI-MMBench aims to address the evaluation challenges of large vision-language models in the medical field, particularly their applications in diagnosis and treatment.
提供机构:
上海人工智能实验室
创建时间:
2024-08-07
搜集汇总
数据集介绍
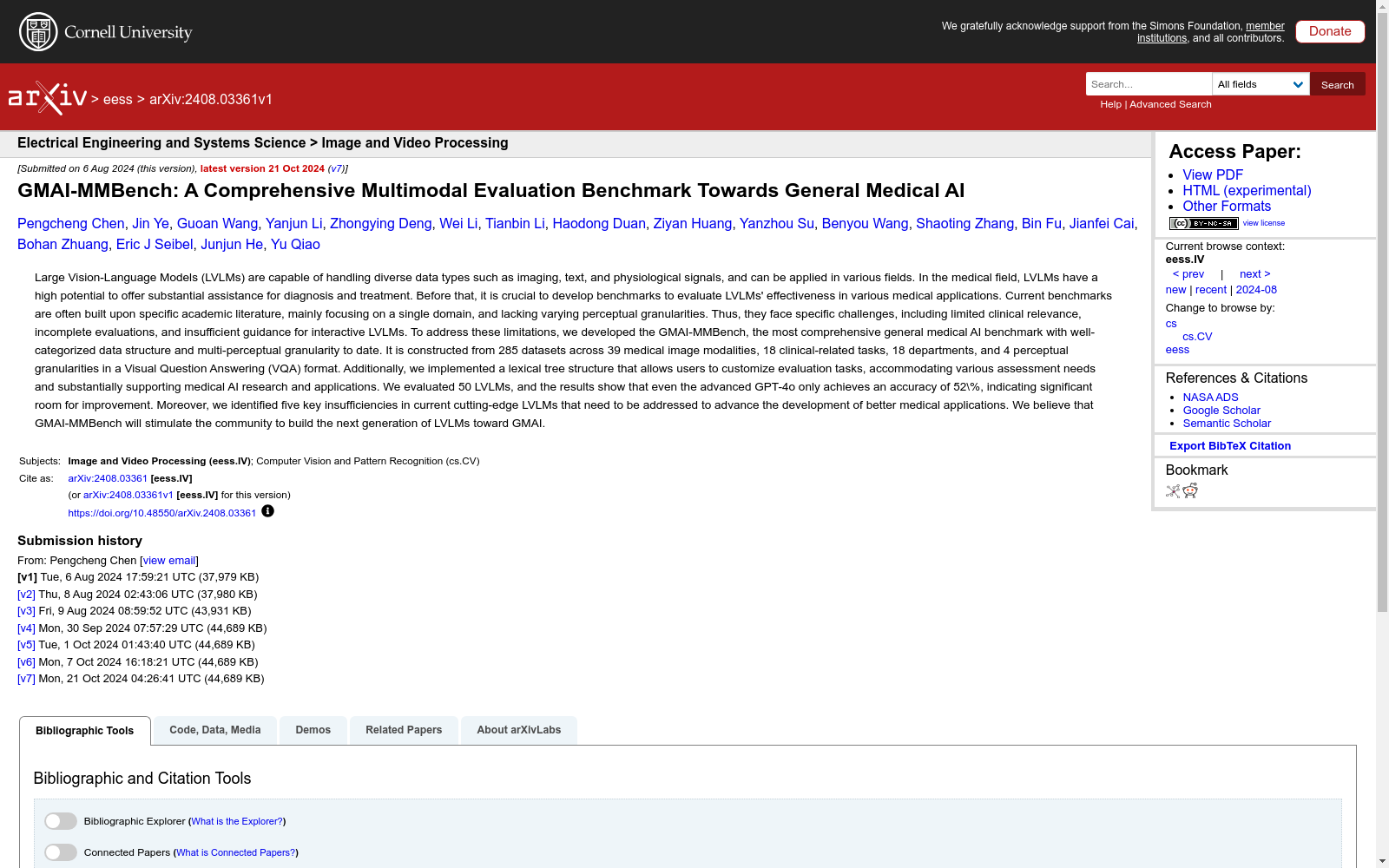
构建方式
GMAI-MMBench 数据集的构建过程涉及三个主要步骤:数据收集和标准化、标签分类和词汇树构建、问答生成和选择。首先,数据集从全球范围内的公共来源和医院收集了 285 个高质量的数据集,涵盖检测、分类和分割等医疗成像任务。其次,数据点被分类到 18 个临床 VQA 任务、18 个临床部门和 4 种不同的感知粒度中,并导出词汇树以方便定制评估。最后,为每个标签生成问答对,并进行人工验证和选择,以确保数据质量和平衡分布。
使用方法
GMAI-MMBench 数据集的使用方法包括三个步骤:首先,根据用户的需求,选择需要测试的数据。其次,使用关键词过滤相关的问题。最后,使用过滤后的问题列表评估不同的模型,并将结果编译和显示在表格中。
背景与挑战
背景概述
随着大型视觉语言模型(LVLMs)在处理图像、文本和生理信号等多种数据类型方面的能力日益增强,其在医疗领域的应用潜力也日益凸显。为了评估LVLMs在医疗应用中的有效性,研究人员迫切需要建立一个全面的多模态评估基准。然而,现有的基准往往基于特定的学术文献,主要关注单一领域,并且缺乏不同的感知粒度。因此,它们面临着临床相关性有限、评估不完整以及缺乏对交互式LVLMs的足够指导等挑战。为了解决这些局限性,研究人员开发了一个名为GMAI-MMBench的基准,这是迄今为止最全面的一般医疗人工智能基准,具有分类良好的数据结构和多感知粒度。它由来自全球的285个数据集构建而成,涵盖39种医学图像模态,18个临床相关任务,18个部门和4种感知粒度,并以视觉问答(VQA)格式组织。此外,研究人员还实现了一个词汇树结构,使用户能够自定义评估任务,以满足各种评估需求,并极大地支持医疗人工智能研究和应用。
当前挑战
尽管GMAI-MMBench为评估LVLMs的能力提供了一个全面的框架,但它在临床实践中仍然面临着重大挑战。即使是最先进的模型GPT-4o也只能达到约52%的准确率,这远未达到临床要求,表明当前医疗领域的所有LVLMs都需要进行重大改进。此外,开源模型在性能上正在逐渐赶超商业模型,但它们仍然存在明显的差距。大多数LVLMs在感知不同粒度时表现不佳,尤其是在交互式应用中。此外,大多数LVLMs在多项选择题上的性能也需要改进。最后,医疗专用模型需要增强其指令调优能力。这些挑战表明,尽管GMAI-MMBench为LVLMs在医疗领域的应用提供了宝贵的评估框架,但它也面临着一些局限性,需要进一步完善和发展。未来,研究人员需要开发更全面、更定制化的基准,以更好地满足临床需求,并推动LVLMs在医疗领域的发展。
常用场景
经典使用场景
GMAI-MMBench数据集作为通用医疗人工智能领域内最全面的评估基准,其设计旨在测试大型视觉语言模型(LVLMs)在实际临床场景中的能力。它包含了来自世界各地的285个多样化的临床相关数据集,涵盖了39种模态。该数据集的特点在于其全面性、良好的分类数据结构和多感知粒度。它以视觉问答(VQA)格式构建,涵盖了18个临床VQA任务和18个临床部门,并提供了从图像到区域级别的交互式方法,以提供不同程度的感知细节。
解决学术问题
GMAI-MMBench解决了现有基准在临床相关性、评估完整性以及对交互式LVLMs的指导不足等挑战。它通过提供多样化的医疗数据、任务和模态,以及精细分类的词汇树结构,为医疗人工智能研究和应用提供了强大的支持。此外,该数据集还揭示了当前先进LVLMs在处理医疗专业问题时存在的不足,为模型的改进和优化提供了重要指导。
实际应用
GMAI-MMBench的实际应用场景包括但不限于医学影像分析、疾病诊断、治疗流程识别等领域。它可以用于评估LVLMs在不同临床场景下的性能,为医疗专业人员提供决策支持。例如,通过分析X射线、CT、MRI等影像数据,LVLMs可以辅助医生进行疾病诊断和严重程度分级。此外,GMAI-MMBench还可以用于开发交互式LVLMs,以提高医生与人工智能系统的交互效率。
数据集最近研究
最新研究方向
GMAI-MMBench, a comprehensive multimodal evaluation benchmark for General Medical AI, has been developed to address the limitations of current benchmarks. It incorporates diverse medical data from various sources, including 285 datasets across 39 medical image modalities, 18 clinical tasks, 18 departments, and 4 perceptual granularities. The benchmark's well-categorized structure, facilitated by a lexical tree, allows for customized evaluation tasks, supporting medical AI research and applications. GMAI-MMBench evaluates LVLMs' performance in real-world clinical scenarios, highlighting their insufficiencies in medical knowledge, task diversity, and interactive capabilities. The results indicate that LVLMs, even advanced models like GPT-4o, have significant room for improvement to meet clinical demands. The benchmark identifies key areas for LVLM development, including enhancing medical domain knowledge, improving instruction tuning, and addressing performance disparities across different clinical tasks and departments. GMAI-MMBench aims to stimulate the community to build the next generation of LVLMs towards General Medical AI, fostering advancements in medical AI research and applications.
相关研究论文
- 1GMAI-MMBench: A Comprehensive Multimodal Evaluation Benchmark Towards General Medical AI上海人工智能实验室 · 2024年
以上内容由遇见数据集搜集并总结生成


