vcr-org/VCR-wiki-en-easy
收藏Hugging Face2024-07-28 更新2024-06-12 收录
下载链接:
https://hf-mirror.com/datasets/vcr-org/VCR-wiki-en-easy
下载链接
链接失效反馈官方服务:
资源简介:
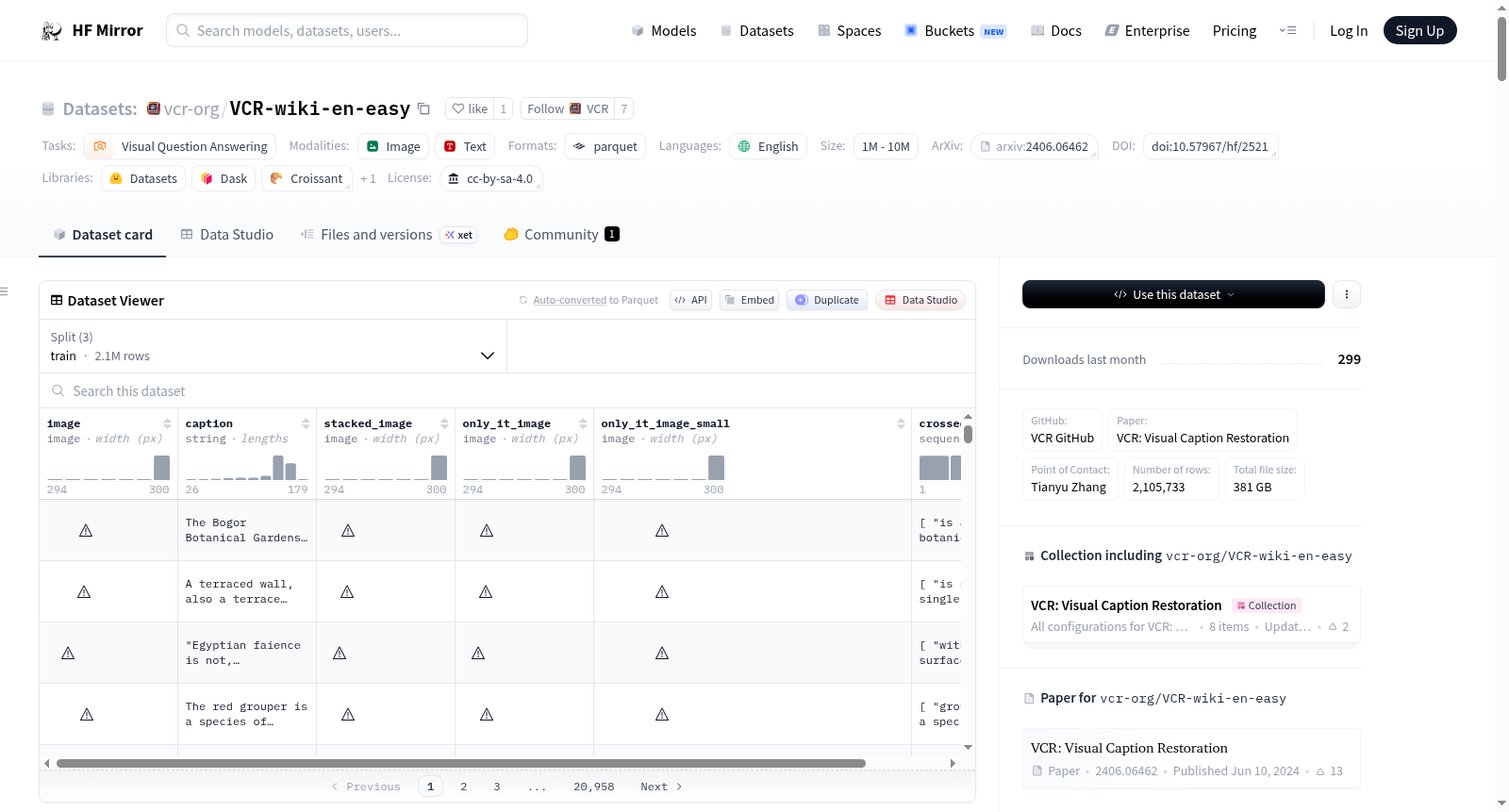
VCR-Wiki数据集是一个用于视觉字幕恢复(VCR)任务的数据集,旨在评估视觉语言模型在部分遮挡文本恢复中的能力。数据集包含图像、字幕、堆叠图像等字段,并通过调整字幕可见性来控制任务难度。数据集构建过程包括数据收集、过滤、N-gram选择、文本嵌入图像生成等步骤。数据集分为训练集、验证集和测试集,分别包含2095733、5000和5000个样本。数据集的总大小为382374912324.19275字节,下载大小为380674831567字节。数据集基于wikimedia/wit_base数据集构建,任务类别为视觉问答,语言为英语。
VCR-Wiki数据集是一个用于视觉字幕恢复(VCR)任务的数据集,旨在评估视觉语言模型在部分遮挡文本恢复中的能力。数据集包含图像、字幕、堆叠图像等字段,并通过调整字幕可见性来控制任务难度。数据集构建过程包括数据收集、过滤、N-gram选择、文本嵌入图像生成等步骤。数据集分为训练集、验证集和测试集,分别包含2095733、5000和5000个样本。数据集的总大小为382374912324.19275字节,下载大小为380674831567字节。数据集基于wikimedia/wit_base数据集构建,任务类别为视觉问答,语言为英语。
提供机构:
vcr-org
原始信息汇总
数据集概述
数据集特征
- image:图像数据类型
- caption:字符串数据类型
- stacked_image:图像数据类型
- only_it_image:图像数据类型
- only_it_image_small:图像数据类型
- crossed_text:字符串序列数据类型
数据集分割
- test:包含5000个样本,总大小为906218066.4872956字节
- validation:包含5000个样本,总大小为907941880.8999181字节
- train:包含2095733个样本,总大小为380560752376.80554字节
数据集大小
- 下载大小:380674831567字节
- 数据集总大小:382374912324.19275字节
数据文件配置
- config_name: default
- test:路径为
data/test-* - validation:路径为
data/validation-* - train:路径为
data/train-*
- test:路径为
搜集汇总
数据集介绍
构建方式
在视觉语言模型评估领域,VCR-Wiki数据集通过一套严谨的流程构建而成。其基础数据源自wikimedia/wit_base,首先经过内容过滤,移除了涉及敏感主题的条目。随后,对图像描述文本进行截断与分词处理,并随机选取不包含特定实体类别的5-gram序列进行掩码。核心步骤在于创建文本嵌入图像,将掩码后的描述文本以图像形式呈现,并通过调整掩码矩形的大小来控制任务难度,形成“简单”与“困难”两种版本。最终,将文本嵌入图像与原始视觉图像拼接,生成堆叠图像,并经过二次筛选以确保数据质量与格式规范。
特点
该数据集专为视觉字幕恢复任务设计,其核心特征在于评估模型整合像素级视觉线索与上下文信息以还原被遮蔽文本的能力。数据集包含超过两百万个训练实例,提供了原始图像、堆叠图像、纯文本图像及完整字幕等多种模态数据。尤为关键的是,它通过精确控制掩码区域的可视程度,构建了不同难度的评估子集,使得传统OCR技术在此任务上几乎失效,从而能够深入检验视觉语言模型对细微视觉线索的理解与推理水平。
使用方法
该数据集主要用于基准测试,评估视觉语言模型在视觉字幕恢复任务上的性能。研究人员可通过官方提供的评估脚本,利用Hugging Face集成的开源模型标识符进行自动化评估,支持在本地或分布式GPU环境下运行。对于闭源模型,则提供了基于API的评估流程。此外,数据集亦兼容VLMEvalKit和lmms-eval两大主流评估框架,用户可根据模型支持情况选择相应框架,通过指定任务名称(如`vcr_wiki_en_easy`)便捷地开展实验,并获取精确匹配度与杰卡德相似度等量化指标。
背景与挑战
背景概述
视觉字幕恢复(VCR)任务旨在评估视觉语言模型利用图像内像素级线索准确还原部分遮蔽文本的能力。VCR-Wiki数据集由Tianyu Zhang等研究人员于2024年构建,其核心研究问题聚焦于模型如何整合图像内容、上下文信息以及被遮蔽文本微小暴露区域的细微线索,以完成精确的文本复原。该数据集基于wikimedia/wit_base构建,通过合成图像生成流程,创建了包含不同难度级别的实例,为视觉语言理解领域提供了新的基准测试平台,推动了模型在复杂多模态推理任务上的性能评估与改进。
当前挑战
VCR任务所解决的核心领域挑战在于,传统OCR与纯文本处理方法在此类任务中失效,模型必须深度融合视觉与语言模态,从极有限的像素暴露区域推断完整文本内容,这对模型的细粒度感知与上下文推理能力提出了极高要求。在数据集构建过程中,面临的挑战包括:如何设计合理的文本遮蔽策略以平衡任务难度,确保任务对人类母语者可行但对模型构成挑战;如何过滤原始数据中的敏感内容以降低伦理风险;以及如何生成高质量、多样化的合成图像,保证数据集的真实性与评估有效性。
常用场景
经典使用场景
在视觉语言模型评估领域,VCR-Wiki数据集为视觉字幕恢复任务提供了标准化的测试平台。该数据集通过合成图像与部分遮蔽文本的组合,要求模型综合利用图像内容、上下文语义以及像素级视觉线索,准确还原被遮蔽的文字信息。这种设计使得数据集成为衡量模型跨模态理解与推理能力的经典工具,尤其适用于评估模型在传统OCR失效场景下的视觉文本解析性能。
解决学术问题
该数据集有效解决了视觉语言模型评估中细粒度跨模态理解能力量化不足的学术难题。传统评估方法往往依赖完整的文本信息,而VCR通过引入像素级遮蔽机制,迫使模型必须深度融合视觉与语言表征才能完成任务。这种设计揭示了模型在处理微观视觉线索与宏观语义关联时的能力边界,为理解多模态融合机制提供了新的研究视角,推动了视觉语言理解理论框架的完善。
衍生相关工作
围绕该数据集衍生的经典工作主要集中于多模态模型架构创新与评估方法拓展。研究团队基于VCR提出的评估框架已被整合进VLMEvalKit和lmms-eval等主流评测体系,形成了标准化的模型能力对比基准。同时,该数据集启发了对视觉语言模型细粒度理解机制的理论探索,催生了针对像素级视觉语言对齐、跨模态注意力机制优化等一系列相关研究,推动了领域向更精细的评估维度发展。
以上内容由遇见数据集搜集并总结生成


