有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
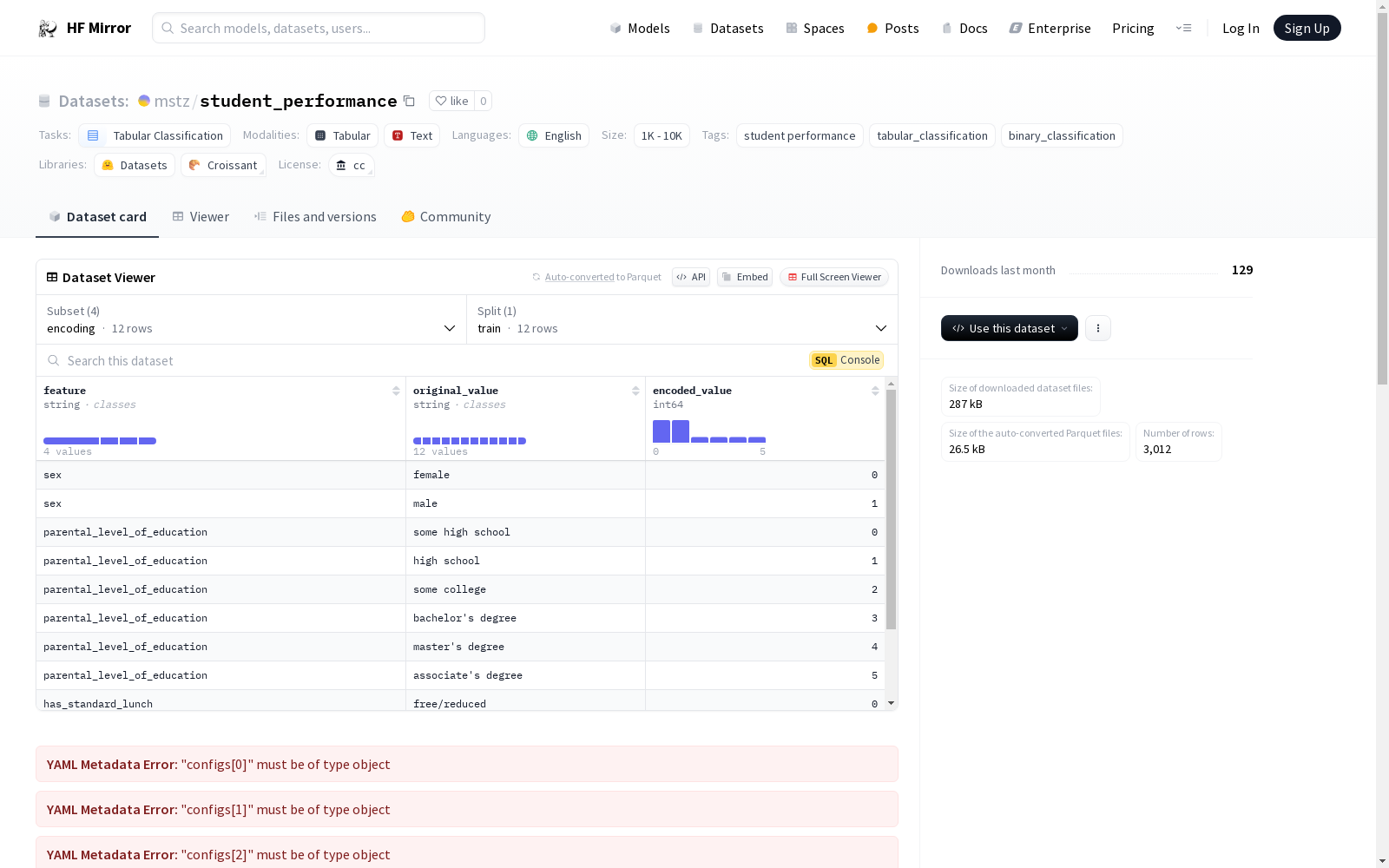
| 配置 | 任务 | 描述 |
|---|---|---|
| encoding | 编码字典,显示编码特征的原始值。 | |
| math | Binary classification | 学生是否通过了数学考试? |
| writing | Binary classification | 学生是否通过了写作考试? |
| reading | Binary classification | 学生是否通过了阅读考试? |
| 特征 | 类型 |
|---|---|
is_male |
bool |
ethnicity |
string |
parental_level_of_education |
int8 |
has_standard_lunch |
bool |
has_completed_preparation_test |
bool |
reading_score |
int64 |
writing_score |
int64 |
math_score |
int64 |
LFW
人脸数据集;LFW数据集共有13233张人脸图像,每张图像均给出对应的人名,共有5749人,且绝大部分人仅有一张图片。每张图片的尺寸为250X250,绝大部分为彩色图像,但也存在少许黑白人脸图片。 URL: http://vis-www.cs.umass.edu/lfw/index.html#download
AI_Studio 收录
Materials Project
材料项目是一组标有不同属性的化合物。数据集链接: MP 2018.6.1(69,239 个材料) MP 2019.4.1(133,420 个材料)
OpenDataLab 收录
UAVDT
UAVDT是一个用于目标检测任务的数据集。
github 收录
Beijing Traffic
The Beijing Traffic Dataset collects traffic speeds at 5-minute granularity for 3126 roadway segments in Beijing between 2022/05/12 and 2022/07/25.
Papers with Code 收录
Eurovision Song Contest Dataset
Eurovision Song Contest数据集是一个免费提供的数据集,包含1735首参赛歌曲的音频特征、元数据、比赛排名和投票数据,这些歌曲参与了从1956年到2023年的Eurovision Song Contest。
github 收录