Objaverse++
收藏github2025-04-09 更新2025-04-10 收录
下载链接:
https://github.com/TCXX/ObjaversePlusPlus
下载链接
链接失效反馈官方服务:
资源简介:
Objaverse++ 是一个标注了3D建模对象质量分数和其他重要特性的数据集,专为机器学习研究者设计。我们精心筛选了一系列Objaverse对象,并开发了一个有效的分类器,能够对整个Objaverse进行评分。我们广泛的注释系统考虑了几何结构和纹理信息,使研究者能够根据特定需求筛选训练数据。
Objaverse++ is a dataset annotated with quality scores and other critical attributes of 3D modeling objects, specifically tailored for machine learning researchers. We carefully curated a subset of Objaverse objects and developed an effective classifier capable of scoring the entire Objaverse dataset. Our comprehensive annotation system incorporates both geometric structure and texture information, enabling researchers to filter training data based on their specific requirements.
创建时间:
2025-04-08
原始信息汇总
Objaverse++ 数据集概述
数据集简介
- 名称: Objaverse++
- 类型: 带有质量标注的3D对象数据集
- 目的: 为机器学习研究者提供带有质量评分和重要特征的3D建模对象标注
数据集特点
-
数据规模:
- 手动标注10,000个3D对象
- 通过神经网络标注整个Objaverse数据集
- 精选约500,000个高质量3D模型
-
质量评分:
- 低质量: 无语义意义或损坏的对象
- 中等质量: 可识别但缺少基本材质纹理和颜色信息的对象
- 高质量: 具有清晰对象身份和适当纹理的对象
- 优质: 具有高语义清晰度和专业纹理的对象
-
二元特征:
- 透明度
- 场景
- 单色
- 非单一对象
- 人物形象
-
实验性特征:
- 艺术风格: 扫描、街机、科幻、卡通、动漫、写实、其他
- 密度: 不同级别的多边形计数
数据集评估
- 评估任务: 图像到3D生成
- 比较对象:
- 随机采样的100,000个Objaverse对象
- 约50,000个高质量对象
- 关键发现:
- 生成质量更好
- 训练收敛更快
使用信息
- 下载地址: https://huggingface.co/datasets/cindyxl/ObjaversePlusPlus
- 许可证: Open Data Commons Attribution License (ODC-By) v1.0
引用信息
bibtex @misc{lin2025objaversecurated3dobject, title={Objaverse++: Curated 3D Object Dataset with Quality Annotations}, author={Chendi Lin and Heshan Liu and Qunshu Lin and Zachary Bright and Shitao Tang and Yihui He and Minghao Liu and Ling Zhu and Cindy Le}, year={2025}, eprint={2504.07334}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2504.07334}, }
致谢
- Exascale Labs
- Zillion Network
- Abaka AI
- Ang Cao和Liam Fang
搜集汇总
数据集介绍
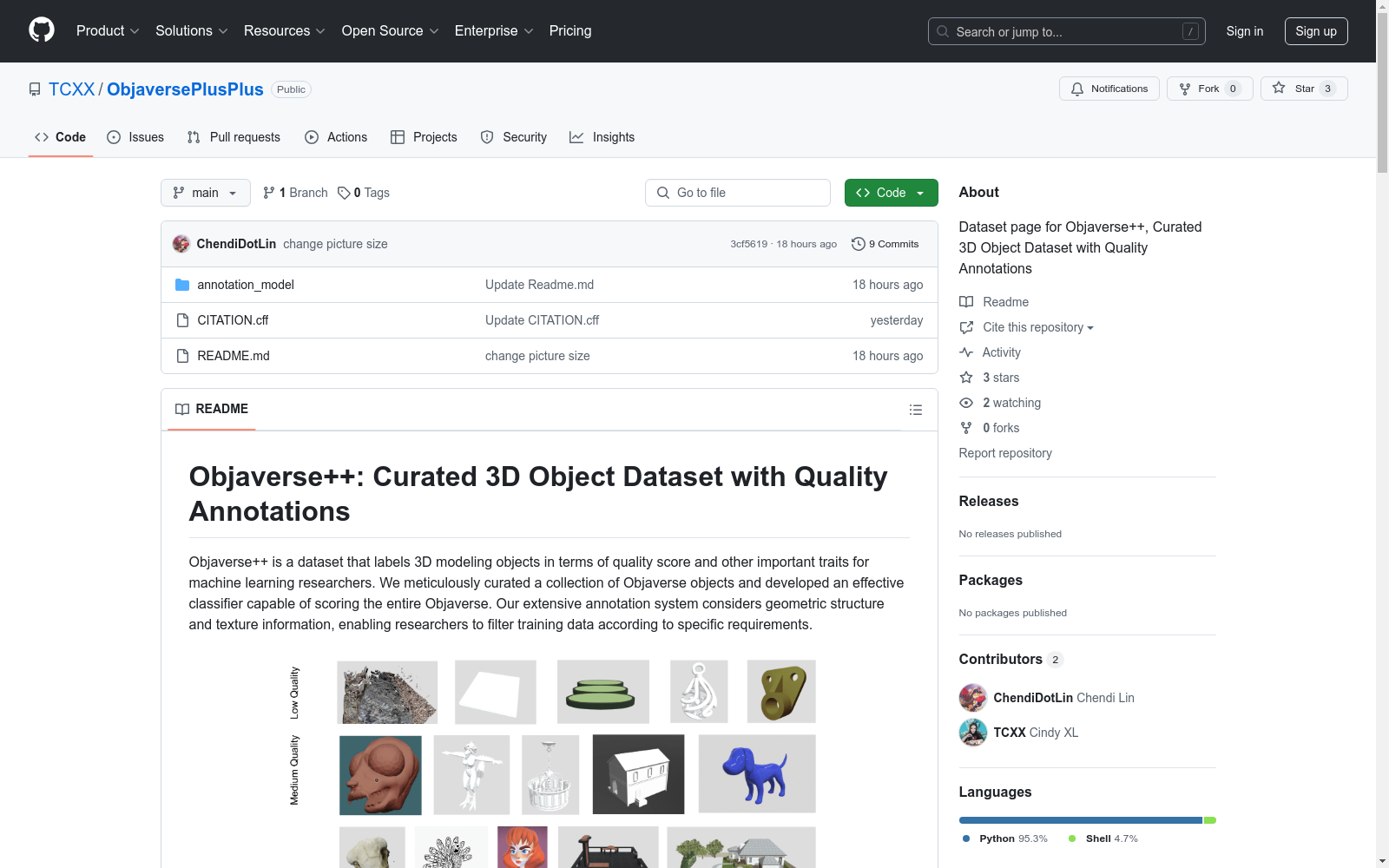
构建方式
在三维模型数据质量参差不齐的背景下,Objaverse++通过多阶段流程构建了标注精细的数据集。研究团队首先对1万个三维对象进行了人工标注,涵盖质量评分和特征属性;随后训练神经网络模型对完整Objaverse数据集进行自动化标注;最终精选出约50万个高质量三维模型构成核心数据集。整个构建过程特别注重几何结构和纹理信息的系统性评估,建立了四级质量评分体系和五大二元特征标签体系。
特点
Objaverse++最显著的特点在于其精细的质量评估体系。数据集采用四级质量评分标准,从低质量到卓越质量进行严格分级,每个等级都明确定义了语义清晰度、纹理细节等评估维度。同时创新性地引入了透明度、场景构成、单色性、多组件和人物特征五大二元标签,为机器学习任务提供了多维度的筛选条件。实验证明,该数据集在保持规模优势的同时,其质量过滤机制能显著提升生成式AI任务的性能表现。
使用方法
该数据集可通过Hugging Face平台直接获取,研究者可根据需求灵活运用其标注体系。对于生成式任务,建议优先选用高质量(High Quality)和卓越质量(Superior Quality)子集;特定任务可利用二元标签进行针对性筛选,如透明材质研究可筛选Transparency标签。数据集支持端到端的训练流程优化,在图像到三维生成等任务中,使用精选子集可同时提升生成质量和训练效率。
背景与挑战
背景概述
Objaverse++是由Exascale Labs和Zillion Network支持的高质量3D对象数据集,专注于为机器学习研究提供精确的质量标注。该数据集于2025年由匿名研究团队在CVPR上首次发布,旨在解决原始Objaverse数据集中普遍存在的低质量3D模型问题。通过人工标注10,000个3D对象并训练神经网络扩展标注范围,研究团队构建了包含约50万个高质量模型的精选子集。这一创新性工作显著提升了生成式AI任务(如文本到3D和图像到3D)的性能和效率,为计算机视觉和图形学领域提供了重要的基准资源。
当前挑战
Objaverse++主要应对3D模型质量评估与筛选的双重挑战。在领域问题层面,原始3D数据集普遍存在模型质量参差不齐的问题,导致生成式AI任务效果受限。该数据集通过建立几何结构和纹理信息的综合评估体系,解决了质量量化标准缺失的难题。在构建过程中,研究团队面临大规模3D模型标注的复杂性挑战,包括定义多级质量评分标准(从低质量到卓越质量)以及开发自动化标注系统。此外,保持标注一致性、处理模型语义模糊性以及平衡数据集多样性等子问题,都需要精细的设计与验证。
常用场景
经典使用场景
在三维生成式人工智能领域,Objaverse++数据集因其精细的质量标注系统而成为筛选高质量三维模型的黄金标准。该数据集通过几何结构与纹理信息的双重评估体系,为文本到三维、图像到三维等生成任务提供了经过预筛选的训练样本。研究人员可依据质量评分层级(从低质量到卓越质量)快速构建特定需求的数据子集,显著提升了生成模型的输出保真度。
数据集最近研究
最新研究方向
在三维生成式人工智能领域,高质量数据集的构建正成为突破性能瓶颈的关键路径。Objaverse++通过引入几何结构与纹理信息的双重质量评估体系,为文本到三维、图像到三维等生成任务提供了新的研究范式。该数据集创新的分层标注系统不仅包含精细的质量评分,还涵盖透明度、场景构成等二元特征标签,使得研究者能够精准控制训练数据的语义密度。近期实验表明,基于50万精选模型的训练集在OpenLRM框架下实现了生成质量与收敛速度的双重提升,这一发现正在推动三维生成领域从规模优先向质量优先的研究范式转变。
以上内容由遇见数据集搜集并总结生成


