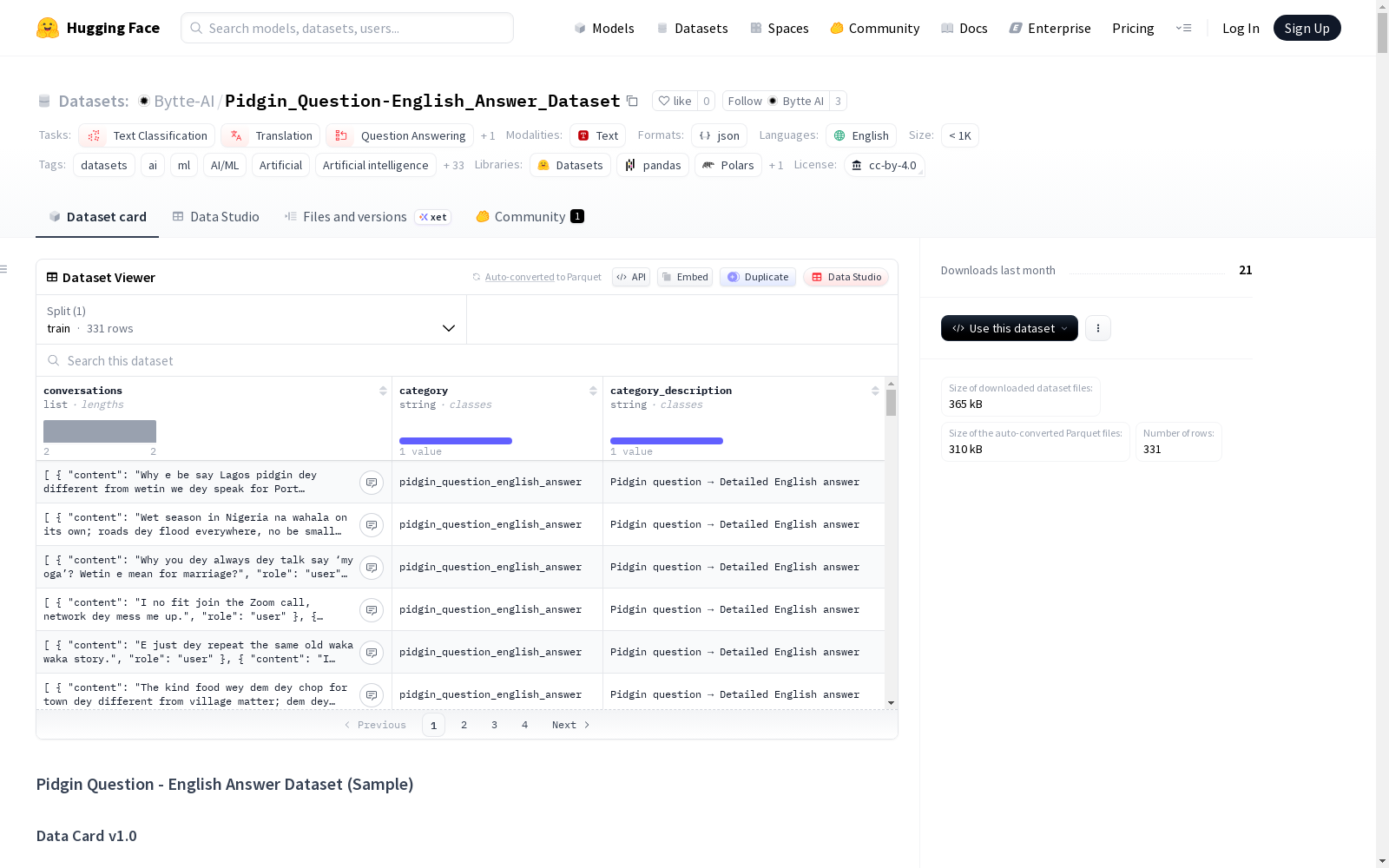
Pidgin Question - English Answer Dataset (Sample) 数据集概述
数据集基本信息
- 数据集名称:Pidgin Question - English Answer Dataset (Sample)
- 数据集类型:样本数据集
- 版本:1.0
- 发布日期:2026
- 组织:Bytte AI
- 许可证:CC-BY-4.0
- 联系人:contact@bytteai.xyz
- 网站:https://www.bytte.xyz/
数据集描述
这是一个包含331个跨语言问答对的样本数据集,其中问题为尼日利亚皮钦英语,答案为标准英语。数据通过AI聊天机器人交互生成并经过人工验证,旨在支持跨语言对话系统、多语言问答以及理解皮钦查询并给出英语回答的应用。
关键统计信息
| 指标 |
值 |
| 总问答对 |
331 |
| 问题语言 |
尼日利亚皮钦英语 |
| 答案语言 |
标准英语 |
| 格式 |
对话式JSON(用户/助手对) |
| 平均问题长度 |
13.64个单词(72个字符) |
| 平均答案长度 |
122.47个单词(824个字符) |
| 回答扩展比率 |
9.51倍(英语答案长度约为皮钦问题的9.5倍) |
| 领域 |
跨语言问答、语言教育、解释性内容 |
| 皮钦语真实性 |
97.6%(包含特征性皮钦标记的问题占比) |
数据集构成
跨语言问答对
- 格式:皮钦问题与详细的英语回答
- 问题复杂度:简单到中等(皮钦语5-31个单词)
- 回答类型:主要为英语的解释性和指导性内容
- 领域覆盖:语言问题、文化话题、日常场景、技术建议
回答类型分布
| 回答类型 |
数量 |
百分比 |
描述 |
| 元语言学 |
163 |
49.2% |
关于皮钦语言、语法、用法的解释 |
| 对话式 |
80 |
24.2% |
对皮钦问题的直接英语回答 |
| 指导性 |
59 |
17.8% |
建议、指导、操作步骤类回答 |
| 解释性 |
29 |
8.8% |
详细的上下文解释 |
| 总计 |
331 |
100% |
所有跨语言对 |
问题起始词样本分布
| 问题起始词 |
数量 |
百分比 |
示例 |
| "how" |
37 |
11.2% |
"How Lagos pidgin dey different..." |
| "I" (陈述) |
34 |
10.3% |
"I no fit join..." |
| "wetin" (什么) |
20 |
6.0% |
"Wetin be di best..." |
| "why" |
19 |
5.7% |
"Why e be say..." |
| "dem" (他们) |
15 |
4.5% |
"Dem say..." |
| "abeg" (请) |
14 |
4.2% |
"Abeg, help me..." |
| 其他 |
192 |
58.0% |
各种模式 |
皮钦问题中的语言特征
| 特征 |
出现次数 |
问题占比 |
功能 |
| dey |
214 |
64.7% |
进行体标记 ("is/are -ing") |
| no |
75 |
22.7% |
否定 ("not", "dont") |
| go |
65 |
19.6% |
将来标记或移动 |
| fit |
65 |
19.6% |
情态动词 ("can", "able to") |
| make |
43 |
13.0% |
虚拟语气 ("let", "should") |
| wetin |
40 |
12.1% |
疑问词 ("what") |
| na |
35 |
10.6% |
系词/焦点标记 ("is") |
| don |
30 |
9.1% |
完成体标记 ("have/has") |
| wey |
23 |
6.9% |
关系代词 ("that") |
| am |
20 |
6.0% |
宾语代词 ("him/her/it") |
数据收集与创建
来源
数据集包含通过AI聊天机器人对话交互创建的跨语言问答对,代表:
- 关于语言、文化和日常话题的皮钦问题
- 通过AI交互生成的英语解释性回答
- 语言学习和跨文化交流场景
- 皮钦语的技术和指导性查询及英语指导
创建方法
- 方法:通过AI聊天机器人交互生成跨语言问答格式(皮钦语→英语)
- 结构:包含用户/助手对话对的JSON对象
- 回答生成:通过AI为皮钦查询生成详细的英语解释
- 质量控制:对AI生成内容进行人工审查和验证
数据格式
文件结构
- 文件名:
pidgin_question_english_answer.json
- 大小:约270 KB(估计)
- 格式:对话对象JSON数组
模式
json
[
{
"conversations": [
{
"role": "user",
"content": "Why e be say Lagos pidgin dey different from wetin we dey speak for Port Harcourt?"
},
{
"role": "assistant",
"content": "The difference between Lagos Pidgin and the Pidgin spoken in Port Harcourt can be attributed to several factors: 1. Regional Influences..."
}
],
"category": "pidgin_question_english_answer",
"category_description": "Pidgin question → English answer"
}
]
字段定义
| 字段 |
类型 |
描述 |
conversations |
数组 |
对话轮次列表(始终为2项) |
conversations[0].role |
字符串 |
始终为"user"(皮钦问题) |
conversations[0].content |
字符串 |
尼日利亚皮钦语问题 |
conversations[1].role |
字符串 |
始终为"assistant"(英语答案) |
conversations[1].content |
字符串 |
详细的英语回答 |
category |
字符串 |
始终为"pidgin_question_english_answer" |
category_description |
字符串 |
任务描述 |
质量指标
- 数据集规模:总跨语言问答对331个;平均皮钦问题长度13.64个单词;平均英语答案长度122.47个单词。
- 回答长度方差:回答与问题长度比的平均值为9.51倍,中位数为7.30倍,范围为1.50倍至34.00倍,方差为41.41。
- 皮钦语真实性:97.6%的问题包含真实的皮钦语法标记。
- 回答类型多样性:元语言学回答占49.2%,对话式回答占24.2%,指导性回答占17.8%,解释性回答占8.8%。
- 平均每项标签数:每个问题仅有一个英语答案,得分为1.0。
- 跨语言一致性:问题97.6%为真实皮钦语,答案100%为标准英语,格式保持一致的跨语言配对。
预期用途
主要用例
- 跨语言对话系统:构建理解皮钦查询并用英语回答的聊天机器人;支持多语言客户服务;开发语言桥接应用;实现跨语言障碍的交流。
- 多语言问答:训练跨语言问答模型;开发皮钦查询理解系统;支持跨语言信息检索;为西非用户启用教育平台。
- 语言学习与教育:创建带有英语解释的皮钦学习工具;开发语法和用法指南;支持语言标准化工作;构建元语言意识资源。
- 翻译与本地化:训练解释式翻译模型;开发上下文感知的翻译系统;支持文化本地化;实现细致的跨文化交流。
- 研究应用:研究跨语言信息传递;分析皮钦语-英语语码转换模式;调查元语言学话语;探索低资源语言的问答。
推荐应用
- 微调多语言模型(如mBERT, XLM-R)用于跨语言问答。
- 训练皮钦查询理解系统。
- 为语言学习者开发教育聊天机器人。
- 跨语言信息检索。
- 语言记录和标准化。
- 文化桥梁构建应用。
超出范围的使用
- 同语言对话(应使用皮钦-皮钦或英语-英语数据集)。
- 无需解释的翻译(回答是解释性的,而非直接翻译)。
- 未经验证的实时生产系统(存在高元语言学偏见)。
- 从头开始训练通用模型(此为样本数据集,需与更大语料库结合)。
- 需要简洁回答的应用(答案平均122个单词)。
局限性与风险
数据集局限性
- 样本数据集 - 规模有限:仅包含331对,不足以从头训练大型跨语言模型,最适合微调和专门应用。
- 高元语言学偏见(49.2%):163个回答解释皮钦语言本身而非直接回答问题,可能导致模型学习生成语言解释而非直接答案。
- 回答长度不平衡:问题与答案长度差异极大(平均扩展9.51倍,最高达34倍),可能导致生成过于冗长的英语回答。
- 跨语言格式特异性:数据集仅为皮钦问题→英语答案单向,不支持训练英语问题→皮钦答案模型。
- 回答过长(19.3%):64个回答超过200个单词,部分达350个单词,可能超出典型对话轮次长度。
- 教育/指导性偏见(17.8%):59个回答提供建议/指导而非直接答案,可能导致模型默认给出指令。
- 领域限制:主要覆盖语言、文化和日常场景,缺少专业领域(医疗、法律、技术、商业)。
- 单一参考答案:每个问题仅有一个英语答案,无法衡量答案多样性。
潜在风险
- 元语言学偏见的延续:在此数据上训练的模型可能默认解释语言而非自然回答。
- 生产系统中的冗长性:9.51倍的平均扩展比可能导致模型生成过长的回答。
- 有限的跨语言泛化能力:数据集可能无法代表所有皮钦语-英语跨语言场景。
- 教育风格不匹配:学术/解释性语气可能不适合所有应用。
访问与分发
下载地址
- Hugging Face:https://huggingface.co/datasets/Bytte-AI/Pidgin_Question-English_Answer_Dataset
- Figshare:https://figshare.com/articles/dataset/Pidgin_Question_-_English_Answer_Dataset/31288486?file=61721260
文件信息
| 文件 |
格式 |
大小 |
描述 |
pidgin_question_english_answer.json |
JSON |
~270 KB |
331个皮钦问题→英语答案对 |
许可证
CC-BY-4.0(知识共享署名4.0国际许可协议)
- 允许:共享、改编、商业用途。
- 要求:必须给予Bytte AI适当署名,提供许可证链接,并说明是否进行了更改。
使用条款
- 需要署名:使用提供的引用格式引用此数据集。
- 承认局限性:在出版物中记录元语言学偏见(49.2%)和跨语言方向性。
- 建议预处理:考虑针对特定应用过滤或标记回答类型。
- 无担保:按“原样”提供,不保证回答质量或适当性。
引用
如果研究或应用中使用此数据集,请引用:
bibtex
@dataset{bytte_ai_pidgin_english_qa_2026,
author = {Bytte AI},
title = {Pidgin Question - English Answer Dataset (Sample)},
year = {2026},
publisher = {Bytte AI},
version = {1.0},
license = {CC-BY-4.0},
url = {https://huggingface.co/datasets/Bytte-AI/Pidgin_Question-English_Answer_Dataset}
}