dolomites
收藏Hugging Face2024-10-29 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/cmalaviya/dolomites
下载链接
链接失效反馈官方服务:
资源简介:
DOLOMITES数据集包含519个任务描述,涵盖25个领域,由266位领域专家协助收集。任务通过具有合理输入和输出的示例实例化,可用于评估语言模型。数据集总共包含1,857个示例。任务和示例数据分别以jsonlines文件格式提供,每个任务和示例包含多个字段,如任务ID、领域、任务目标、任务步骤、输入输出描述等。
创建时间:
2024-10-29
原始信息汇总
数据集卡片:DOLOMITES
数据集描述
数据集概述
DOLOMITES 数据集是伴随论文 DOLOMITES: Domain-Specific Long-Form Methodical Tasks 提供的数据。该数据集包含 519 个任务描述,来自 25 个领域,由 266 位领域专家协助收集。任务通过具有合理输入和输出的示例实例化,可用于评估语言模型。数据集中共有 1,857 个示例。
数据集结构
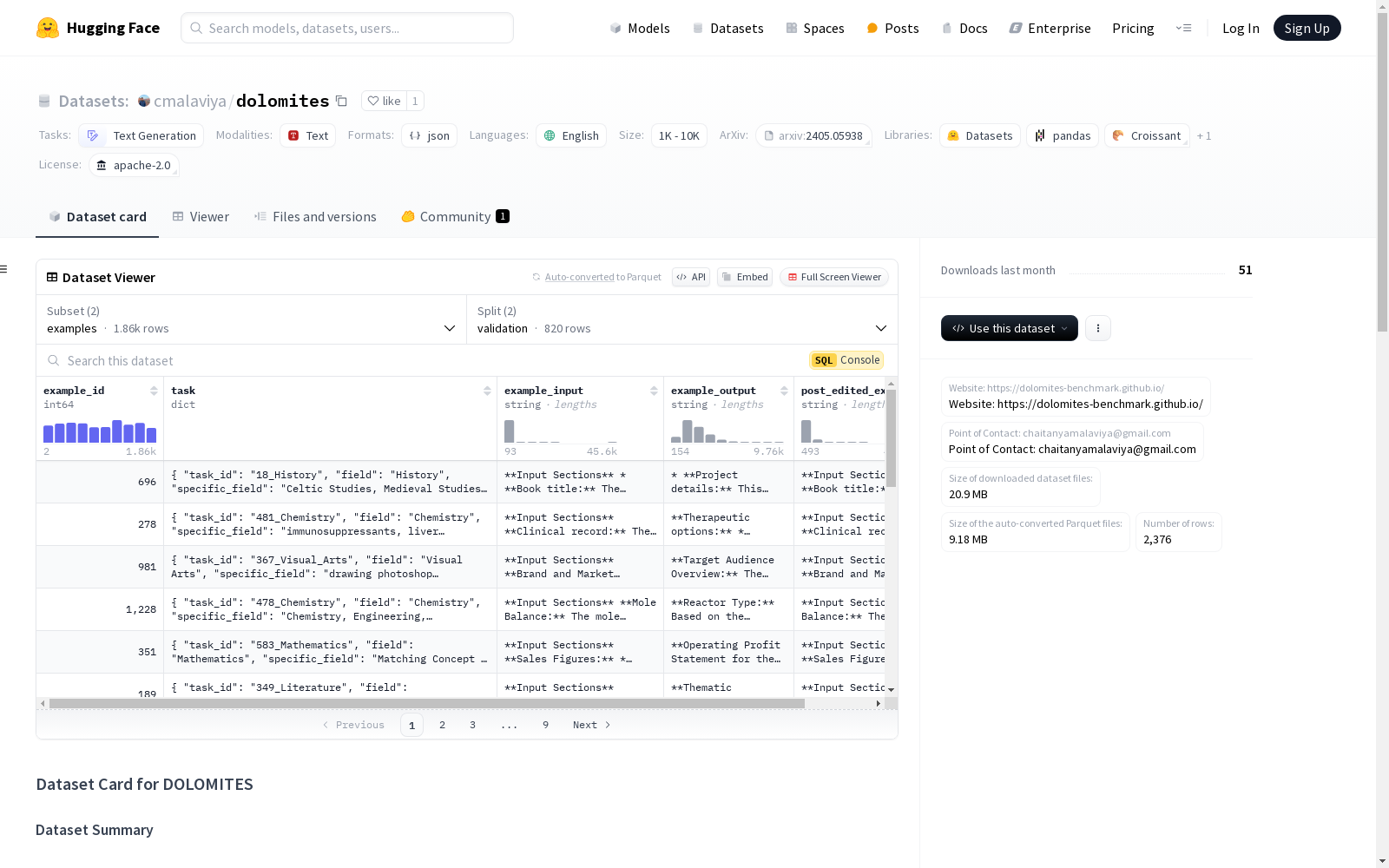
数据实例
任务:数据结构
任务以 jsonlines 文件形式提供,每个任务包含以下字段:
task_id:每个任务的唯一 IDfield:提供任务的专家所属领域specific_field:专家工作的具体子领域或区域task_objective:任务的 1-2 句目标描述task_procedure:描述任务执行过程的几句话task_input:任务的输入部分,格式为 * 部分标题:部分描述task_output:任务的输出部分,格式为 * 部分标题:部分描述task_notes:描述任务的缺失上下文或附加细节的几句话task_urls:注释者提供的与任务相关的 URL 列表annotator_id:提供任务的注释者的唯一匿名 ID
示例:数据结构
数据集提供开发集(830 个示例)和测试集(1037 个示例)。每个文件都是 jsonlines 文件,每行包含以下字段:
example_id:每个示例的唯一 IDtask:以相同格式表示的任务字典post_edited_example:完整的后编辑示例(输入和输出)example_input:示例的输入文本example_input:示例的输出文本
引用信息
@inproceedings{malaviya24dolomites, title = {DOLOMITES: Domain-Specific Long-Form Methodical Tasks}, author = {Chaitanya Malaviya, Priyanka Agrawal, Kuzman Ganchev, Pranesh Srinivasan, Fantine Huot, Jonathan Berant, Mark Yatskar, Dipanjan Das, Mirella Lapata, Chris Alberti}, journal = {Transactions of the Association for Computational Linguistics (TACL)}, year = {2024}, url = "https://arxiv.org/abs/2405.05938" }
搜集汇总
数据集介绍
构建方式
DOLOMITES数据集的构建过程依托于266位领域专家的深度参与,涵盖了25个不同领域的519项任务描述。每个任务均通过具体的实例进行呈现,包含合理的输入与输出,旨在为语言模型的评估提供坚实基础。数据集的开发集和测试集分别包含830和1037个实例,确保了数据的多样性和广泛性。
特点
DOLOMITES数据集以其领域特定性和长形式任务为显著特点,涵盖了广泛的学科领域,确保了任务的多样性和复杂性。每个任务均包含详细的任务目标、执行步骤、输入输出描述以及相关注释,为研究者提供了丰富的上下文信息。此外,数据集还提供了匿名化的标注者ID和相关的URL资源,进一步增强了数据的实用性和可追溯性。
使用方法
DOLOMITES数据集的使用方法主要围绕语言模型的评估展开。研究者可以通过加载数据集中的任务和实例,对模型在特定领域的长形式任务处理能力进行测试。开发集和测试集的划分使得模型可以在开发集上进行初步验证,并在测试集上进行最终评估。每个实例的输入输出结构清晰,便于研究者进行模型性能的定量分析。
背景与挑战
背景概述
DOLOMITES数据集由Google DeepMind团队于2024年发布,旨在为领域特定的长文本方法性任务提供评估基准。该数据集由266位领域专家共同构建,涵盖了25个不同领域的519项任务描述,并包含1,857个具体实例。其核心研究问题在于如何通过领域专家的参与,构建高质量的任务描述与实例,以评估语言模型在复杂、长文本任务中的表现。DOLOMITES的发布为自然语言处理领域提供了新的研究方向,特别是在长文本生成与领域特定任务评估方面,具有重要的学术与应用价值。
当前挑战
DOLOMITES数据集在构建与应用过程中面临多重挑战。首先,领域特定任务的多样性与复杂性要求专家具备深厚的领域知识,以确保任务描述与实例的准确性与代表性。其次,数据集的构建需要协调大量专家,确保任务的一致性与高质量,这对组织与协调能力提出了较高要求。此外,长文本任务的评估需要语言模型具备更强的上下文理解与生成能力,这对现有模型的性能提出了新的挑战。最后,数据集的公开与使用需平衡透明度与隐私保护,特别是在涉及专家信息与任务细节时,需确保数据的匿名性与安全性。
常用场景
经典使用场景
DOLOMITES数据集在自然语言处理领域中被广泛用于评估语言模型在长文本生成任务中的表现。该数据集包含了来自25个不同领域的519个任务描述,每个任务都配有详细的输入和输出示例,能够为模型提供丰富的上下文信息。研究人员可以利用这些任务来测试模型在复杂、多步骤任务中的理解和生成能力,特别是在需要领域专业知识的情境下。
衍生相关工作
DOLOMITES数据集自发布以来,已经催生了一系列相关研究,特别是在领域特定语言模型和长文本生成任务方面。许多研究团队利用该数据集开发了新的模型架构和训练方法,以提高模型在复杂任务中的表现。此外,该数据集还被用于评估多模态语言模型和跨领域迁移学习的效果,推动了自然语言处理技术在多个领域的应用和发展。
数据集最近研究
最新研究方向
在自然语言处理领域,DOLOMITES数据集的推出标志着对领域特定长文本任务评估的深入探索。该数据集由266位领域专家共同构建,涵盖了25个不同领域的519项任务描述,旨在评估语言模型在处理复杂、结构化任务时的表现。随着大语言模型(LLMs)的快速发展,如何有效评估这些模型在特定领域的实际应用能力成为研究热点。DOLOMITES通过提供详细的输入输出示例,为研究者提供了一个标准化的评估框架,推动了领域特定任务生成与评估方法的研究。此外,该数据集的发布也促进了跨领域知识迁移与模型泛化能力的探讨,为未来语言模型在专业领域的应用奠定了重要基础。
以上内容由遇见数据集搜集并总结生成


