DTVLT
收藏arXiv2024-10-03 更新2024-10-05 收录
下载链接:
http://videocube.aitestunion.com/
下载链接
链接失效反馈官方服务:
资源简介:
DTVLT是由中国科学院自动化研究所等机构创建的多模态视觉语言跟踪基准,旨在通过多样化的文本描述提升视频理解算法的性能。数据集包含13134条视频数据,覆盖了短期跟踪、长期跟踪和全局实例跟踪三个主流任务。创建过程中,利用大型语言模型(LLM)生成多粒度的文本描述,以丰富视频内容的语义信息。DTVLT的应用领域主要集中在视觉语言跟踪和视频理解,旨在解决传统单模态跟踪算法在复杂视频内容理解中的局限性。
DTVLT is a multimodal vision-language tracking benchmark developed by institutions including the Institute of Automation, Chinese Academy of Sciences, aiming to improve the performance of video understanding algorithms via diverse textual descriptions. The dataset contains 13,134 video samples, covering three mainstream tasks: short-term tracking, long-term tracking, and global instance tracking. During its construction, large language models (LLMs) were utilized to generate multi-granularity textual descriptions to enrich the semantic information of video content. The application domains of DTVLT mainly focus on vision-language tracking and video understanding, and it is designed to address the limitations of traditional unimodal tracking algorithms in complex video content understanding.
提供机构:
中国科学院自动化研究所
创建时间:
2024-10-03
搜集汇总
数据集介绍
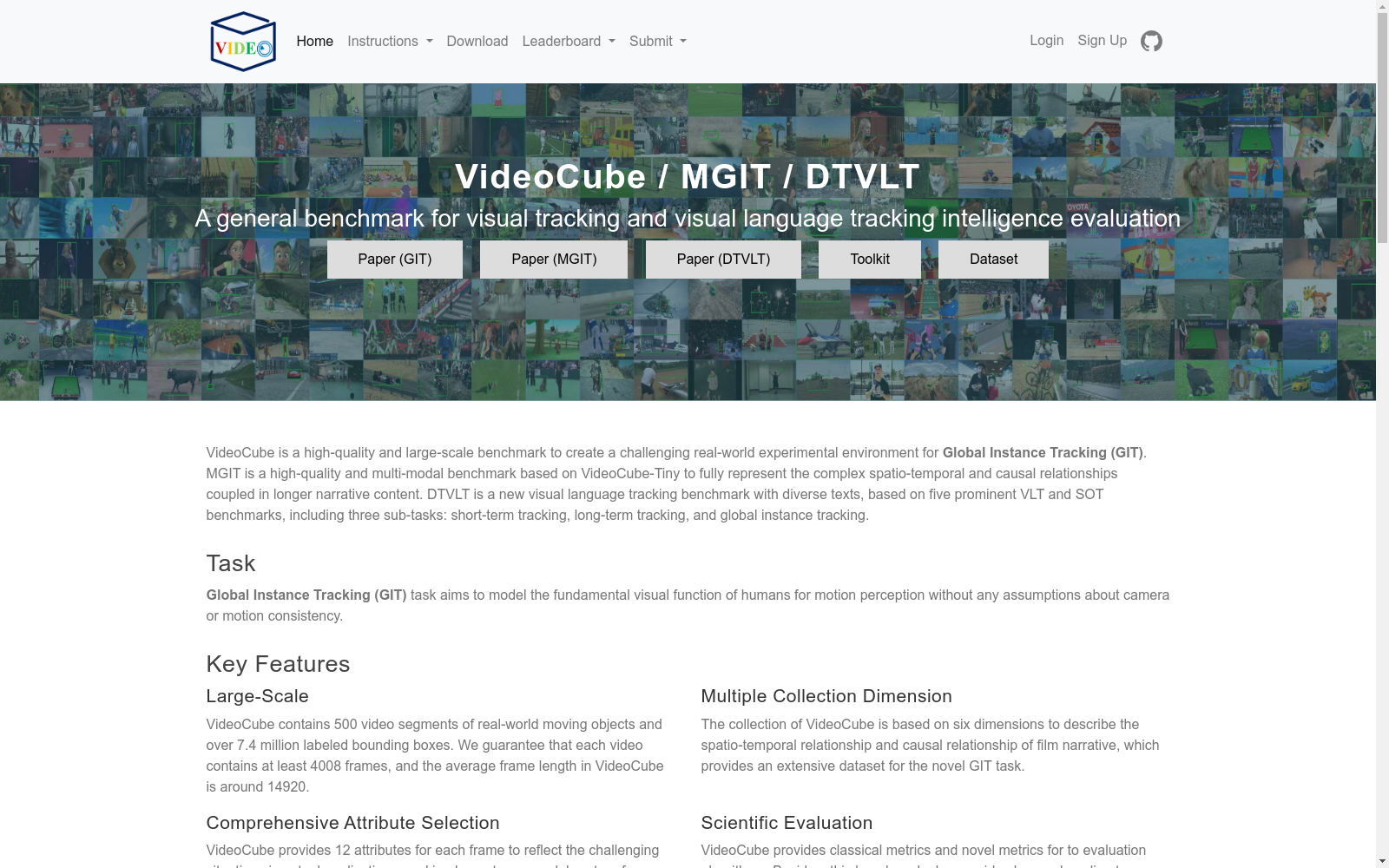
构建方式
DTVLT数据集的构建基于五个著名的视觉语言跟踪(VLT)和单目标跟踪(SOT)基准,包括短期跟踪、长期跟踪和全局实例跟踪三个子任务。该数据集利用大型语言模型(LLM)生成多样化的语义注释,通过DTLLM-VLT方法,结合文本长度和生成密度,创建了四种不同的粒度级别。具体而言,DTVLT在五个代表性数据集上生成了大量的高质量、多样化的文本描述,旨在为VLT和视频理解研究提供一个有利的环境。
特点
DTVLT数据集的主要特点在于其多模态和多样化的文本注释。与传统的单一粒度文本描述不同,DTVLT提供了四种不同粒度的文本,包括密集简洁、密集详细、初始简洁和初始详细。这种多粒度的生成策略不仅丰富了语义信息的密度和广度,还显著提升了算法对视频内容动态变化的捕捉能力,从而避免了算法依赖‘记忆答案’的策略。
使用方法
DTVLT数据集的使用方法主要包括直接测试和重新训练测试两种机制。在直接测试中,利用官方提供的权重文件,替换为DTVLT的文本进行性能评估。在重新训练测试中,基于官方权重继续训练50个周期,使用DTVLT的多样化文本进行训练和测试。通过这两种机制,可以全面评估算法在不同文本环境下的性能,识别现有算法的性能瓶颈,并为VLT和视频理解研究的进一步发展提供支持。
背景与挑战
背景概述
视觉语言跟踪(Visual Language Tracking, VLT)作为前沿研究领域,通过融合语言数据以增强多模态输入算法,并扩展了传统单目标跟踪(Single Object Tracking, SOT)的应用范围,涵盖视频理解任务。尽管如此,大多数VLT基准仍依赖于简洁的人工标注文本描述,这些描述往往无法捕捉视频内容的细微动态,且在语言风格上缺乏多样性,受限于统一的细节层次和固定的标注频率。因此,算法倾向于采用‘记忆答案’的策略,偏离了实现对视频内容更深层次理解的核心目标。幸运的是,大型语言模型(Large Language Models, LLMs)的出现使得生成多样化的文本成为可能。本研究利用LLMs为具有代表性的SOT基准生成不同语义注释(在文本长度和粒度方面),从而建立了一个新的多模态基准。具体而言,我们提出了一个新的视觉语言跟踪基准,命名为DTVLT,基于五个著名的VLT和SOT基准,包括三个子任务:短期跟踪、长期跟踪和全局实例跟踪。我们还提供了四种粒度的文本,考虑了语义信息的广度和密度,通过DTLLM-VLT方法生成高质量、多样化的文本,利用LLMs的广泛知识库生成丰富的世界知识描述。我们期望这种多粒度生成策略能够为VLT和视频理解研究创造有利的环境。
当前挑战
DTVLT数据集面临的挑战主要集中在两个方面:一是解决领域问题的挑战,二是构建过程中遇到的挑战。在解决领域问题方面,现有的VLT基准主要依赖于简洁的人工标注文本描述,这些描述往往无法捕捉视频内容的细微动态,且在语言风格上缺乏多样性,导致算法难以实现对视频内容更深层次的理解。在构建过程中,依赖于人工标注的文本生成过程耗时且资源密集,且单一粒度的文本描述限制了算法的灵活性和全面性。因此,DTVLT通过利用LLMs生成多样化的文本,旨在克服这些挑战,提供一个更加灵活和全面的环境,以支持VLT和视频理解研究。
常用场景
经典使用场景
DTVLT数据集在视觉语言跟踪(VLT)领域中被广泛用于评估和提升多模态输入算法的性能。其经典使用场景包括短时跟踪、长时跟踪和全局实例跟踪三个子任务。通过提供多样化的文本描述,DTVLT能够模拟真实世界中视频内容的复杂性和动态变化,从而帮助算法在不同粒度和长度的文本描述下进行训练和测试,以实现对视频内容的更深层次理解。
实际应用
在实际应用中,DTVLT数据集可以用于开发和优化智能监控系统、自动驾驶车辆中的目标跟踪技术,以及增强现实(AR)和虚拟现实(VR)中的交互体验。通过提供多粒度的文本描述,DTVLT能够帮助这些系统更好地理解和响应复杂环境中的动态变化,从而提高其鲁棒性和准确性。
衍生相关工作
DTVLT数据集的提出激发了一系列相关研究工作,包括基于多模态学习的视觉语言跟踪算法改进、文本生成技术的进一步优化,以及视频内容理解的深度学习模型开发。例如,MMTrack和UVLTrack等算法在DTVLT的多样化文本环境下进行了性能评估和改进,展示了多模态数据在提升跟踪精度方面的潜力。
以上内容由遇见数据集搜集并总结生成


