Eka-IndicMTEB
收藏Hugging Face2025-11-12 更新2025-11-13 收录
下载链接:
https://huggingface.co/datasets/ekacare/Eka-IndicMTEB
下载链接
链接失效反馈官方服务:
资源简介:
Eka-IndicMTEB是一个包含印度多语言医学术语的评价数据集,旨在评估嵌入模型在跨多种印度语言和脚本医学术语上的表现。它包含了2,532个经过医生验证的查询,捕捉了印度医疗生态系统的语言和领域特定多样性。
创建时间:
2025-10-31
原始信息汇总
Eka-IndicMTEB 数据集概述
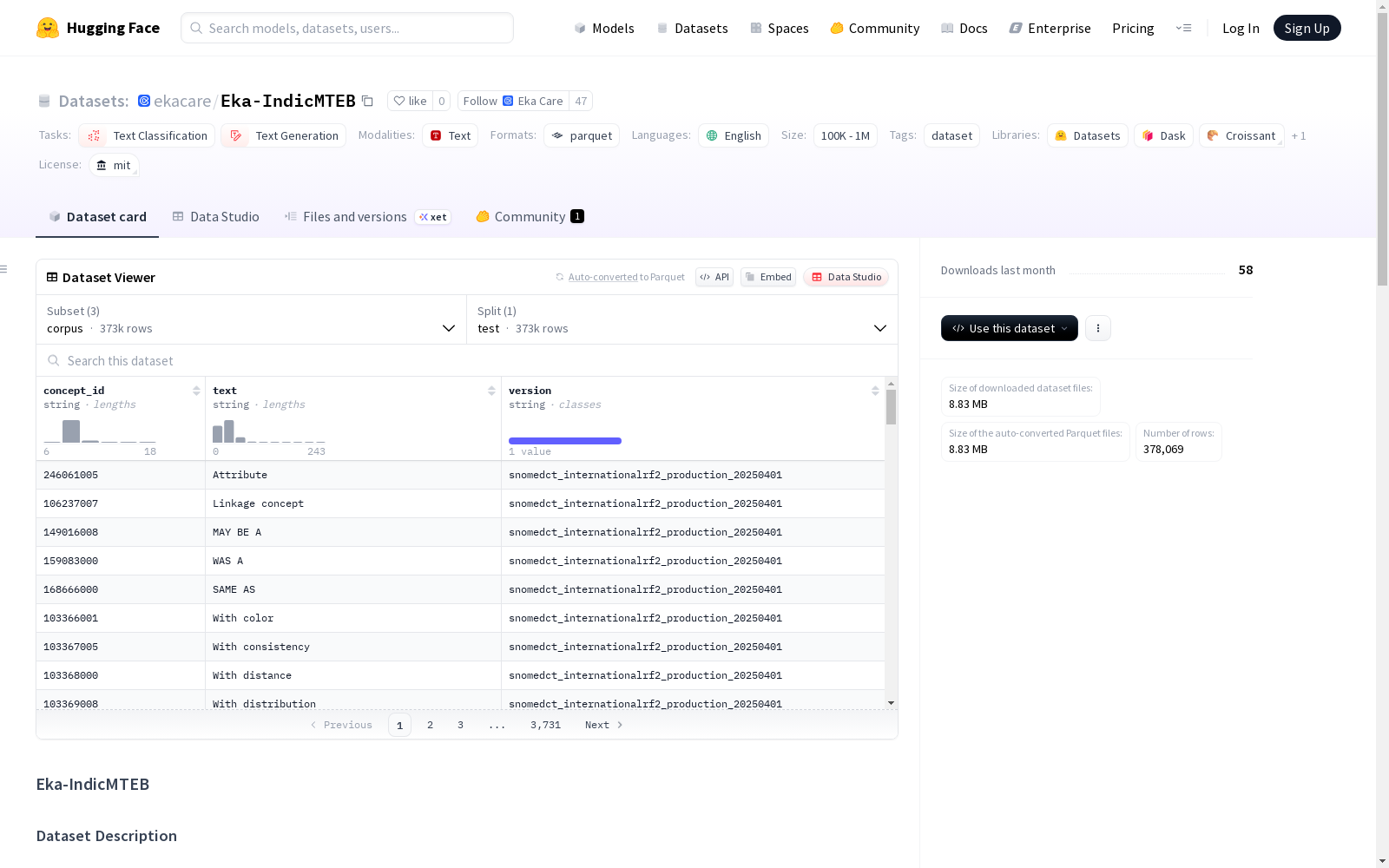
数据集基本信息
- 数据集名称: Eka-IndicMTEB
- 许可证: MIT License
- 数据规模: 100K<n<1M
- 任务类别: 文本分类、文本生成
- 支持语言: 英语
数据集描述
Eka-IndicMTEB 是一个用于评估多语言医学术语嵌入模型的评估数据集,专门针对印度多种语言和文字的医学术语设计。数据集包含2,532个经过医生验证的查询,捕捉了印度医疗生态系统中的语言和领域特定多样性。
数据内容特征
- 医学实体类型: 症状、诊断、程序、药物及相关概念
- 语言变异特征: 拼写错误、特殊字符、缩写词、口语表达
- 覆盖语言: 英语、印地语、孟加拉语、泰米尔语、泰卢固语、卡纳达语、马拉地语、马拉雅拉姆语
数据集结构
配置1: corpus
- 特征字段:
- concept_id (字符串)
- text (字符串)
- version (字符串)
- 数据分割: test
- 样本数量: 373,005
- 数据集大小: 746,010,000字节
- 下载大小: 634,108,500字节
配置2: qrels
- 特征字段:
- term_id (字符串)
- concept_id (字符串)
- score (int64)
- 数据分割: test
- 样本数量: 2,532
- 数据集大小: 5,064,000字节
- 下载大小: 4,304,400字节
配置3: queries
- 特征字段:
- term_id (字符串)
- term (字符串)
- concept_id (字符串)
- is_abbreviation (布尔值)
- is_core_concept (布尔值)
- language (字符串)
- script (字符串)
- is_active (布尔值)
- version (字符串)
- 数据分割: test
- 样本数量: 2,532
- 数据集大小: 5,064,000字节
- 下载大小: 4,304,400字节
数据集创建
- 创建方式: 由内部医学专业人员策划,确保临床准确性和语言多样性
- 标注标准: 每个查询都经过人工审查,并使用相应的SNOMED CT标识符进行标注
- 概念对齐: 确保跨语言的概念级别对齐
应用价值
- 为研究人员提供共享评估框架
- 揭示模型在处理印度语言多样性方面的优势和弱点
- 为多语言医学信息检索系统和临床决策支持工具的开发提供指导
- 支持医疗组织验证跨语言性能
贡献者
- Dr Sanjana SN
- Dr Anushree Rana
- Dr Rajshree Badami
搜集汇总
数据集介绍
构建方式
在医学信息学领域,多语言术语标准化对临床知识表示至关重要。该数据集由内部医学专家团队精心构建,通过人工审核与标注流程,将2532条医疗查询与SNOMED CT国际标准术语体系进行概念级对齐。构建过程特别注重临床准确性与语言多样性,涵盖症状、诊断、治疗等医疗实体,并保留真实场景中的拼写变异、特殊字符及方言表达,确保数据既符合医学术语规范又反映实际语言使用特征。
特点
作为印度多语言医疗术语评估基准,本数据集突显三大核心特质:其概念体系覆盖八种主要印度语言及文字系统,包括印地语、孟加拉语等,形成跨语言家族的语义网络;查询数据包含丰富的语言现象,如专业缩写、口语化表达等临床常见变体;数据结构采用标准化评估框架,通过查询集、相关度标注与检索语料库的三元组设计,为嵌入模型提供系统化评测维度。
使用方法
针对医疗自然语言处理研究需求,该数据集支持灵活的加载方式。研究者可通过HuggingFace数据集库调用特定子集,如单独加载检索语料库或查询集进行针对性实验。在模型评估场景中,建议结合qrels子集的相关度标注构建检索任务,通过计算查询与候选术语的语义匹配度来验证多语言医疗嵌入模型的效能。该设计尤其适用于开发临床决策支持系统与跨语言医学信息检索应用。
背景与挑战
背景概述
随着多语言医疗人工智能技术的快速发展,印度次大陆复杂的语言生态对临床术语标准化提出了严峻考验。Eka-IndicMTEB数据集由Eka医疗团队于2024年构建,其核心目标在于建立跨语言医疗术语的标准化评估体系。该数据集整合了英语、印地语、孟加拉语等八种印度主要语言,通过2532条经医师核验的医学术语查询,实现了与SNOMED CT国际医学术语系统的概念级对齐,为印度多语言医疗自然语言处理研究提供了关键基础设施。
当前挑战
在医疗术语跨语言对齐领域,该数据集需克服印度语言间字符体系与语法结构的显著差异,同时确保医学术语在方言变体中的概念一致性。构建过程中面临双重挑战:其一是临床准确性保障,需要医学专家逐条验证术语的医学语义完整性;其二是语言多样性处理,需系统收录拼写变异、特殊符号、俚语表达等真实语言现象,这对标注规范设计与质量管控提出了极高要求。
常用场景
经典使用场景
在跨语言医学信息检索领域,Eka-IndicMTEB数据集为评估多语言嵌入模型提供了标准化测试平台。该数据集通过涵盖英语、印地语、孟加拉语等八种印度语言的医学术语,支持研究者系统评估模型在症状描述、诊断术语等临床文本中的语义理解能力。其精心设计的查询-语料库关联结构,能够有效验证模型在处理拼写变异、专业缩写等复杂语言现象时的鲁棒性。
实际应用
在临床决策支持系统开发中,该数据集为多语言医疗聊天机器人和语义搜索系统提供了关键验证工具。医疗机构可借助其丰富的语言变体测试临床术语检索系统的覆盖范围,确保不同语言使用群体都能获得准确的医疗信息。制药企业也能利用该数据集优化多地区药品说明书的跨语言一致性检测。
衍生相关工作
基于该数据集衍生的研究已推动多项医疗嵌入模型创新,包括针对达罗毗荼语系优化的临床BERT变体,以及融合SNOMED CT知识的跨语言对齐算法。这些工作通过利用数据集中标注的语言家族特征和概念层级关系,显著提升了南亚地区低资源语言医疗文本的处理精度,为后续区域性医疗AI标准化评估体系的建立奠定基础。
以上内容由遇见数据集搜集并总结生成


