DFKI-SLT/conll04
收藏数据集概述
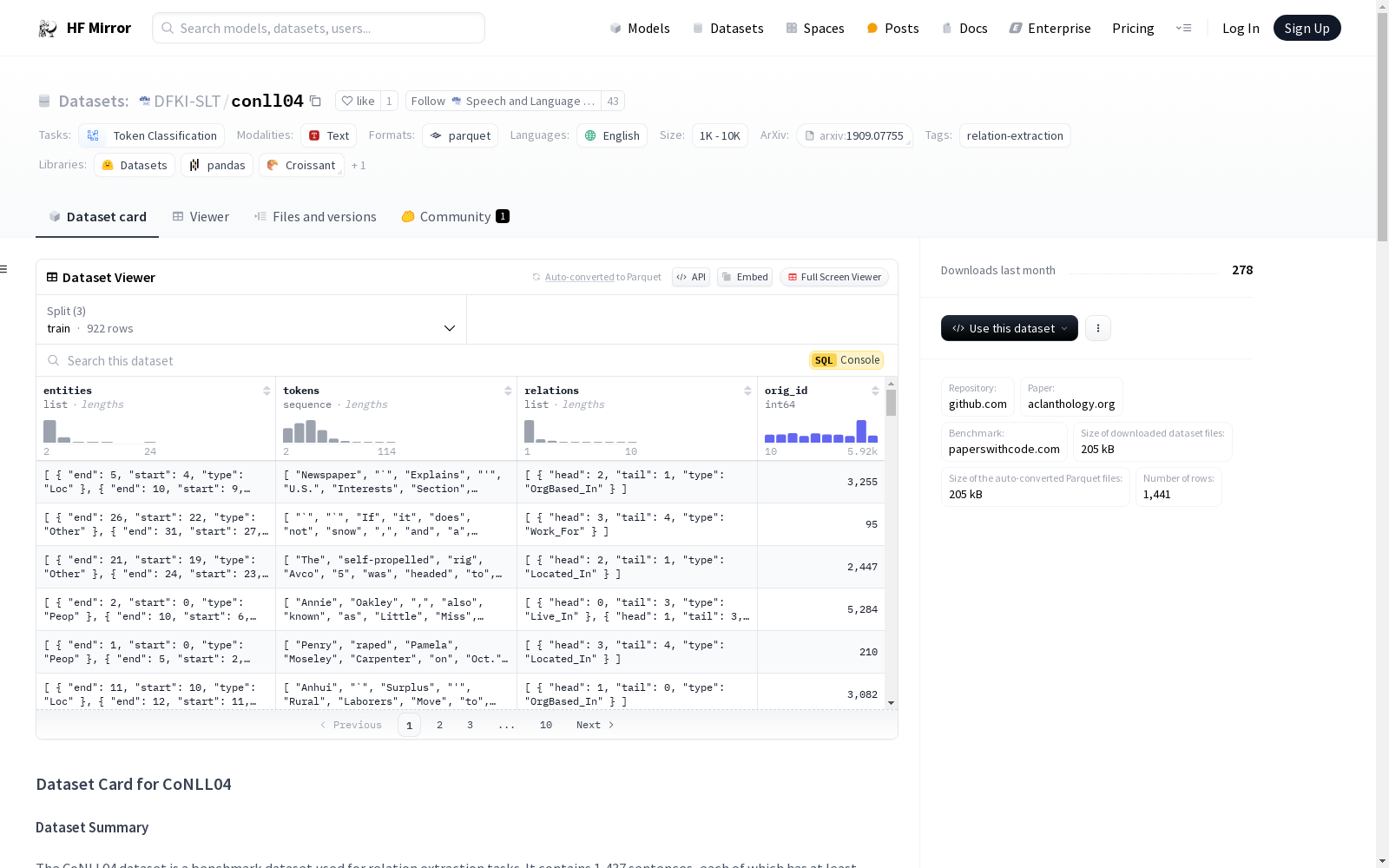
数据集名称: CoNLL04
数据集用途: 关系抽取任务
语言: 英语
数据集大小: 1,437个句子,每个句子至少包含一个关系。
数据集结构
数据字段
- tokens: 文本内容,字符串类型。
- entities: 实体列表
- type: 实体类型,字符串类型。
- start: 实体起始索引,整数类型。
- end: 实体结束索引,整数类型。
- relations: 关系列表
- type: 关系类型,字符串类型。
- head: 头实体索引,整数类型。
- tail: 尾实体索引,整数类型。
数据集分割
- 训练集(train): 922个样本,358752字节。
- 验证集(validation): 231个样本,94688字节。
- 测试集(test): 288个样本,114248字节。
数据集配置
- 默认配置(default):
- 训练数据路径: data/train-*
- 验证数据路径: data/validation-*
- 测试数据路径: data/test-*
引用信息
BibTeX:
@inproceedings{roth-yih-2004-linear, title = "A Linear Programming Formulation for Global Inference in Natural Language Tasks", author = "Roth, Dan and Yih, Wen-tau", booktitle = "Proceedings of the Eighth Conference on Computational Natural Language Learning ({C}o{NLL}-2004) at {HLT}-{NAACL} 2004", month = may # " 6 - " # may # " 7", year = "2004", address = "Boston, Massachusetts, USA", publisher = "Association for Computational Linguistics", url = "https://aclanthology.org/W04-2401", pages = "1--8", } @article{eberts-ulges2019spert, author = {Markus Eberts and Adrian Ulges}, title = {Span-based Joint Entity and Relation Extraction with Transformer Pre-training}, journal = {CoRR}, volume = {abs/1909.07755}, year = {2019}, url = {http://arxiv.org/abs/1909.07755}, eprinttype = {arXiv}, eprint = {1909.07755}, timestamp = {Mon, 23 Sep 2019 18:07:15 +0200}, biburl = {https://dblp.org/rec/journals/corr/abs-1909-07755.bib}, bibsource = {dblp computer science bibliography, https://dblp.org} }
APA:
- Roth, D., & Yih, W. (2004). A linear programming formulation for global inference in natural language tasks. In Proceedings of the Eighth Conference on Computational Natural Language Learning (CoNLL-2004) at HLT-NAACL 2004 (pp. 1-8). Boston, Massachusetts, USA: Association for Computational Linguistics. https://aclanthology.org/W04-2401
- Eberts, M., & Ulges, A. (2019). Span-based joint entity and relation extraction with transformer pre-training. CoRR, abs/1909.07755. http://arxiv.org/abs/1909.07755