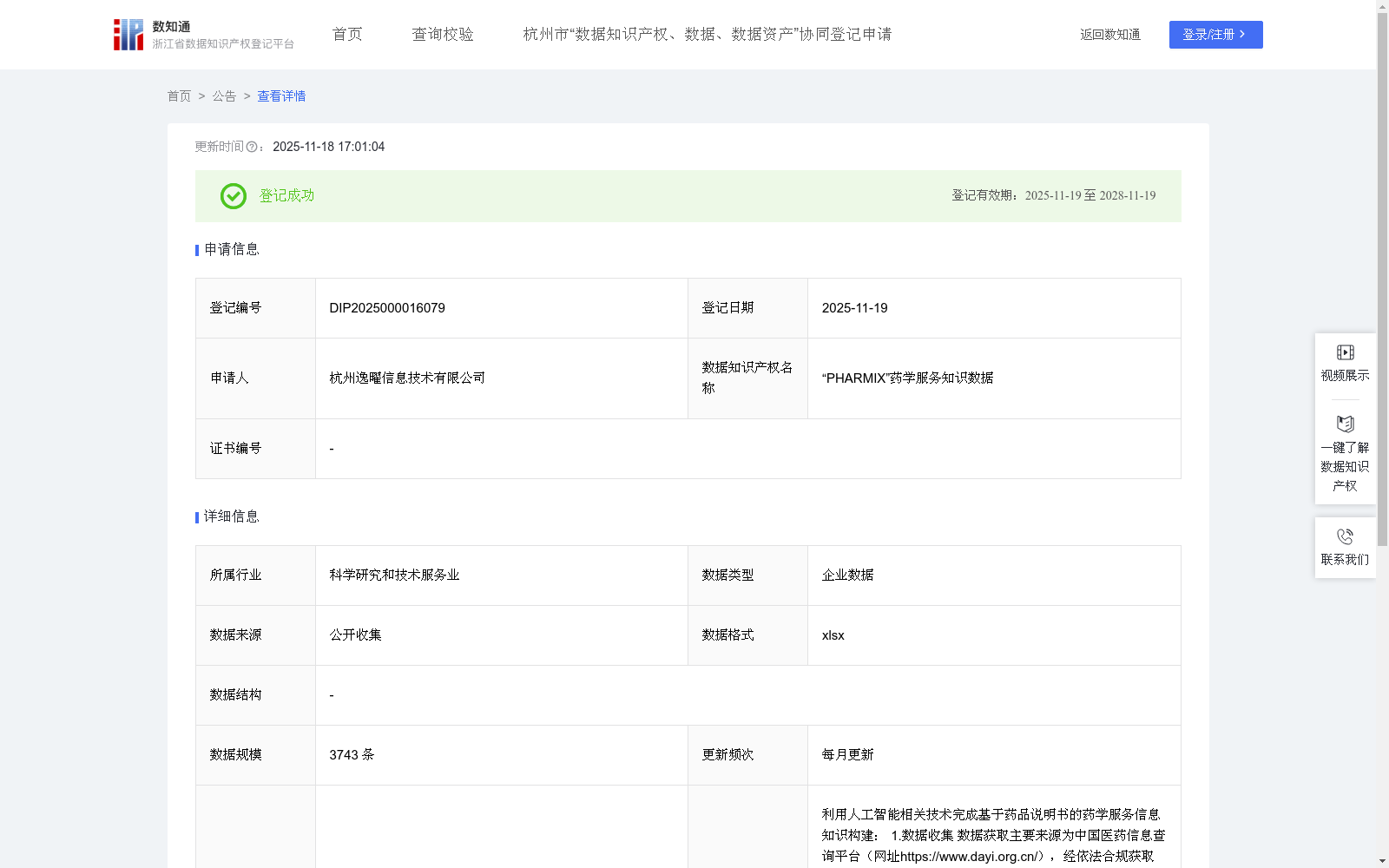
“PHARMIX”药学服务知识数据
收藏浙江省数据知识产权登记平台2025-11-18 更新2025-11-19 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/8401586
下载链接
链接失效反馈官方服务:
资源简介:
本数据提供了药学服务知识,具体包括:用药方法、用药注意事项、特殊人群注意事项、忘记服药处理方法、可能存在的不良反应、药品储存方法等。本数据可辅助医药学人员开展药学服务,将专业的药学知识转化为通俗易懂的指导信息,提升患者用药的安全性和有效性。利用人工智能相关技术完成基于药品说明书的药学服务信息知识构建:
1.数据收集
数据获取主要来源为中国医药信息查询平台(网址https://www.dayi.org.cn/),经依法合规获取的公开数据,从中收集大量药品说明书文本,再对说明书内容进行结构化处理和呈现。
2.信息抽取
利用自然语言处理技术(NLP)抽取适应症、用法用量、注意事项、储存方法、不良反应、育龄人群用药、孕期用药等关键信息。借助机器学习模型(如条件随机场CRF、深度神经网络DNN)提高信息抽取的准确率。
3.实体与关系识别
识别说明书中的药品名称、用法用量、给药时机等实体,并确定实体间的关系。
4.结构化知识构建
将抽取的信息整合,形成结构化的药品知识库。每个药品节点包含用药方法、储存条件、注意事项、不良反应等详细属性。
5. 验证与更新
药学专家对抽取的信息进行验证,确保准确性和可靠性。同时收集用户反馈,不断优化信息抽取和呈现方式。
通过上述步骤,将药品说明书中的用药信息转化为结构化、易于理解的药学服务知识,提升患者用药的安全性和有效性。
This dataset provides pharmaceutical care knowledge, specifically including: medication administration methods, medication precautions, precautions for special populations, handling methods for missed doses, potential adverse reactions, drug storage methods, etc. This dataset can assist medical and pharmaceutical personnel in carrying out pharmaceutical care, transforming professional pharmaceutical knowledge into easy-to-understand guidance information, and improving the safety and effectiveness of patients' medication.
The construction of pharmaceutical care information knowledge based on drug package inserts is completed using relevant artificial intelligence technologies:
1. Data Collection: The data is mainly sourced from the China Medical Information Query Platform (URL: https://www.dayi.org.cn/), where publicly available data is obtained in compliance with laws and regulations. A large number of drug package insert texts are collected, followed by structured processing and presentation of the insert content.
2. Information Extraction: Natural Language Processing (NLP) technologies are used to extract key information such as indications, dosage and administration, precautions, storage methods, adverse reactions, medication for people of childbearing age, and medication during pregnancy. Machine learning models (such as Conditional Random Fields (CRF) and Deep Neural Networks (DNN)) are employed to improve the accuracy of information extraction.
3. Entity and Relationship Recognition: Entities such as drug names, dosage and administration, and administration timing in the package inserts are identified, and the relationships between entities are determined.
4. Structured Knowledge Construction: The extracted information is integrated to form a structured drug knowledge base. Each drug node contains detailed attributes such as medication administration methods, storage conditions, precautions, adverse reactions, etc.
5. Verification and Update: Pharmaceutical experts verify the extracted information to ensure its accuracy and reliability. Meanwhile, user feedback is collected to continuously optimize the information extraction and presentation methods.
Through the above steps, the medication information in drug package inserts is transformed into structured and easy-to-understand pharmaceutical care knowledge, thereby improving the safety and effectiveness of patients' medication.
提供机构:
杭州逸曜信息技术有限公司
创建时间:
2025-08-18
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集名为'PHARMIX'药学服务知识数据,包含3743条结构化企业数据,每月更新,来源于公开药品说明书,通过自然语言处理技术抽取用药方法、注意事项等关键信息。它专为药学服务设计,可辅助医药人员提供通俗易懂的用药指导,提升患者用药的安全性和有效性。
以上内容由遇见数据集搜集并总结生成


