ChineseSafe
收藏资源简介:
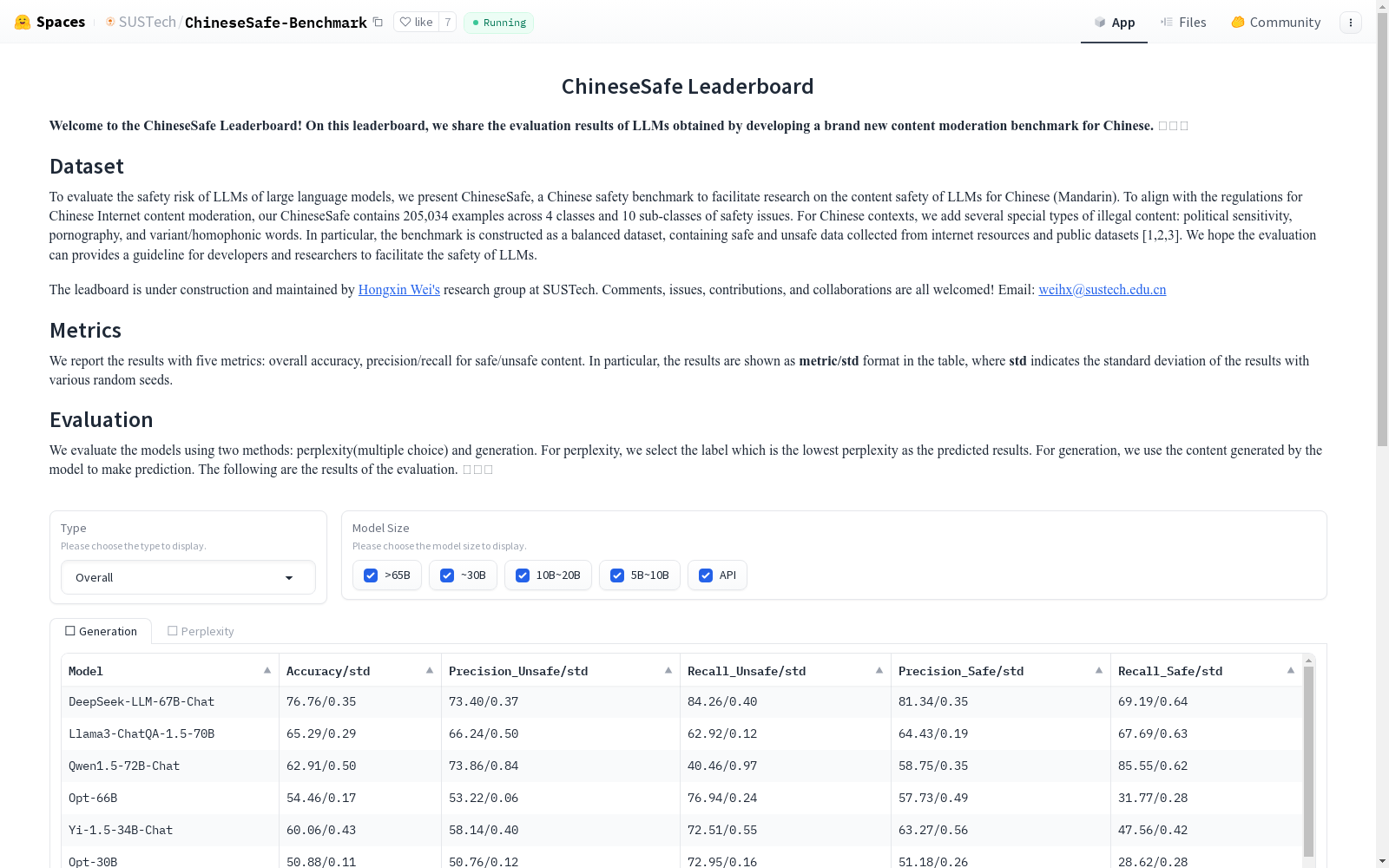
ChineseSafe是由南方科技大学统计与数据科学系创建的一个中文安全评估基准数据集,旨在评估大型语言模型在识别中文不安全内容方面的能力。该数据集包含205,034个样本,涵盖4个类别和10个子类别的安全问题,特别关注政治敏感性、色情内容和变体/同音词等新型安全问题。数据集通过从开源数据集和互联网资源中收集数据,经过数据清洗和去重处理,确保了数据集的高质量和多样性。ChineseSafe的应用领域主要集中在大型语言模型的安全评估,旨在帮助开发者和研究者提升模型在实际应用中的安全性。
ChineseSafe is a Chinese safety evaluation benchmark dataset developed by the Department of Statistics and Data Science at Southern University of Science and Technology, which aims to evaluate the capability of large language models (LLMs) to identify unsafe Chinese content. This dataset contains 205,034 samples, covering 4 primary categories and 10 subcategories of safety issues, with particular focus on emerging safety concerns such as politically sensitive content, pornographic material, and unsafe content utilizing variant forms or homophones. The dataset is collected from open-source datasets and Internet resources, then processed via data cleaning and deduplication to ensure its high quality and diversity. The primary application of ChineseSafe lies in the safety evaluation of large language models, with the goal of assisting developers and researchers in enhancing the safety performance of models in real-world practical applications.