huanngzh/DeepFashion-MultiModal-Parts2Whole
收藏数据集概述
数据集名称
DeepFashion MultiModal Parts2Whole
许可协议
Apache-2.0
任务类别
- 文本到图像
- 图像到图像
数据集描述
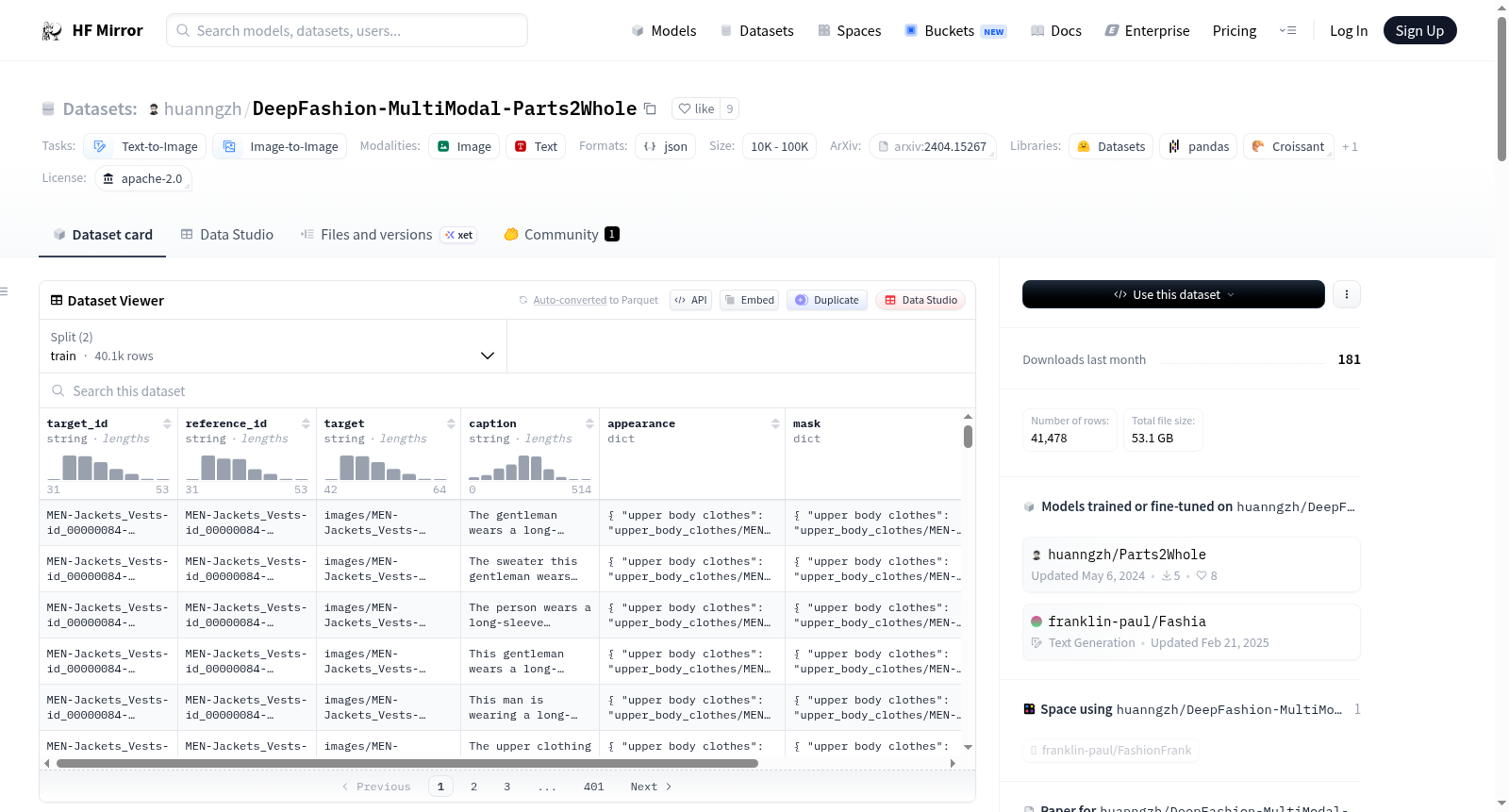
该数据集包含约41,500对参考-目标图像对。每对数据包括多个参考图像,这些图像涵盖了人体姿态图像(如OpenPose、Human Parsing、DensePose)、人体外观的各个方面(如头发、面部、衣物、鞋子)及其简短文本标签,以及一个目标图像,展示同一人物(ID)穿着相同服装但姿态不同,并附有文本描述。
数据集来源
- 仓库: https://github.com/huanngzh/Parts2Whole
- 论文: https://arxiv.org/pdf/2404.15267
数据集结构
数据集提供训练和测试的jsonl文件,用于索引参考和目标图像。每个jsonl文件中的样本包含以下字段:
target_id: 目标人物在原始DeepFashion-MultiModal数据集中的IDreference_id: 参考人物在原始DeepFashion-MultiModal数据集中的IDtarget: 目标人物图像的相对路径caption: 目标人物图像的文本描述appearance: 人体外观各部分的图像路径mask: 人体外观各部分的掩码图像路径structure: 人体结构图像路径
数据集创建
源数据
数据集基于DeepFashion MultiModal数据集构建,该数据集是一个大规模高质量的人体数据集,具有丰富的多模态注释。
数据收集和处理
数据集从DeepFashion-MultiModal数据集中构建了约41,500对参考-目标图像对。处理过程中,通过提取面部ID特征并使用余弦相似度评估图像ID特征对的相似性,清洗了ID数据。使用DWPose生成姿态图像,并根据人体解析文件将人体图像裁剪成各个部分。应用Real-ESRGAN增强图像分辨率,以获得更清晰的参考图像。文本描述用作图像的标题。
引用信息
@article{huang2024parts2whole, title={From Parts to Whole: A Unified Reference Framework for Controllable Human Image Generation}, author={Huang, Zehuan and Fan, Hongxing and Wang, Lipeng and Sheng, Lu}, journal={arXiv preprint arXiv:2404.15267}, year={2024} }
@article{jiang2022text2human, title={Text2Human: Text-Driven Controllable Human Image Generation}, author={Jiang, Yuming and Yang, Shuai and Qiu, Haonan and Wu, Wayne and Loy, Chen Change and Liu, Ziwei}, journal={ACM Transactions on Graphics (TOG)}, volume={41}, number={4}, articleno={162}, pages={1--11}, year={2022}, publisher={ACM New York, NY, USA}, doi={10.1145/3528223.3530104}, }