PhreshPhish
收藏arXiv2025-07-15 更新2025-07-17 收录
下载链接:
https://huggingface.co/datasets/phreshphish/phreshphish
下载链接
链接失效反馈官方服务:
资源简介:
PhreshPhish是一个大规模、高质量的钓鱼网站数据集,由OpenText研究机构收集,旨在解决现有钓鱼网站数据集质量不高、数据量不足的问题。该数据集通过自动化和人工标注的方式清理数据,确保其质量,并通过Hugging Face平台提供访问。数据集的创建过程涉及网页的收集、清洗和评估,旨在为钓鱼检测模型提供训练和评估。该数据集适用于钓鱼检测领域,旨在解决网络钓鱼攻击带来的经济和声誉损害问题。
PhreshPhish is a large-scale, high-quality phishing website dataset collected by OpenText Research, which aims to address the problems of poor quality and insufficient data volume in existing phishing website datasets. This dataset cleans and validates data through both automated and manual annotation methods to ensure its quality, and provides access via the Hugging Face platform. The dataset creation process involves web collection, cleaning and evaluation, and is intended to provide training and evaluation resources for phishing detection models. Tailored for the phishing detection domain, this dataset is designed to mitigate the economic and reputational damages caused by phishing attacks.
提供机构:
OpenText
创建时间:
2025-07-15
原始信息汇总
PhreshPhish 数据集概述
基本信息
- 许可证: Creative Commons Attribution 4.0 International (CC-BY-4.0)
- 规模: 100K < n < 1M
- 任务类别: 文本分类
- 数据集名称: PhreshPhish
- 版本: v1.0.0 (初始发布于2025-05-14)
数据集描述
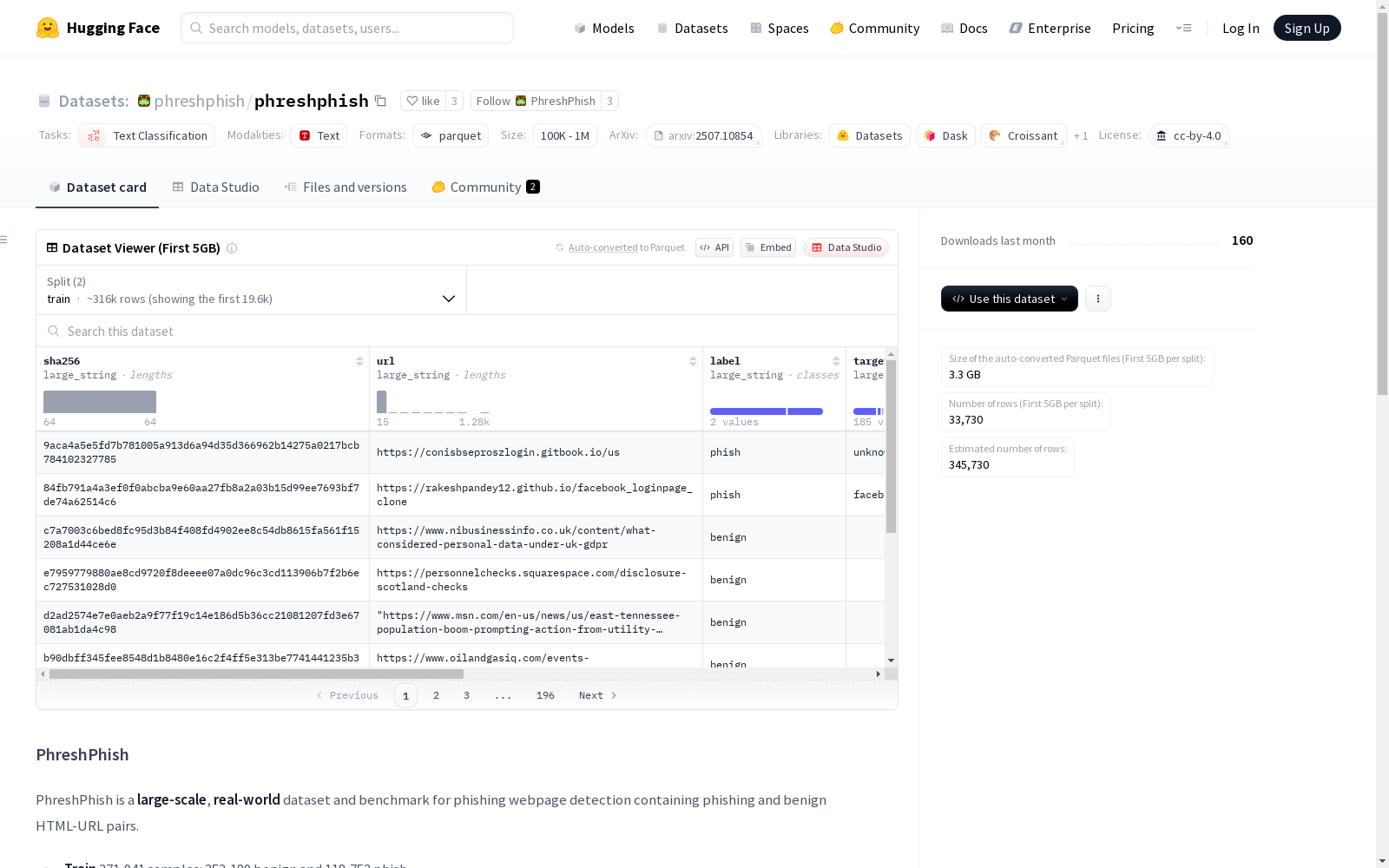
PhreshPhish 是一个用于钓鱼网页检测的大规模、真实世界数据集和基准测试,包含钓鱼和良性HTML-URL对。
数据划分
- 训练集: 371,941 个样本
- 良性: 253,189
- 钓鱼: 118,752
- 测试集: 36,787 个样本
- 良性: 30,048
- 钓鱼: 6,739
基准测试
- 基准数量: 404 个
- 基准率范围: [5e-4, 1e-3, 5e-3, 1e-2, 5e-2]
使用方式
python from datasets import load_dataset
train = load_dataset(phreshphish/phreshphish, split=train) test = load_dataset(phreshphish/phreshphish, split=test)
许可与使用条款
- 许可: 仅限用于反钓鱼研究
- 许可链接: https://creativecommons.org/licenses/by/4.0/
引用
- 论文标题: PhreshPhish: A Real-World, High-Quality, Large-Scale Phishing Website Dataset and Benchmark
- 论文链接: https://arxiv.org/abs/2507.10854
- BibTex引用: bibtex @article{dalton2025phreshphish, title = {PhreshPhish: A Real-World, High-Quality, Large-Scale Phishing Website Dataset and Benchmark}, author = {Thomas Dalton and Hemanth Gowda and Girish Rao and Sachin Pargi and Alireza Hadj Khodabakhshi and Joseph Rombs and Stephan Jou and Manish Marwah}, year = 2025, journal = {arXiv preprint}, url = {https://arxiv.org/abs/2507.10854}, eprint = {2507.10854} }
搜集汇总
数据集介绍
构建方式
PhreshPhish数据集的构建采用了端到端的四阶段流程:首先通过真实浏览器收集网络中的钓鱼和良性HTML数据以确保高保真度;随后结合自动化启发式规则与人工标注对获取的HTML进行清洗和质量评估;接着通过时间划分创建训练集和测试集,并经过剪枝处理以最小化数据泄漏;最终通过多样性筛选、难度增强和基率调整等操作生成基准测试集。该流程特别针对钓鱼网页的对抗性和短暂性特点,采用分布式Selenium集群进行动态内容抓取,并设计了两阶段人工清洗机制(LSH分桶和标题分组)来提升数据质量。
特点
作为当前最大规模的公开钓鱼网站数据集,PhreshPhish包含37.2万条高质量样本(11.9万钓鱼网页和25.3万良性网页),其显著特点体现在三方面:时效性方面,数据采集跨越2024年7月至2025年3月,且计划定期更新版本;质量管控方面,通过自动化规则过滤和基于原型样本的批量人工审核,将错误标注率控制在0.24%以下;基准测试方面,提供404个经过难度分级和基率调整(0.05%-5%)的子集,有效解决了传统数据集基率虚高导致的评估偏差问题。数据集还完整保留了URL结构特征和原始HTML内容,包括动态加载的DOM元素。
使用方法
该数据集支持两种主要应用场景:对于实时钓鱼检测研究,建议采用线性模型或GTE嵌入模型直接处理URL和HTML特征,重点关注精确率指标以降低误报;对于基准测试评估,应使用提供的五组基率子集进行交叉验证,并应用难度过滤器(δ=0.15)剔除10%易分类样本以模拟真实场景。数据以Parquet格式发布,包含SHA256哈希、原始URL、标注标签、目标品牌、采集日期等元数据字段。注意事项包括:1)测试集严格按时间划分,需避免时间泄漏;2)HTML中的JavaScript和CSS内容已被预处理但保留语义结构;3)基准测试需报告不同基率下的平均精度(AP)和召回率90%时的精确率(P@R=0.9)。
背景与挑战
背景概述
PhreshPhish数据集由OpenText公司于2025年创建,旨在解决网络钓鱼检测领域高质量数据集的稀缺问题。该数据集包含约37.2万个网页样本,其中11.9万个为钓鱼网站,25.3万个为良性网站,是目前已知规模最大、质量最高的公开钓鱼网站数据集。数据集通过多源采集(如PhishTank、APWG eCrime eXchange)和严格的清洗流程(包括自动化启发式规则与人工标注结合),显著降低了现有数据集中常见的标签错误和数据泄漏问题。其核心研究价值在于为实时钓鱼检测模型提供了真实场景下的基准测试环境,并通过调整基准率(0.05%-5%)模拟实际部署条件,对提升网络安全防御系统的泛化能力具有重要推动作用。
当前挑战
该数据集主要应对两大挑战:领域层面,钓鱼网站具有高度动态性(平均存活时间仅数小时)、对抗性(如IP屏蔽、验证码等反爬技术)和隐蔽性(内容混淆、快速域名切换等),传统检测方法面临特征提取困难与泛化不足的问题;构建层面,数据采集需克服动态页面渲染(React/Angular框架)、地理屏蔽、托管服务拦截等技术障碍,清洗过程需处理42%的初始数据失效(如404错误、Cloudflare反爬页面)。此外,基准数据集设计需平衡任务难度(通过分类置信度筛选10%‘简单样本’)与多样性(LSH哈希去重),避免模型评估时的乐观偏差。
常用场景
经典使用场景
在网络安全领域,PhreshPhish数据集为钓鱼网站检测研究提供了高质量、大规模的真实数据支持。该数据集通过整合来自多个权威钓鱼网站报告源的数据,并结合自动化与人工清洗流程,确保了数据的准确性和时效性。研究者可利用其进行钓鱼网站分类模型的训练与评估,尤其适用于实时检测场景,如浏览器插件或网络安全防护系统的开发。
解决学术问题
PhreshPhish解决了钓鱼检测研究中长期存在的两大问题:数据质量不足与基准测试不现实。传统数据集常因标注错误、样本泄漏或高估的基准率导致模型性能虚高。该数据集通过严格的清洗流程(如去重、相似性过滤)和分层基准设计(0.05%-5%基准率),为学术界提供了更贴近真实网络环境的评估标准,推动了检测算法在低误报率、低延迟等关键指标上的进步。
衍生相关工作
PhreshPhish催生了多项创新研究:1) 基于BERT的端到端检测模型(如GTE-large)在基准测试中展现最优性能;2) 衍生出多模态检测框架PhishAgent,结合HTML结构与视觉特征;3) 推动零样本LLM检测技术发展,如ChatPhishDetector利用大语言模型分析网页语义。这些工作均引用该数据集作为核心评估标准,形成了钓鱼检测领域的新方法论体系。
以上内容由遇见数据集搜集并总结生成


