GazeVaLM
收藏arXiv2026-04-14 更新2026-04-15 收录
下载链接:
https://huggingface.co/datasets/davidcwong/GazeVaLM
下载链接
链接失效反馈官方服务:
资源简介:
GazeVaLM是由西北大学团队构建的首个多观察者眼动追踪基准数据集,旨在评估AI生成胸片的临床真实性。该数据集包含16位放射科专家对30张真实和30张合成胸片的960条眼动记录,涵盖原始凝视样本、注视热图、扫描路径等丰富标注。数据通过严格四阶段流程生成,包括基于RoentGen扩散模型的合成图像生成、眼动实验设计、数据处理及多模态大模型评估。该数据集为医学图像感知研究提供了独特资源,可支持临床决策分析、人机交互比较以及生成图像真实性评估等前沿领域。
GazeVaLM is the first multi-observer eye-tracking benchmark dataset developed by a team from Northwestern University, designed to evaluate the clinical authenticity of AI-generated chest radiographs. This dataset contains 960 eye-tracking records from 16 radiologists who reviewed 30 real and 30 synthetic chest radiographs, with rich annotations covering raw gaze samples, fixation heatmaps, scanpaths, and more. The dataset is generated through a rigorous four-stage workflow, including synthetic image generation based on the RoentGen diffusion model, eye-tracking experiment design, data processing, and multimodal large model evaluation. This dataset provides a unique resource for medical image perception research, supporting cutting-edge areas such as clinical decision analysis, human-computer interaction comparison, and authenticity assessment of generated images.
提供机构:
西北大学; 巴黎第十三大学; 芝加哥洛约拉大学; 杜佩奇医疗集团; 埃默里大学
创建时间:
2026-04-14
原始信息汇总
GazeVaLM 数据集概述
数据集基本信息
- 数据集名称: GazeVaLM
- 存储库地址: https://huggingface.co/datasets/davidcwong/GazeVaLM
- 数据内容: 包含针对60张X光刺激图像(涵盖真实与AI生成图像)的凝视分析结果、专家评估数据以及大型语言模型(LLM)的输出数据。
数据文件结构与内容
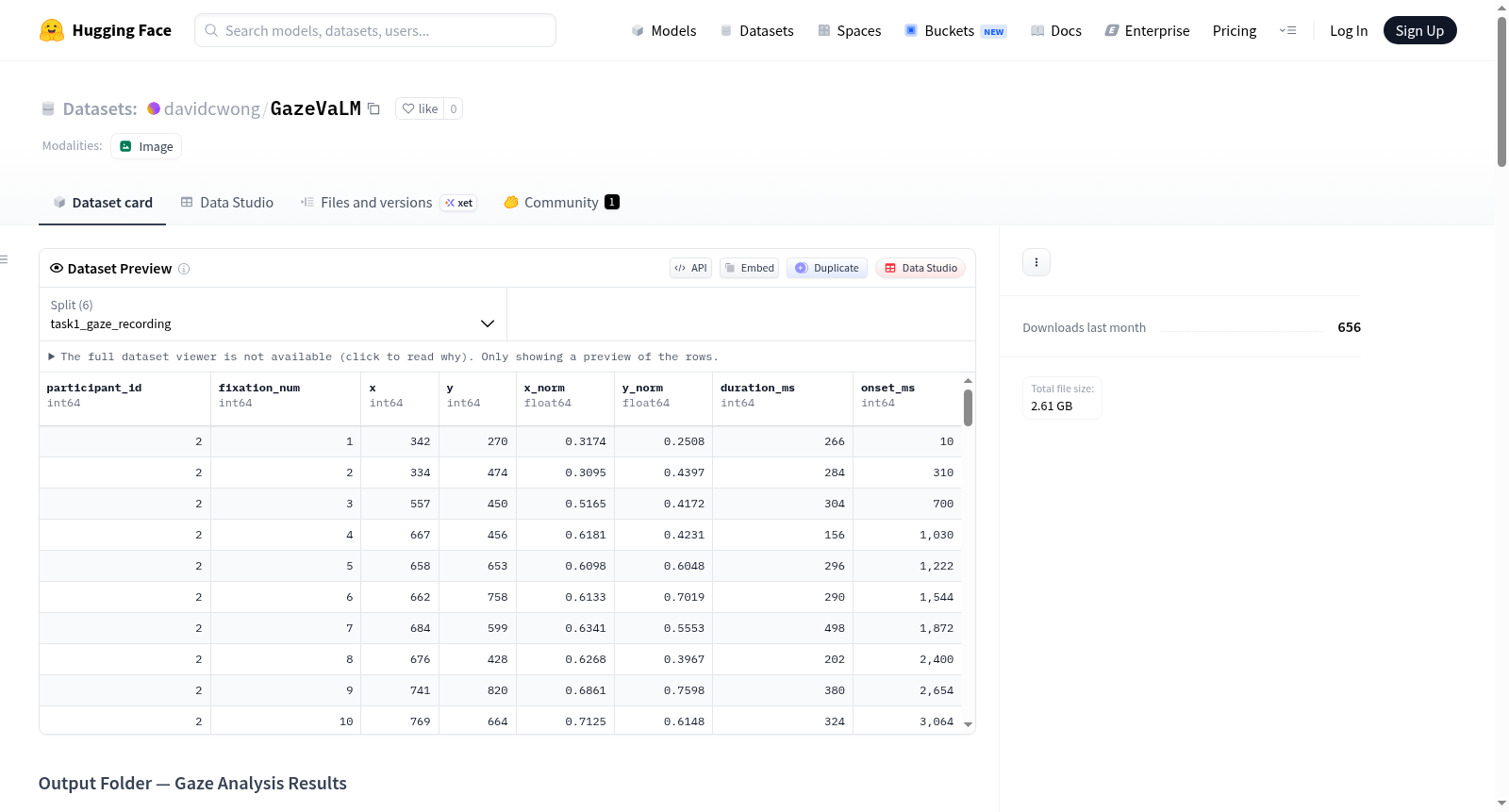
1. 凝视分析结果 (Task1/ 与 Task2/)
每个任务目录下包含以下数据:
- 专家结果文件:
expert_results.csv- 列信息:
File Name: X光图像的文件名。- 所有编号列: 以观察者ID命名的列标题。
- 列信息:
- 每张图像的子文件夹 (例如
real_s55758034/,fake_s57321224/): 每个子文件夹包含7个文件:density_map.npy: 1080×1080 float32数组,所有观察者聚合的时长加权高斯热图,归一化至[0, 1]。density_map.png: 叠加在X光片上的相同热图(jet配色,白色背景)。density_map_black.png: 纯黑背景上的相同热图。fixation_map.npy: 1080×1080 float32数组,每像素原始注视点计数(无平滑处理)。fixation_map.png: 叠加在X光片上的注视点计数图(hot配色)。scanpaths.csv: 每位观察者的注视点表格。- 列信息:
participant_id: 观察者ID。fixation_num: 试验内的注视点顺序(从1开始)。x,y: 图像像素空间中的注视点位置(0–1079)。x_norm,y_norm: 相对于1080×1080图像的归一化位置(0–1)。duration_ms: 注视点持续时间(毫秒)。onset_ms: 从图像出现开始的注视点起始时间(毫秒)。
- 列信息:
scanpath_overlay.png: 绘制在X光片上的所有观察者扫描路径,每条路径使用不同颜色(最多16位观察者,无图例)。
2. 网格汇总图 (Grids/)
包含9张汇总图(200 DPI,白色背景),按诊断类别(正常、肺不张、肺炎、心脏肥大、胸腔积液)组织:
grid_Task1_real_density.png: 任务1 · 真实X光片 · 显著性叠加图。grid_Task1_real_scanpath.png: 任务1 · 真实X光片 · 扫描路径叠加图。grid_Task1_fake_density.png: 任务1 · AI生成图像 · 显著性叠加图。grid_Task1_fake_scanpath.png: 任务1 · AI生成图像 · 扫描路径叠加图。grid_Task2_real_density.png: 任务2 · 真实X光片 · 显著性叠加图。grid_Task2_real_scanpath.png: 任务2 · 真实X光片 · 扫描路径叠加图。grid_Task2_fake_density.png: 任务2 · AI生成图像 · 显著性叠加图。grid_Task2_fake_scanpath.png: 任务2 · AI生成图像 · 扫描路径叠加图。grid_combined.png: 单一复合图 — 涵盖所有8种组合的每个类别示例。
3. 大型语言模型数据 (LLM/)
包含5个CSV文件:
- 基准真值文件:
ground_truth.csv- 列信息:
ShuffledImageIndex: 图像在实验中出现的序列位置。RealImgName: X光图像的文件名。Real_Generated: 根据图像是真实或生成,取值为Real或Generated。
- 列信息:
- 已解析数据文件:
Task1_parsed.csv与Task2_parsed.csv- 列信息:
ShuffledImageIndex: 根据ground_truth.csv的图像索引号。LLM: 大型语言模型的名称。task: 分配给LLM的任务。findings: LLM发现的数组。impression: LLM撰写的印象。confidence: LLM对其回答的信心度(1到4分)。findings_text: LLM的发现结果字符串。
- 列信息:
- 未解析数据文件:
Task1_unparsed.csv与Task2_unparsed.csv- 列信息:
ShuffledImageIndex: 根据ground_truth.csv的图像索引号。LLM: 大型语言模型的名称。JSON: 来自LLM的原始JSON响应。
- 列信息:
数据配置
数据集的Hugging Face配置 (sample) 定义了以下数据文件分割:
task1_gaze_recording:Task1/fake_s58630288/scanpaths.csvtask2_gaze_recording:Task2/fake_s58630288/scanpaths.csvTask1_expert:Task1/expert_results.csvTask2_expert:Task2/expert_results.csvllm_task1:LLM/Task1_parsed.csvllm_task2:LLM/Task2_parsed.csv
搜集汇总
数据集介绍
构建方式
在医学影像合成技术迅速发展的背景下,GazeVaLM数据集的构建采用了严谨的四阶段流程。首先,基于MIMIC-CXR中的放射学报告,利用RoentGen视觉语言扩散模型生成了30张合成胸部X光片,并与30张真实影像配对,确保内容一致性。随后,16位经验丰富的放射科专家在两种实验条件下解读这些影像:诊断评估任务与视觉图灵测试任务,使用EyeLink 1000 Plus眼动仪记录了960条原始凝视数据。最后,通过速度色散算法处理原始数据,生成了注视点序列、热图、扫描路径等多种凝视表征,并将相同实验协议扩展至六种先进的多模态大语言模型,形成了全面的人机对比基准。
使用方法
GazeVaLM数据集支持多个前沿研究方向的应用。在凝视建模领域,研究者可利用原始注视样本、扫描路径和显著性密度图,分析专家在不同任务下的视觉搜索策略与认知过程。对于临床决策与生成影像评估,数据集中的诊断标签和真实性判断可用于训练或验证模型,探究合成影像中影响临床可信度的细微伪影。在人机比较研究中,通过对比放射科专家与大语言模型的决策准确性、置信度及潜在的凝视模式差异,能够深入评估当前人工智能系统在医学图像解读中的局限性与可靠性。数据集已公开于Hugging Face平台,便于社区进行可复现的实验与分析。
背景与挑战
背景概述
随着生成式人工智能在医学影像领域的快速发展,合成图像在解决数据稀缺和隐私问题方面展现出巨大潜力。然而,现有评估方法主要依赖计算指标,难以捕捉临床医生对图像真实性的感知差异。为弥合这一鸿沟,由西北大学等机构的研究团队于2026年创建的GazeVaLM数据集应运而生。该数据集通过眼动追踪技术,记录了16位放射科专家在诊断评估和视觉图灵测试任务中对真实与合成胸部X光片的视觉注意模式,核心研究问题在于量化生成图像的临床真实性,并建立人类与多模态大语言模型在医学图像感知上的可比性基准。GazeVaLM的发布为医学图像生成、人机交互及临床决策研究提供了关键数据支撑,推动了合成医学图像评估从计算相似性向临床感知效度的范式转变。
当前挑战
GazeVaLM数据集旨在解决生成式医学图像临床真实性评估的挑战,其核心问题在于如何超越传统计算指标,直接量化专家对合成图像的感知真实性。构建过程中面临多重挑战:首先,在数据采集阶段,需设计严谨的双任务实验范式,确保专家在自然诊断和真实性判断中的眼动行为不受任务顺序干扰,同时维持图像对的可比性;其次,合成图像的生成依赖于特定扩散模型,其泛化能力受到模态、视角和生成架构的限制,影响了数据集的扩展性。此外,协调多位放射科专家参与大规模眼动实验,并处理个体差异与专业背景的多样性,对数据的一致性与标准化提出了较高要求。这些挑战共同指向了合成医学图像评估中临床感知与计算生成之间的深层鸿沟。
常用场景
经典使用场景
在医学影像生成人工智能的评估领域,GazeVaLM数据集提供了一个独特的基准,用于分析专家放射科医师在解读真实与合成胸部X光片时的视觉注意模式。该数据集通过记录16位专家在诊断评估和视觉图灵测试两种任务下的眼动数据,揭示了临床医生在识别图像真实性时的认知策略差异。这一场景不仅深化了对合成医学图像临床可信度的理解,还为构建更符合人类感知的生成模型评估体系奠定了实证基础。
解决学术问题
GazeVaLM数据集主要解决了生成医学图像评估中计算指标与临床感知之间的脱节问题。传统方法如FID和IS仅衡量分布相似性,无法捕捉细微的临床不真实特征。该数据集通过眼动数据与诊断标签的结合,为量化图像真实性提供了基于人类专家视觉行为的客观依据。其意义在于推动了生成模型评估从纯计算向人机协同的范式转变,促进了医疗人工智能在可靠性和安全性方面的研究进展。
实际应用
在实际医疗人工智能开发中,GazeVaLM数据集可用于优化合成数据生成流程,确保生成的医学图像不仅视觉逼真,更能通过临床专家的感知检验。例如,在数据增强或隐私保护场景下,利用该数据集的眼动模式可以指导生成模型避免产生误导性伪影。此外,它还能辅助培训放射科医师识别合成图像的特征,提升医疗诊断系统中人机协作的效率和信任度。
数据集最近研究
最新研究方向
在医学影像与人工智能交叉领域,GazeVaLM数据集正推动对生成式AI合成X射线临床真实性的前沿评估研究。该数据集通过整合多观察者眼动追踪与视觉图灵测试,为探索专家与多模态大语言模型在影像解读与真实性判别中的认知对齐提供了独特基准。当前研究热点集中于利用眼动数据建模临床决策过程,揭示合成图像中细微伪影如何影响专家视觉注意模式,并量化人类与AI在不确定性表达上的差异。这一工作不仅促进了生成式医学图像的质量控制从计算指标向临床感知的转变,也为开发更可靠、可解释的医疗AI系统奠定了实证基础,对推动合成数据在医疗领域的负责任应用具有深远意义。
相关研究论文
- 1GazeVaLM: A Multi-Observer Eye-Tracking Benchmark for Evaluating Clinical Realism in AI-Generated X-Rays西北大学; 巴黎第十三大学; 芝加哥洛约拉大学; 杜佩奇医疗集团; 埃默里大学 · 2026年
以上内容由遇见数据集搜集并总结生成


