SECVULEVAL
收藏arXiv2025-05-26 更新2025-05-28 收录
下载链接:
https://huggingface.co/datasets/arag0rn/SecVulEval
下载链接
链接失效反馈官方服务:
资源简介:
SECVULEVAL是一个综合性的基准数据集,旨在支持LLMs和其他检测方法在具有丰富上下文信息的情况下进行细粒度的评估。该数据集专注于现实世界中的C/C++漏洞,并在语句级别进行评估,从而能够更精确地评估模型定位和理解漏洞的能力。SECVULEVAL包含了从1999年到2024年的C/C++项目中25,440个函数样本,涵盖了5,867个唯一的CVE。数据集通过引入丰富的上下文信息,为在现实软件开发场景中进行漏洞检测的基准测试设定了新的标准。
SECVULEVAL is a comprehensive benchmark dataset designed to support fine-grained evaluation of large language models (LLMs) and other detection methods in scenarios with rich contextual information. This dataset focuses on real-world C/C++ vulnerabilities and conducts evaluations at the statement level, enabling more precise assessment of models' ability to locate and understand vulnerabilities. SECVULEVAL contains 25,440 function samples sourced from C/C++ projects spanning from 1999 to 2024, covering 5,867 unique CVEs. By introducing rich contextual information, this dataset sets a new benchmark for vulnerability detection evaluations in real-world software development scenarios.
提供机构:
约克大学
创建时间:
2025-05-26
原始信息汇总
SecVulEval 数据集概述
数据集基本信息
- 许可证: MIT
- 数据来源: 美国国家漏洞数据库(NVD)及各项目Git仓库
- 语言: C/C++
- 数据量:
- 训练集样本数: 25,440个函数
- 训练集大小: 118,488,441字节
- 下载大小: 30,847,988字节
数据集构成
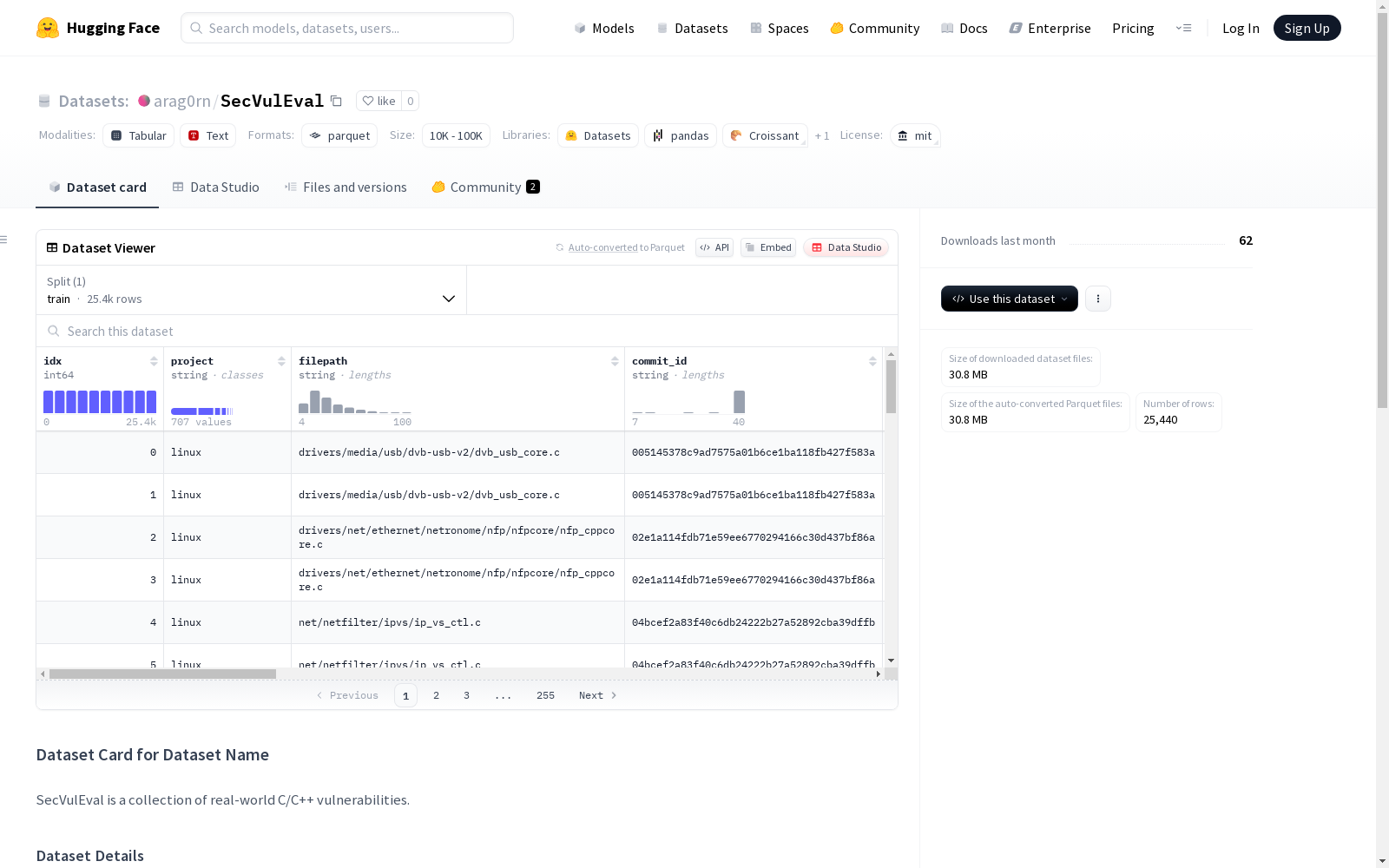
- 特征字段 (共15个):
- 基础信息: idx(索引), project(项目名), filepath(文件路径), commit_id(提交ID), commit_message(提交信息)
- 漏洞特征: is_vulnerable(是否易受攻击), hash(哈希值), func_name(函数名), func_body(函数体)
- 变更信息: changed_lines(变更行), changed_statements(变更语句)
- 安全标识: cve_list(CVE列表), cwe_list(CWE列表)
- 修复关联: fixed_func_idx(修复函数索引)
- 上下文信息: context(包含6个子字段的结构体)
数据特点
-
漏洞分布:
- 易受攻击函数占比: 43.23%
- 非易受攻击函数占比: 56.77%
-
变更记录特征:
- 易受攻击函数记录被删除的代码
- 非易受攻击函数记录新增的代码
-
安全标识:
- 支持多CVE/CWE标注(列表形式存储)
-
修复关联:
- 通过fixed_func_idx字段可关联漏洞函数与其修复版本
主要用途
- 漏洞检测模型训练
- 细粒度上下文感知检测
- C/C++漏洞检测模型评估
数据结构说明
- **上下文信息(context)**包含6类子信息:
- Execution Environment
- Explanation
- External Function
- Function Argument
- Globals
- Type Execution Declaration
搜集汇总
数据集介绍
构建方式
SECVULEVAL数据集的构建采用了系统化的多阶段流程,以确保数据的高质量和全面性。首先,研究人员从国家漏洞数据库(NVD)中筛选出与C/C++项目相关的CVE记录,并通过GitHub REST API收集对应的修复提交信息。随后,通过严格的过滤机制去除非C/C++文件、多提交修复案例以及无关的代码变更,确保数据集的纯净性。此外,利用GPT-4.1自动提取与漏洞相关的上下文信息,包括函数参数、外部函数调用等关键元素,并通过人工验证确保其准确性。最终数据集包含5,867个独特的CVE记录,覆盖了707个开源项目和145种CWE类型,总计25,440个函数样本。
特点
SECVULEVAL数据集的核心特点在于其细粒度的漏洞标注和丰富的上下文信息。与现有数据集不同,它不仅提供函数级别的漏洞标签,还精确到语句级别,能够更准确地反映漏洞的具体位置和成因。此外,数据集还包含了五种关键上下文类别(如函数参数、外部函数调用等),为模型提供了更全面的代码理解依据。数据集的另一个显著优势是其严格的去重机制,确保了样本的唯一性,避免了数据泄漏问题。时间跨度上覆盖1999至2024年的漏洞记录,使其具有显著的历史代表性和现实意义。
使用方法
该数据集主要用于评估大语言模型在C/C++漏洞检测任务中的性能表现。研究人员可采用多智能体框架进行实验,其中规划智能体负责生成分析计划,上下文智能体迭代收集必要的外部符号,检测智能体进行漏洞判定,验证智能体则对结果进行最终确认。评估指标包括精确率、召回率和F1值,特别关注模型在语句级别定位漏洞的能力。数据集还可用于研究上下文信息对漏洞检测的影响,通过对比不同上下文条件下的模型表现,探索代码理解深度与检测准确性的关联。所有实验数据可通过Hugging Face平台获取,便于复现和扩展研究。
背景与挑战
背景概述
SECVULEVAL是由约克大学的研究团队于2025年推出的一个专注于C/C++漏洞检测的基准数据集。该数据集旨在解决现有漏洞检测数据集在细粒度分析和上下文信息方面的不足,通过提供语句级别的漏洞标注和丰富的上下文信息,为大型语言模型(LLMs)和其他检测方法提供了一个更全面的评估平台。SECVULEVAL包含了从1999年至2024年的5,867个独特CVE(Common Vulnerabilities and Exposures)漏洞,覆盖了707个不同的C/C++项目和145种CWE(Common Weakness Enumeration)类型。这一数据集的推出为漏洞检测领域的研究和实践提供了重要的资源,推动了细粒度和上下文感知的漏洞检测技术的发展。
当前挑战
SECVULEVAL面临的挑战主要包括两个方面:领域问题的挑战和构建过程中的挑战。在领域问题方面,现有的漏洞检测数据集通常仅提供函数级别的标签,忽略了细粒度的漏洞模式和关键的上下文信息,导致模型在实际应用中的性能被高估且泛化能力较弱。此外,缺乏完整的程序上下文(如数据/控制依赖和过程间交互)也限制了模型对真实世界安全漏洞的准确理解和检测。在构建过程中,数据质量的问题(如错误标注、不一致的注释和重复数据)以及如何有效提取和整合语句级别的漏洞信息和上下文信息是主要的挑战。SECVULEVAL通过严格的去重和过滤流程,以及利用GPT-4.1自动提取上下文信息,成功应对了这些挑战,为漏洞检测领域树立了新的标准。
常用场景
经典使用场景
在软件工程和安全研究领域,SECVULEVAL数据集为评估大型语言模型(LLMs)在C/C++漏洞检测中的性能提供了标准化的测试平台。该数据集以其细粒度的语句级漏洞标注和丰富的上下文信息,成为研究人员验证模型在真实软件开发场景中定位和理解漏洞能力的首选工具。通过覆盖从1999年至2024年的5,867个独特CVE,SECVULEVAL支持对模型在跨年代、跨项目漏洞检测中的泛化性进行系统性评估。
衍生相关工作
基于SECVULEVAL的衍生研究呈现出多维度发展态势:在模型架构层面,Risse等人提出ContextGNN,首次将图神经网络与数据集中的上下文依赖关系相结合;在评估方法领域,Zhou等开发的VulEvalBench构建了跨数据集迁移学习框架。最具影响力的是MITRE公司发布的CVETransformer,该工作利用SECVULEVAL的语句级标签训练出可解释性强的漏洞定位模型,其成果已被纳入CVE官方评估流程。
数据集最近研究
最新研究方向
在软件工程与网络安全领域,SECVULEVAL数据集的推出标志着C/C++漏洞检测研究迈入细粒度分析的新阶段。该数据集通过提供语句级漏洞标注及丰富的上下文信息,解决了传统基准在代码依赖性、跨过程交互等关键特征上的缺失问题。当前研究热点聚焦于大语言模型(LLMs)在真实场景漏洞检测中的性能边界探索,如多智能体架构对复杂上下文推理能力的提升,以及模型对指针操作、内存边界等底层安全问题的理解深度。2024年的实验表明,即使最优模型Claude3.7-Sonnet的F1-score仅达23.83%,凸显出现有技术在细粒度漏洞定位与根因分析上的显著不足。该数据集进一步推动了漏洞检测从函数级二元分类向具备实际修复指导价值的语句级诊断范式转变,为构建兼顾准确性与解释性的下一代安全工具提供了关键基准。
相关研究论文
- 1SecVulEval: Benchmarking LLMs for Real-World C/C++ Vulnerability Detection约克大学 · 2025年
以上内容由遇见数据集搜集并总结生成


