无人机智能识别垃圾堆放算法模型的图像训练数据
收藏浙江省数据知识产权登记平台2025-05-07 更新2025-05-08 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/127893
下载链接
链接失效反馈官方服务:
资源简介:
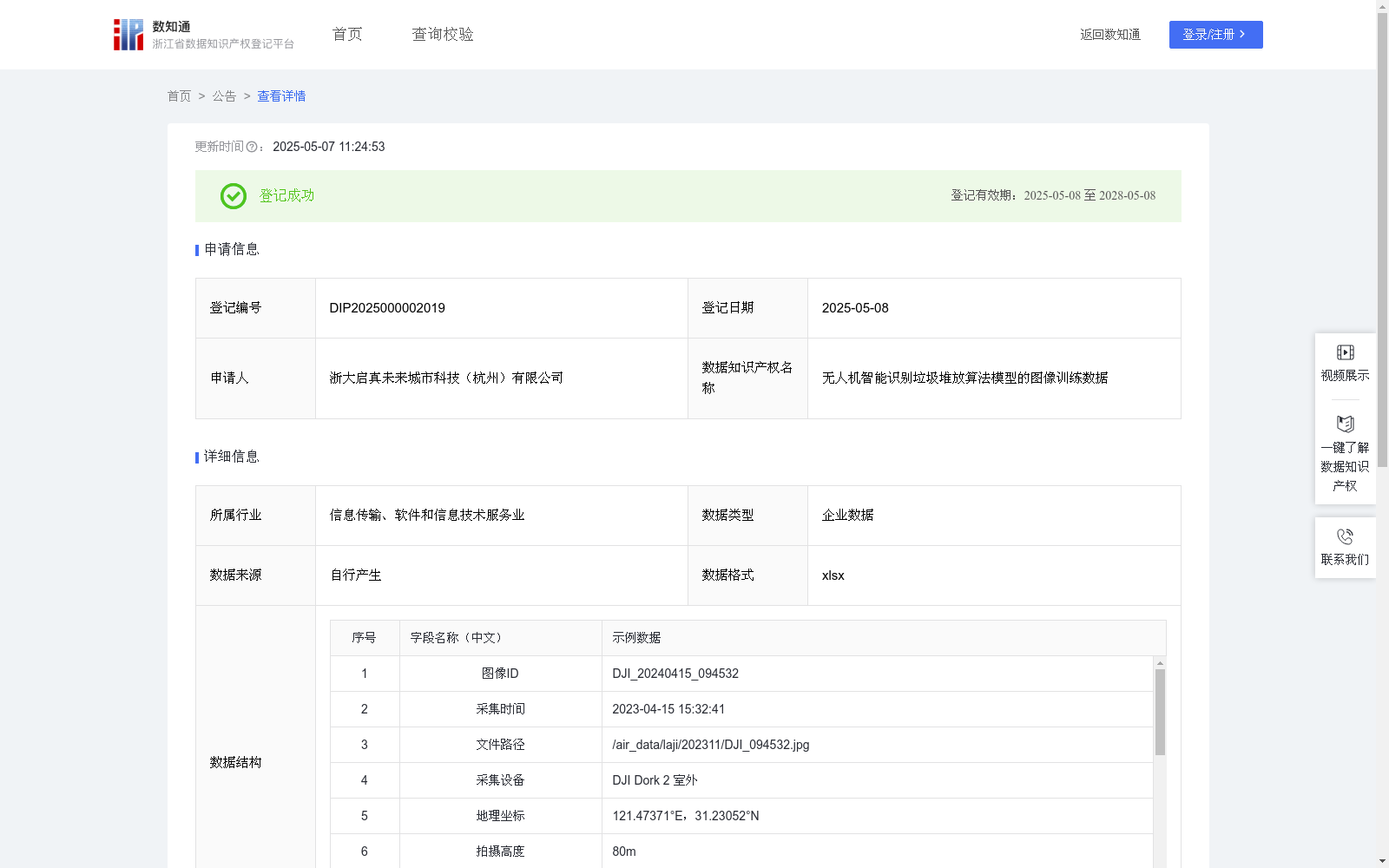
无人机智能识别垃圾堆放算法模型的图像训练数据的应用场景主要集中在提升AI模型对垃圾堆放的识别能力和准确度。通过对这些数据的训练,AI模型能够更有效地支撑无人机在生态环境智能监测中的全域化巡查应用。基于地理坐标与二级标注体系,AI模型可精准识别建筑垃圾、工业废料、生活垃圾等垃圾堆放行为,可应用于支撑环保部门对城乡结合部、河道堤岸、工业园周界等复杂场景的自动化巡检、污染源定位、违法取证及治理效能评估等需求。1、数据来源:原始数据通过自有智能无人机拍摄采集,记录图像ID、采集时间、文件路径、采集设备、地理坐标、拍摄高度、环境参数、边界框组等数据,通过数据清洗,保证数据质量。
2、数据预处理与标注:①对原始数据按7:2:1比例划分训练集/验证集/测试集;②采用多级标注体系:一级标签(垃圾堆放/正常)、二级标签(生活垃圾/建筑垃圾/工业废料等)。③关联要素标注包含垃圾桶容量状态、围栏标识、合法堆放区等关键信息。
3、模型选择和初始化:采用YOLOv5预训练模型,并初始化模型参数,设置合理的超参数:学习率0.002-0.0001动态调整,批量大小16,锚框参数根据拍摄图像特征优化;同时集成注意力机制增强小目标检测能力。
4、模型训练:使用PyTorch框架实施分布式训练,设置训练时长,采用迁移学习策略,冻结底层特征提取层参数,引入Mosaic数据增强提升复杂场景适应能力,设置早停机制(patience=15)防止过拟合。
5、模型评估:① 构建多维评估体系:基础指标(mAP@0.5)、夜间检测率、误报率、漏报率。② 设置渐进式测试:单类堆放→混合堆放→伪装堆放→跨季节场景四阶段测试。
6、模型优化:优化推理引擎,保障推理速度,并建立区域特征库机制。
The application scenarios of the image training data for the UAV-based intelligent waste stacking recognition algorithm model mainly focus on improving the AI model's recognition capability and accuracy for waste stacking. Trained with this dataset, the AI model can more effectively support the full-coverage patrol applications of UAVs in intelligent ecological environment monitoring. Based on geographic coordinates and the two-level annotation system, the AI model can accurately identify waste stacking behaviors such as construction waste, industrial waste, and domestic waste, and can be applied to support the needs of environmental protection departments for automated inspection, pollution source localization, illegal evidence collection, and governance effectiveness evaluation in complex scenarios such as urban-rural fringe areas, river banks, and industrial park perimeters.
1. Data Source: The original data is collected by self-developed intelligent UAVs, including image ID, collection time, file path, collection equipment, geographic coordinates, shooting altitude, environmental parameters, bounding box groups and other related data. Data cleaning is carried out to ensure data quality.
2. Data Preprocessing and Annotation:
① Divide the original data into training set/validation set/test set at a ratio of 7:2:1;
② Adopt a multi-level annotation system: first-level labels (waste stacking/normal), second-level labels (domestic waste/construction waste/industrial waste, etc.);
③ Associated element annotations include key information such as trash bin capacity status, fence signs, and legal stacking areas.
3. Model Selection and Initialization: Adopt the pre-trained YOLOv5 model, initialize the model parameters, and set reasonable hyperparameters: dynamically adjust the learning rate from 0.002 to 0.0001, set the batch size to 16, optimize the anchor box parameters based on the characteristics of the captured images; meanwhile integrate the attention mechanism to enhance the small target detection capability.
4. Model Training: Implement distributed training using the PyTorch framework, set the training duration, adopt the transfer learning strategy, freeze the parameters of the underlying feature extraction layers, introduce Mosaic data augmentation to improve the adaptability to complex scenarios, and set the early stopping mechanism (patience=15) to prevent overfitting.
5. Model Evaluation:
① Construct a multi-dimensional evaluation system: basic metrics (mAP@0.5), nighttime detection rate, false positive rate, and false negative rate.
② Set up progressive testing: four-stage tests including single-category stacking → mixed stacking → camouflaged stacking → cross-season scenarios.
6. Model Optimization: Optimize the inference engine to ensure inference speed, and establish a regional feature database mechanism.
提供机构:
浙大启真未来城市科技(杭州)有限公司
创建时间:
2025-04-07
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是用于无人机智能识别垃圾堆放算法模型的图像训练数据,包含684条记录,每日更新。数据涵盖多维信息,如地理坐标、环境参数和标签,旨在提升AI模型对垃圾堆放的识别能力,支持环保部门的自动化巡检和污染源定位。
以上内容由遇见数据集搜集并总结生成


