dwb2023/filtered-coyo-700M-beta
收藏Hugging Face2024-05-26 更新2024-06-12 收录
下载链接:
https://hf-mirror.com/datasets/dwb2023/filtered-coyo-700M-beta
下载链接
链接失效反馈资源简介:
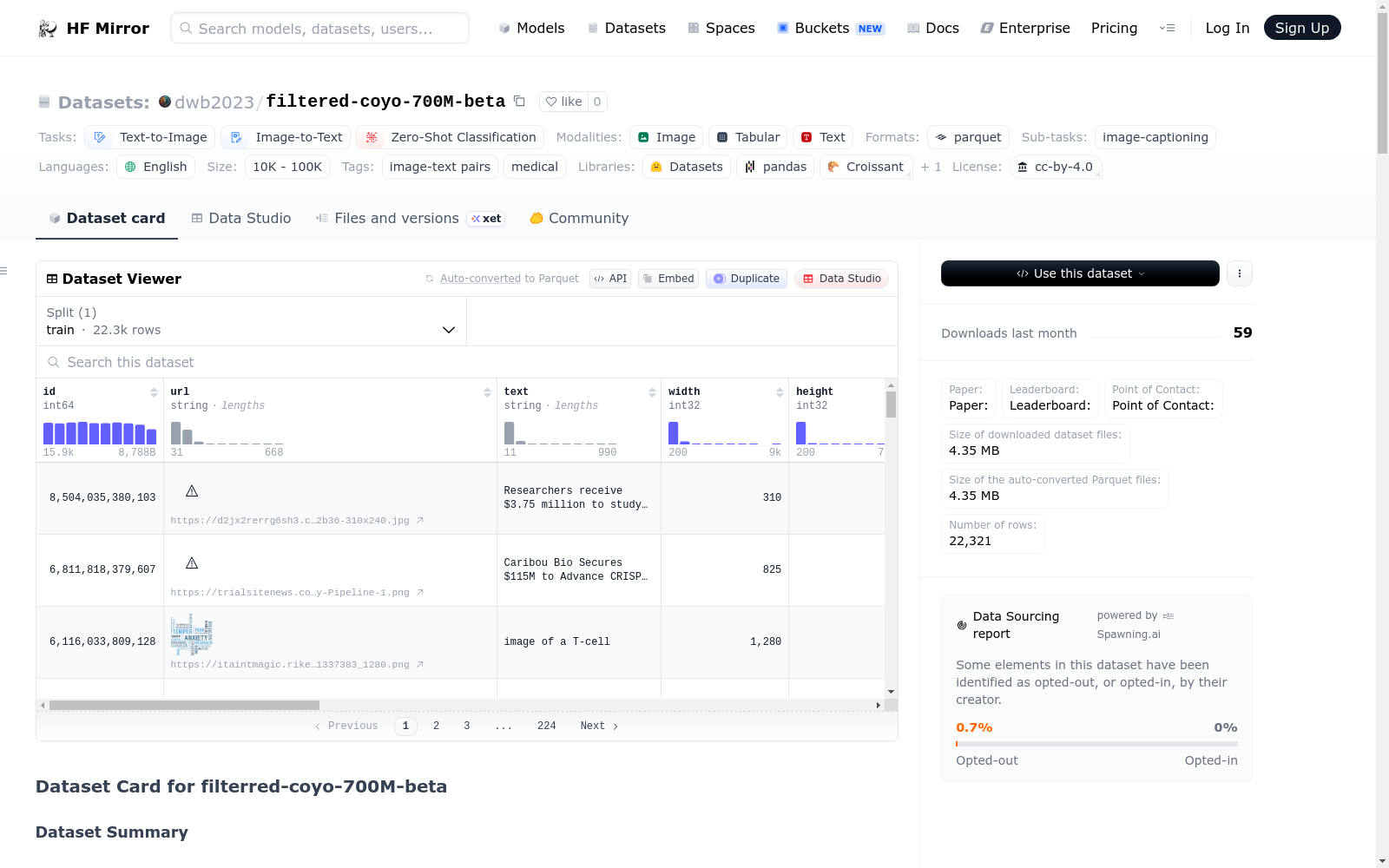
COYO-700M数据集是一个包含约700M图像-文本对的大规模数据集,主要用于图像到文本、文本到图像以及零样本分类等任务。数据集从Common Crawl中收集了约10亿对图像和文本数据,经过多层次的过滤和清理,最终形成700M的数据集。每个数据实例包含图像URL、文本描述、图像尺寸、图像的感知哈希值、文本长度、词数、BERT和GPT的token数、图像中的人脸数、CLIP模型的相似度评分、NSFW评分、水印评分以及美学评分等元属性。数据集未进行分割,因为预期评估将在更广泛使用的下游任务上进行。数据集的使用受CC-BY-4.0许可约束。
COYO-700M数据集是一个包含约700M图像-文本对的大规模数据集,主要用于图像到文本、文本到图像以及零样本分类等任务。数据集从Common Crawl中收集了约10亿对图像和文本数据,经过多层次的过滤和清理,最终形成700M的数据集。每个数据实例包含图像URL、文本描述、图像尺寸、图像的感知哈希值、文本长度、词数、BERT和GPT的token数、图像中的人脸数、CLIP模型的相似度评分、NSFW评分、水印评分以及美学评分等元属性。数据集未进行分割,因为预期评估将在更广泛使用的下游任务上进行。数据集的使用受CC-BY-4.0许可约束。
提供机构:
dwb2023
原始信息汇总
数据集概述
数据集名称
- pretty_name: filterred-coyo-700m-beta
语言
- 语言: 英语
- 语言创建者: 其他
许可证
- 许可证: CC-BY-4.0
多语言性
- 多语言性: 单语种
大小分类
- 大小分类: 100M<n<1B
来源数据集
- 来源数据集: 原始数据
标签
- 标签: 图像-文本对, 医学
任务类别
- 任务类别: 文本到图像, 图像到文本, 零样本分类
任务ID
- 任务ID: 图像字幕生成
数据集结构
数据实例
-
描述: 每个实例代表单一的图像-文本对信息,包含多个元属性。
-
示例:
{ id: 841814333321, url: https://blog.dogsof.com/wp-content/uploads/2021/03/Image-from-iOS-5-e1614711641382.jpg, text: A Pomsky dog sitting and smiling in field of orange flowers, ... }
数据字段
- 字段列表:
名称 类型 描述 id long 唯一64位整数ID url string 图像URL text string 文本 width integer 图像宽度 height integer 图像高度 image_phash string 图像的感知哈希值 ... ... ...
数据分割
- 描述: 数据未分割,评估预期在更广泛使用的下游任务上进行。
数据集创建
来源数据
- 初始数据收集和规范化:
- 从Common Crawl收集约10亿对alt-text和图像源。
- 通过图像和/或文本级过滤过程消除无信息对。
注释
- 注释过程: 完全自动化,无需人工注释。
- 注释者: 无人工注释。
个人和敏感信息
- 免责声明与内容警告: 未提供具体信息。
许可证信息
- 许可证: CC-BY-4.0
- 使用义务: 使用时需遵守许可证指南,违规可能面临法律行动。
引用信息
-
引用格式:
@misc{kakaobrain2022coyo-700m, title = {COYO-700M: Image-Text Pair Dataset}, author = {Minwoo Byeon, Beomhee Park, Haecheon Kim, Sungjun Lee, Woonhyuk Baek, Saehoon Kim}, year = {2022}, howpublished = {url{https://github.com/kakaobrain/coyo-dataset}}, }
AI搜集汇总
数据集介绍
背景与挑战
背景概述
dwb2023/filtered-coyo-700M-beta是一个医学相关的图像-文本对数据集,包含22,321行数据,主要用于文本到图像和图像到文本任务。数据集通过自动化流程从Common Crawl收集,具有多个元属性,并遵循CC-BY-4.0许可。
以上内容由AI搜集并总结生成


